Comparar commits
202 Commits
| Autor | SHA1 | Data | |
|---|---|---|---|
|
|
bdd70d06d3 | ||
|
|
39a3be60c0 | ||
|
|
d81e4127fb | ||
|
|
122be6e30b | ||
|
|
8056f0dd37 | ||
|
|
3a61ace619 | ||
|
|
8661e78f08 | ||
|
|
90aafca585 | ||
|
|
d2ce350657 | ||
|
|
d4fce4f5f1 | ||
|
|
5e301d1f63 | ||
|
|
4e5348c5ca | ||
|
|
a19db7b672 | ||
|
|
85ebccfcc8 | ||
|
|
677e9ee8ba | ||
|
|
0f4c7864ba | ||
|
|
63c099714b | ||
|
|
3dd27c61fb | ||
|
|
6543b67509 | ||
|
|
d0b348a55a | ||
|
|
9f8d3cb399 | ||
|
|
deb4c06df8 | ||
|
|
d3cc1de2d7 | ||
|
|
404a30df88 | ||
|
|
3bd7d11170 | ||
|
|
9ac50e0050 | ||
|
|
b0303f03ff | ||
|
|
2716dcd6ab | ||
|
|
fef9de0d17 | ||
|
|
2dcafafcf9 | ||
|
|
775664fdb8 | ||
|
|
a67034ee7c | ||
|
|
e72bb9506a | ||
|
|
ecd414d716 | ||
|
|
80a831de1a | ||
|
|
37fd456a5c | ||
|
|
0c1af0901d | ||
|
|
70431a5336 | ||
|
|
cf3ab771d3 | ||
|
|
524090e600 | ||
|
|
9c9318ff6b | ||
|
|
f75f70a60d | ||
|
|
e3c31aa762 | ||
|
|
ef1e959505 | ||
|
|
c5b8a1df80 | ||
|
|
e73cf505a7 | ||
|
|
8606edf3bf | ||
|
|
71d46b7153 | ||
|
|
7f3b2067bc | ||
|
|
ed882f4064 | ||
|
|
126b820561 | ||
|
|
b50624debd | ||
|
|
709390dfdb | ||
|
|
56c492cbcc | ||
|
|
bde45eff87 | ||
|
|
ce7276bc55 | ||
|
|
fc476840fa | ||
|
|
cfcb1e8703 | ||
|
|
8ba647c196 | ||
|
|
a86057d91c | ||
|
|
1ebeff8ee3 | ||
|
|
be4a86f6dc | ||
|
|
e5ccf53531 | ||
|
|
ef93e2cffd | ||
|
|
b8c59acd77 | ||
|
|
3cc242615d | ||
|
|
6596cc79d6 | ||
|
|
cd28c6d07e | ||
|
|
b883761820 | ||
|
|
b2b04b0fff | ||
|
|
9e2628e811 | ||
|
|
537fb1cc01 | ||
|
|
99891c0cc8 | ||
|
|
d748db43ae | ||
|
|
4ec84541e3 | ||
|
|
ca05efc76f | ||
|
|
7768ae04a2 | ||
|
|
0daec53acb | ||
|
|
d9ca798c60 | ||
|
|
990ef92a60 | ||
|
|
becc5f3a2c | ||
|
|
e5d0dc65e0 | ||
|
|
48ce23086b | ||
|
|
a3c9d2d7c9 | ||
|
|
9efe17aeea | ||
|
|
763a2a9536 | ||
|
|
4a43567cea | ||
|
|
be24159959 | ||
|
|
943d2d4cf8 | ||
|
|
c4361d2246 | ||
|
|
80927fa958 | ||
|
|
f3f19146f9 | ||
|
|
3799660504 | ||
|
|
9b4f973d57 | ||
|
|
567fdccd0b | ||
|
|
cf755a9c7c | ||
|
|
ff2f8ac69b | ||
|
|
428f4bfde6 | ||
|
|
7552f2c26d | ||
|
|
0eea5f8867 | ||
|
|
47c67ac19a | ||
|
|
55d9374961 | ||
|
|
045e47174f | ||
|
|
22c091ae3f | ||
|
|
d20fe64a69 | ||
|
|
c6c150b042 | ||
|
|
ababd95210 | ||
|
|
ff676f10f6 | ||
|
|
73e563ecaf | ||
|
|
3f905e4a35 | ||
|
|
98e2789db9 | ||
|
|
8a6cf4c13e | ||
|
|
f4af11c730 | ||
|
|
9f2aa1b6ae | ||
|
|
abca83373d | ||
|
|
3aa807a0c8 | ||
|
|
089fa11752 | ||
|
|
06a1545645 | ||
|
|
461573a8d9 | ||
|
|
db8f43128b | ||
|
|
80ddb5b3b8 | ||
|
|
3ffba42466 | ||
|
|
2c49115cd3 | ||
|
|
bbaa66c530 | ||
|
|
784d81d2c8 | ||
|
|
523e9845d7 | ||
|
|
47bd0af702 | ||
|
|
82d3489764 | ||
|
|
44d558ad7f | ||
|
|
cbd11315b7 | ||
|
|
1588998ee8 | ||
|
|
58ca064f93 | ||
|
|
3ecf201aea | ||
|
|
654404c2ed | ||
|
|
7896ef7143 | ||
|
|
0c75006d12 | ||
|
|
c7f7ffe7c4 | ||
|
|
f10c430731 | ||
|
|
ea5cb74414 | ||
|
|
606a9b6810 | ||
|
|
35c5fa911d | ||
|
|
d4e9696447 | ||
|
|
4cff0623de | ||
|
|
bc82613eae | ||
|
|
0ec57f28bc | ||
|
|
860e4e9177 | ||
|
|
a2fdc32381 | ||
|
|
d1a3842b3d | ||
|
|
5406bd3ad2 | ||
|
|
941c3f6ae8 | ||
|
|
bec2701214 | ||
|
|
bc60832dcf | ||
|
|
96483326d8 | ||
|
|
fed7cc257e | ||
|
|
d03f7768b8 | ||
|
|
ce79e0a8ef | ||
|
|
5b3809394c | ||
|
|
e501cd664e | ||
|
|
47aafaaca0 | ||
|
|
b8a9f84fad | ||
|
|
0f3f56327b | ||
|
|
a154495a2a | ||
|
|
25e5f7531a | ||
|
|
ab179fab89 | ||
|
|
59a714abe8 | ||
|
|
e432d10be5 | ||
|
|
eeb576b12f | ||
|
|
1019e50e7f | ||
|
|
1a6cb71732 | ||
|
|
9048b5cbba | ||
|
|
c9642571c2 | ||
|
|
cda80c790b | ||
|
|
46a5b3cb36 | ||
|
|
5b23dd8a2f | ||
|
|
2b26389188 | ||
|
|
44e0a7bbf9 | ||
|
|
87cc39d99f | ||
|
|
55aacd1905 | ||
|
|
3df101cc77 | ||
|
|
c23579e059 | ||
|
|
6a41ac1c36 | ||
|
|
b78ade7e36 | ||
|
|
61800be9a0 | ||
|
|
3925eabaaf | ||
|
|
34296ec961 | ||
|
|
52f48e1f46 | ||
|
|
20728c95fa | ||
|
|
6181ca8aae | ||
|
|
68115cc25f | ||
|
|
c192beaf43 | ||
|
|
27dd1e939c | ||
|
|
1e46a5d3ec | ||
|
|
0bf2b1b075 | ||
|
|
ab3ef3efe5 | ||
|
|
4d3ee897da | ||
|
|
8e591d228c | ||
|
|
6429a57a3c | ||
|
|
9ad5ed8103 | ||
|
|
209b42c5ee | ||
|
|
23147de72b | ||
|
|
7b72163073 | ||
|
|
6279544dc3 |
@@ -0,0 +1,9 @@
|
||||
Please make sure that the boxes below are checked before you submit your issue. Thank you!
|
||||
|
||||
- [ ] Check that you are up-to-date with the master branch of Keras. You can update with:
|
||||
pip install git+git://github.com/fchollet/keras.git --upgrade --no-deps
|
||||
|
||||
- [ ] If running on Theano, check that you are up-to-date with the master branch of Theano. You can update with:
|
||||
pip install git+git://github.com/Theano/Theano.git --upgrade --no-deps
|
||||
|
||||
- [ ] Provide a link to a GitHub Gist of a Python script that can reproduce your issue (or just copy the script here if it is short).
|
||||
+6
-2
@@ -124,19 +124,23 @@ def process_class_docstring(docstring):
|
||||
docstring = re.sub(r' ([^\s\\]+):(.*)\n',
|
||||
r' - __\1__:\2\n',
|
||||
docstring)
|
||||
|
||||
docstring = docstring.replace(' ' * 5, '\t\t')
|
||||
docstring = docstring.replace(' ' * 3, '\t')
|
||||
docstring = docstring.replace(' ', '')
|
||||
return docstring
|
||||
|
||||
|
||||
def process_method_docstring(docstring):
|
||||
docstring = re.sub(r' # (.*)\n',
|
||||
r' __\1__\n\n',
|
||||
docstring = re.sub(r'\n # (.*)\n',
|
||||
r'\n __\1__\n\n',
|
||||
docstring)
|
||||
|
||||
docstring = re.sub(r' ([^\s\\]+):(.*)\n',
|
||||
r' - __\1__:\2\n',
|
||||
docstring)
|
||||
|
||||
docstring = docstring.replace(' ' * 6, '\t\t')
|
||||
docstring = docstring.replace(' ' * 4, '\t')
|
||||
docstring = docstring.replace(' ', '')
|
||||
return docstring
|
||||
|
||||
externo
+5
-3
@@ -14,11 +14,13 @@ is equivalent to:
|
||||
model.add(Dense(64, activation='tanh'))
|
||||
```
|
||||
|
||||
You can also pass an element-wise Theano function as an activation:
|
||||
You can also pass an element-wise Theano/TensorFlow function as an activation:
|
||||
|
||||
```python
|
||||
from keras import backend as K
|
||||
|
||||
def tanh(x):
|
||||
return theano.tensor.tanh(x)
|
||||
return K.tanh(x)
|
||||
|
||||
model.add(Dense(64, activation=tanh))
|
||||
model.add(Activation(tanh))
|
||||
@@ -36,4 +38,4 @@ model.add(Activation(tanh))
|
||||
|
||||
## On Advanced Activations
|
||||
|
||||
Activations that are more complex than a simple Theano function (eg. learnable activations, configurable activations, etc.) are available as [Advanced Activation layers](layers/advanced_activations.md), and can be found in the module `keras.layers.advanced_activations`. These include PReLU and LeakyReLU.
|
||||
Activations that are more complex than a simple Theano/TensorFlow function (eg. learnable activations, configurable activations, etc.) are available as [Advanced Activation layers](layers/advanced_activations.md), and can be found in the module `keras.layers.advanced_activations`. These include PReLU and LeakyReLU.
|
||||
|
||||
externo
+206
-13
@@ -1,6 +1,18 @@
|
||||
|
||||
Here are a few examples to get you started!
|
||||
|
||||
In the examples folder, you will also find example models for real datasets:
|
||||
|
||||
- CIFAR10 small images classification: Convolutional Neural Network (CNN) with realtime data augmentation
|
||||
- IMDB movie review sentiment classification: LSTM over sequences of words
|
||||
- Reuters newswires topic classification: Multilayer Perceptron (MLP)
|
||||
- MNIST handwritten digits classification: MLP & CNN
|
||||
- Character-level text generation with LSTM
|
||||
|
||||
...and more.
|
||||
|
||||
------------------
|
||||
|
||||
### Multilayer Perceptron (MLP) for multi-class softmax classification:
|
||||
|
||||
```python
|
||||
@@ -32,6 +44,8 @@ model.fit(X_train, y_train,
|
||||
score = model.evaluate(X_test, y_test, batch_size=16)
|
||||
```
|
||||
|
||||
------------------
|
||||
|
||||
### Alternative implementation of a similar MLP:
|
||||
|
||||
```python
|
||||
@@ -45,6 +59,7 @@ model.add(Dense(10, activation='softmax'))
|
||||
model.compile(loss='categorical_crossentropy', optimizer='adadelta')
|
||||
```
|
||||
|
||||
------------------
|
||||
|
||||
### MLP for binary classification:
|
||||
```python
|
||||
@@ -55,13 +70,12 @@ model.add(Dense(64, activation='relu'))
|
||||
model.add(Dropout(0.5))
|
||||
model.add(Dense(1, activation='sigmoid'))
|
||||
|
||||
# "class_mode" defaults to "categorical". For correctly displaying accuracy
|
||||
# in a binary classification problem, it should be set to "binary".
|
||||
model.compile(loss='binary_crossentropy',
|
||||
optimizer='rmsprop',
|
||||
class_mode='binary')
|
||||
optimizer='rmsprop')
|
||||
```
|
||||
|
||||
------------------
|
||||
|
||||
### VGG-like convnet:
|
||||
|
||||
```python
|
||||
@@ -103,6 +117,8 @@ model.fit(X_train, Y_train, batch_size=32, nb_epoch=1)
|
||||
|
||||
```
|
||||
|
||||
------------------
|
||||
|
||||
### Sequence classification with LSTM:
|
||||
|
||||
```python
|
||||
@@ -167,9 +183,10 @@ image_model.add(RepeatVector(max_caption_len))
|
||||
|
||||
# the output of both models will be tensors of shape (samples, max_caption_len, 128).
|
||||
# let's concatenate these 2 vector sequences.
|
||||
model = Merge([image_model, language_model], mode='concat', concat_axis=-1)
|
||||
model = Sequential()
|
||||
model.add(Merge([image_model, language_model], mode='concat', concat_axis=-1))
|
||||
# let's encode this vector sequence into a single vector
|
||||
model.add(GRU(256, 256, return_sequences=False))
|
||||
model.add(GRU(256, return_sequences=False))
|
||||
# which will be used to compute a probability
|
||||
# distribution over what the next word in the caption should be!
|
||||
model.add(Dense(vocab_size))
|
||||
@@ -186,12 +203,188 @@ model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
|
||||
model.fit([images, partial_captions], next_words, batch_size=16, nb_epoch=100)
|
||||
```
|
||||
|
||||
In the examples folder, you will find example models for real datasets:
|
||||
------------------
|
||||
|
||||
- CIFAR10 small images classification: Convolutional Neural Network (CNN) with realtime data augmentation
|
||||
- IMDB movie review sentiment classification: LSTM over sequences of words
|
||||
- Reuters newswires topic classification: Multilayer Perceptron (MLP)
|
||||
- MNIST handwritten digits classification: MLP & CNN
|
||||
- Character-level text generation with LSTM
|
||||
### Stacked LSTM for sequence classification
|
||||
|
||||
...and more.
|
||||
In this model, we stack 3 LSTM layers on top of each other,
|
||||
making the model capable of learning higher-level temporal representations.
|
||||
|
||||
The first two LSTMs return their full output sequences, but the last one only returns
|
||||
the last step in its output sequence, thus dropping the temporal dimension
|
||||
(i.e. converting the input sequence into a single vector).
|
||||
|
||||
<img src="http://keras.io/img/regular_stacked_lstm.png" alt="stacked LSTM" style="width: 300px;"/>
|
||||
|
||||
(N.B.: in Keras, "None" in an input shape indicates a variable dimension. In the graph above, the batch size is "None",
|
||||
meaning that any batch size is allowed for the input data).
|
||||
|
||||
```python
|
||||
from keras.models import Sequential
|
||||
from keras.layers import LSTM, Dense
|
||||
import numpy as np
|
||||
|
||||
data_dim = 16
|
||||
timesteps = 8
|
||||
nb_classes = 10
|
||||
|
||||
# expected input data shape: (batch_size, timesteps, data_dim)
|
||||
model = Sequential()
|
||||
model.add(LSTM(32, return_sequences=True,
|
||||
input_shape=(timesteps, data_dim))) # returns a sequence of vectors of dimension 32
|
||||
model.add(LSTM(32, return_sequences=True)) # returns a sequence of vectors of dimension 32
|
||||
model.add(LSTM(32)) # return a single vector of dimension 32
|
||||
model.add(Dense(10, activation='softmax'))
|
||||
|
||||
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
|
||||
|
||||
# generate dummy training data
|
||||
x_train = np.random.random((1000, timesteps, data_dim))
|
||||
y_train = np.random.random((1000, nb_classes))
|
||||
|
||||
# generate dummy validation data
|
||||
x_val = np.random.random((100, timesteps, data_dim))
|
||||
y_val = np.random.random((100, nb_classes))
|
||||
|
||||
model.fit(x_train, y_train,
|
||||
batch_size=64, nb_epoch=5, show_accuracy=True,
|
||||
validation_data=(x_val, y_val))
|
||||
```
|
||||
|
||||
------------------
|
||||
|
||||
### Same stacked LSTM model, rendered "stateful"
|
||||
|
||||
A stateful recurrent model is one for which the internal states (memories) obtained after processing a batch
|
||||
of samples are reused as initial states for the samples of the next batch. This allows to process longer sequences
|
||||
while keeping computational complexity manageable.
|
||||
|
||||
[You can read more about stateful RNNs in the FAQ.](/faq/#how-can-i-use-stateful-rnns)
|
||||
|
||||
```python
|
||||
from keras.models import Sequential
|
||||
from keras.layers import LSTM, Dense
|
||||
import numpy as np
|
||||
|
||||
data_dim = 16
|
||||
timesteps = 8
|
||||
nb_classes = 10
|
||||
batch_size = 32
|
||||
|
||||
# expected input batch shape: (batch_size, timesteps, data_dim)
|
||||
# note that we have to provide the full batch_input_shape since the network is stateful.
|
||||
# the sample of index i in batch k is the follow-up for the sample i in batch k-1.
|
||||
model = Sequential()
|
||||
model.add(LSTM(32, return_sequences=True, stateful=True,
|
||||
batch_input_shape=(batch_size, timesteps, data_dim)))
|
||||
model.add(LSTM(32, return_sequences=True, stateful=True))
|
||||
model.add(LSTM(32, stateful=True))
|
||||
model.add(Dense(10, activation='softmax'))
|
||||
|
||||
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
|
||||
|
||||
# generate dummy training data
|
||||
x_train = np.random.random((batch_size * 10, timesteps, data_dim))
|
||||
y_train = np.random.random((batch_size * 10, nb_classes))
|
||||
|
||||
# generate dummy validation data
|
||||
x_val = np.random.random((batch_size * 3, timesteps, data_dim))
|
||||
y_val = np.random.random((batch_size * 3, nb_classes))
|
||||
|
||||
model.fit(x_train, y_train,
|
||||
batch_size=batch_size, nb_epoch=5, show_accuracy=True,
|
||||
validation_data=(x_val, y_val))
|
||||
```
|
||||
|
||||
------------------
|
||||
|
||||
### Two merged LSTM encoders for classification over two parallel sequences
|
||||
|
||||
In this model, two input sequences are encoded into vectors by two separate LSTM modules.
|
||||
|
||||
These two vectors are then concatenated, and a fully connected network is trained on top of the concatenated representations.
|
||||
|
||||
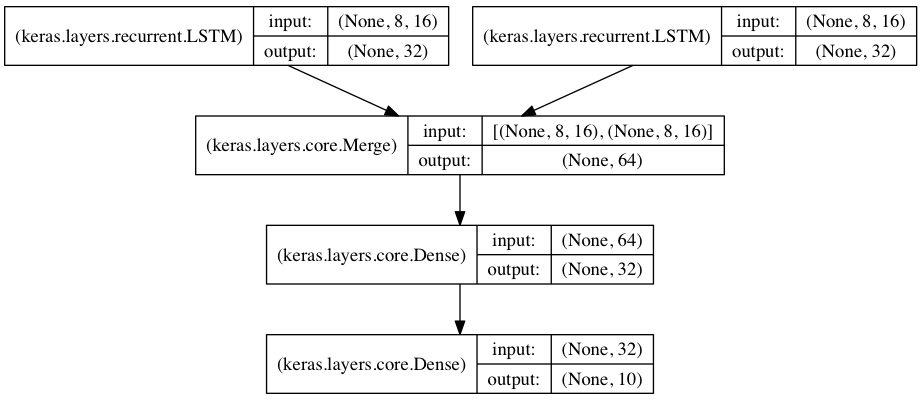
|
||||
|
||||
```python
|
||||
from keras.models import Sequential
|
||||
from keras.layers import Merge, LSTM, Dense
|
||||
import numpy as np
|
||||
|
||||
data_dim = 16
|
||||
timesteps = 8
|
||||
nb_classes = 10
|
||||
|
||||
encoder_a = Sequential()
|
||||
encoder_a.add(LSTM(32, input_shape=(timesteps, data_dim)))
|
||||
|
||||
encoder_b = Sequential()
|
||||
encoder_b.add(LSTM(32, input_shape=(timesteps, data_dim)))
|
||||
|
||||
decoder = Sequential()
|
||||
decoder.add(Merge([encoder_a, encoder_b], mode='concat'))
|
||||
decoder.add(Dense(32, activation='relu'))
|
||||
decoder.add(Dense(nb_classes, activation='softmax'))
|
||||
|
||||
decoder.compile(loss='categorical_crossentropy', optimizer='rmsprop')
|
||||
|
||||
# generate dummy training data
|
||||
x_train_a = np.random.random((1000, timesteps, data_dim))
|
||||
x_train_b = np.random.random((1000, timesteps, data_dim))
|
||||
y_train = np.random.random((1000, nb_classes))
|
||||
|
||||
# generate dummy validation data
|
||||
x_val_a = np.random.random((100, timesteps, data_dim))
|
||||
x_val_b = np.random.random((100, timesteps, data_dim))
|
||||
y_val = np.random.random((100, nb_classes))
|
||||
|
||||
decoder.fit([x_train_a, x_train_b], y_train,
|
||||
batch_size=64, nb_epoch=5, show_accuracy=True,
|
||||
validation_data=([x_val_a, x_val_b], y_val))
|
||||
```
|
||||
|
||||
------------------
|
||||
|
||||
### Single shared LSTM over two parallel sequences, for classification
|
||||
|
||||
This is a similar setup as above, but now a single LSTM encoder is used for both input sequences.
|
||||
Such a setup makes sense if the two input sequences are the same type of object.
|
||||
|
||||
<img src="http://keras.io/img/shared_lstm.png" alt="Shared LSTM" style="width: 500px;"/>
|
||||
|
||||
```python
|
||||
from keras.models import Graph
|
||||
from keras.layers import LSTM, Dense
|
||||
import numpy as np
|
||||
|
||||
data_dim = 16
|
||||
timesteps = 8
|
||||
nb_classes = 10
|
||||
|
||||
encoder = Sequential()
|
||||
encoder.add(LSTM(32, input_shape=(timesteps, data_dim)))
|
||||
|
||||
model = Graph()
|
||||
model.add_input(name='input_a', input_shape=(timesteps, data_dim))
|
||||
model.add_input(name='input_b', input_shape=(timesteps, data_dim))
|
||||
model.add_shared_node(encoder, name='shared_encoder', inputs=['input_a', 'input_b'],
|
||||
merge_mode='concat')
|
||||
model.add_node(Dense(64, activation='relu'), name='fc1', input='shared_encoder')
|
||||
model.add_node(Dense(3, activation='softmax'), name='output', input='fc1', create_output=True)
|
||||
|
||||
model.compile(optimizer='adam', loss={'output': 'categorical_crossentropy'})
|
||||
|
||||
# generate dummy training data
|
||||
x_train_a = np.random.random((1000, timesteps, data_dim))
|
||||
x_train_b = np.random.random((1000, timesteps, data_dim))
|
||||
y_train = np.random.random((1000, 3))
|
||||
|
||||
# generate dummy validation data
|
||||
x_val_a = np.random.random((100, timesteps, data_dim))
|
||||
x_val_b = np.random.random((100, timesteps, data_dim))
|
||||
y_val = np.random.random((100, 3))
|
||||
|
||||
model.fit({'input_a': x_train_a, 'input_b': x_train_b, 'output': y_train},
|
||||
batch_size=64, nb_epoch=5,
|
||||
validation_data={'input_a': x_val_a, 'input_b': x_val_b, 'output': y_val})
|
||||
```
|
||||
externo
+24
-1
@@ -1,5 +1,7 @@
|
||||
# Keras FAQ: Frequently Asked Keras Questions
|
||||
|
||||
[How should I cite Keras?](#how-should-i-cite-keras)
|
||||
|
||||
[How can I run Keras on GPU?](#how-can-i-run-keras-on-gpu)
|
||||
|
||||
[How can I save a Keras model?](#how-can-i-save-a-keras-model)
|
||||
@@ -22,8 +24,26 @@
|
||||
|
||||
---
|
||||
|
||||
### How should I cite Keras?
|
||||
|
||||
Please cite Keras in your publications if it helps your research. Here is an example BibTeX entry:
|
||||
|
||||
```
|
||||
@misc{chollet2015keras,
|
||||
author = {Chollet, François},
|
||||
title = {Keras},
|
||||
year = {2015},
|
||||
publisher = {GitHub},
|
||||
journal = {GitHub repository},
|
||||
howpublished = {\url{https://github.com/fchollet/keras}}
|
||||
}
|
||||
```
|
||||
|
||||
### How can I run Keras on GPU?
|
||||
|
||||
If you are running on the TensorFlow backend, your code will automatically run on GPU if any available GPU is detected.
|
||||
If you are running on the Theano backend, you can use one of the following methods:
|
||||
|
||||
Method 1: use Theano flags.
|
||||
```bash
|
||||
THEANO_FLAGS=device=gpu,floatX=float32 python my_keras_script.py
|
||||
@@ -67,7 +87,10 @@ model = model_from_json(json_string)
|
||||
model = model_from_yaml(yaml_string)
|
||||
```
|
||||
|
||||
If you need to save the weights of a model, you can do so in HDF5:
|
||||
If you need to save the weights of a model, you can do so in HDF5 with the code below.
|
||||
|
||||
Note that you will first need to install HDF5 and the Python library h5py, which do not come bundled with Keras.
|
||||
|
||||
```python
|
||||
model.save_weights('my_model_weights.h5')
|
||||
```
|
||||
|
||||
externo
+3
-3
@@ -7,10 +7,10 @@ An objective function (or loss function, or optimization score function) is one
|
||||
model.compile(loss='mean_squared_error', optimizer='sgd')
|
||||
```
|
||||
|
||||
You can either pass the name of an existing objective, or pass a Theano symbolic function that returns a scalar for each data-point and takes the following two arguments:
|
||||
You can either pass the name of an existing objective, or pass a Theano/TensorFlow symbolic function that returns a scalar for each data-point and takes the following two arguments:
|
||||
|
||||
- __y_true__: True labels. Theano tensor.
|
||||
- __y_pred__: Predictions. Theano tensor of the same shape as y_true.
|
||||
- __y_true__: True labels. Theano/TensorFlow tensor.
|
||||
- __y_pred__: Predictions. Theano/TensorFlow tensor of the same shape as y_true.
|
||||
|
||||
The actual optimized objective is the mean of the output array across all datapoints.
|
||||
|
||||
|
||||
externo
+5
@@ -10,6 +10,11 @@ from keras.utils.visualize_util import plot
|
||||
plot(model, to_file='model.png')
|
||||
```
|
||||
|
||||
`plot` takes two optional arguments:
|
||||
|
||||
- `recursive` (defaults to True) controls whether we recursively explore container layers.
|
||||
- `show_shape` (defaults to False) controls whether output shapes are shown in the graph.
|
||||
|
||||
You can also directly obtain the `pydot.Graph` object and render it yourself,
|
||||
for example to show it in an ipython notebook :
|
||||
```python
|
||||
|
||||
@@ -66,7 +66,7 @@ batch_size = 128
|
||||
nb_classes = 10
|
||||
nb_epoch = 40
|
||||
|
||||
# the data, shuffled and split between tran and test sets
|
||||
# the data, shuffled and split between train and test sets
|
||||
(X_train, y_train), (X_test, y_test) = mnist.load_data()
|
||||
|
||||
X_train = X_train.reshape(60000, 784)
|
||||
|
||||
@@ -18,7 +18,7 @@ from keras.models import Sequential
|
||||
from keras.layers.embeddings import Embedding
|
||||
from keras.layers.core import Activation, Dense, Merge, Permute, Dropout
|
||||
from keras.layers.recurrent import LSTM
|
||||
from keras.datasets.data_utils import get_file
|
||||
from keras.utils.data_utils import get_file
|
||||
from keras.preprocessing.sequence import pad_sequences
|
||||
from functools import reduce
|
||||
import tarfile
|
||||
|
||||
+17
-13
@@ -7,8 +7,8 @@ http://arxiv.org/abs/1502.05698
|
||||
|
||||
Task Number | FB LSTM Baseline | Keras QA
|
||||
--- | --- | ---
|
||||
QA1 - Single Supporting Fact | 50 | 52.1
|
||||
QA2 - Two Supporting Facts | 20 | 37.0
|
||||
QA1 - Single Supporting Fact | 50 | 100.0
|
||||
QA2 - Two Supporting Facts | 20 | 50.0
|
||||
QA3 - Three Supporting Facts | 20 | 20.5
|
||||
QA4 - Two Arg. Relations | 61 | 62.9
|
||||
QA5 - Three Arg. Relations | 70 | 61.9
|
||||
@@ -34,8 +34,8 @@ https://research.facebook.com/researchers/1543934539189348
|
||||
Notes:
|
||||
|
||||
- With default word, sentence, and query vector sizes, the GRU model achieves:
|
||||
- 52.1% test accuracy on QA1 in 20 epochs (2 seconds per epoch on CPU)
|
||||
- 37.0% test accuracy on QA2 in 20 epochs (16 seconds per epoch on CPU)
|
||||
- 100% test accuracy on QA1 in 20 epochs (2 seconds per epoch on CPU)
|
||||
- 50% test accuracy on QA2 in 20 epochs (16 seconds per epoch on CPU)
|
||||
In comparison, the Facebook paper achieves 50% and 20% for the LSTM baseline.
|
||||
|
||||
- The task does not traditionally parse the question separately. This likely
|
||||
@@ -64,9 +64,9 @@ import tarfile
|
||||
import numpy as np
|
||||
np.random.seed(1337) # for reproducibility
|
||||
|
||||
from keras.datasets.data_utils import get_file
|
||||
from keras.utils.data_utils import get_file
|
||||
from keras.layers.embeddings import Embedding
|
||||
from keras.layers.core import Dense, Merge
|
||||
from keras.layers.core import Dense, Merge, Dropout, RepeatVector
|
||||
from keras.layers import recurrent
|
||||
from keras.models import Sequential
|
||||
from keras.preprocessing.sequence import pad_sequences
|
||||
@@ -138,12 +138,12 @@ def vectorize_stories(data, word_idx, story_maxlen, query_maxlen):
|
||||
Y.append(y)
|
||||
return pad_sequences(X, maxlen=story_maxlen), pad_sequences(Xq, maxlen=query_maxlen), np.array(Y)
|
||||
|
||||
RNN = recurrent.GRU
|
||||
RNN = recurrent.LSTM
|
||||
EMBED_HIDDEN_SIZE = 50
|
||||
SENT_HIDDEN_SIZE = 100
|
||||
QUERY_HIDDEN_SIZE = 100
|
||||
BATCH_SIZE = 32
|
||||
EPOCHS = 20
|
||||
EPOCHS = 40
|
||||
print('RNN / Embed / Sent / Query = {}, {}, {}, {}'.format(RNN, EMBED_HIDDEN_SIZE, SENT_HIDDEN_SIZE, QUERY_HIDDEN_SIZE))
|
||||
|
||||
path = get_file('babi-tasks-v1-2.tar.gz', origin='http://www.thespermwhale.com/jaseweston/babi/tasks_1-20_v1-2.tar.gz')
|
||||
@@ -178,15 +178,19 @@ print('story_maxlen, query_maxlen = {}, {}'.format(story_maxlen, query_maxlen))
|
||||
print('Build model...')
|
||||
|
||||
sentrnn = Sequential()
|
||||
sentrnn.add(Embedding(vocab_size, EMBED_HIDDEN_SIZE, mask_zero=True))
|
||||
sentrnn.add(RNN(SENT_HIDDEN_SIZE, return_sequences=False))
|
||||
sentrnn.add(Embedding(vocab_size, EMBED_HIDDEN_SIZE, input_length=story_maxlen, mask_zero=True))
|
||||
sentrnn.add(Dropout(0.3))
|
||||
|
||||
qrnn = Sequential()
|
||||
qrnn.add(Embedding(vocab_size, EMBED_HIDDEN_SIZE))
|
||||
qrnn.add(RNN(QUERY_HIDDEN_SIZE, return_sequences=False))
|
||||
qrnn.add(Embedding(vocab_size, EMBED_HIDDEN_SIZE, input_length=query_maxlen))
|
||||
qrnn.add(Dropout(0.3))
|
||||
qrnn.add(RNN(EMBED_HIDDEN_SIZE, return_sequences=False))
|
||||
qrnn.add(RepeatVector(story_maxlen))
|
||||
|
||||
model = Sequential()
|
||||
model.add(Merge([sentrnn, qrnn], mode='concat'))
|
||||
model.add(Merge([sentrnn, qrnn], mode='sum'))
|
||||
model.add(RNN(EMBED_HIDDEN_SIZE, return_sequences=False))
|
||||
model.add(Dropout(0.3))
|
||||
model.add(Dense(vocab_size, activation='softmax'))
|
||||
|
||||
model.compile(optimizer='adam', loss='categorical_crossentropy', class_mode='categorical')
|
||||
|
||||
@@ -21,6 +21,7 @@ from scipy.optimize import fmin_l_bfgs_b
|
||||
import time
|
||||
import argparse
|
||||
import h5py
|
||||
import os
|
||||
|
||||
from keras.models import Sequential
|
||||
from keras.layers.convolutional import Convolution2D, ZeroPadding2D, MaxPooling2D
|
||||
@@ -215,9 +216,9 @@ for i in range(5):
|
||||
print('Start of iteration', i)
|
||||
start_time = time.time()
|
||||
|
||||
# add a random jitter to the initial image. This will be reverted at decoding time
|
||||
random_jitter = (settings['jitter'] * 2) * (np.random.random((3, img_width, img_height)) - 0.5)
|
||||
x += random_jitter
|
||||
# add a random offset jitter to the initial image. This will be reverted at decoding time
|
||||
ox, oy = np.random.randint(-settings['jitter'], settings['jitter']+1, 2)
|
||||
x = np.roll(np.roll(x, ox, -1), oy, -2)
|
||||
|
||||
# run L-BFGS for 7 steps
|
||||
x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x.flatten(),
|
||||
@@ -225,7 +226,7 @@ for i in range(5):
|
||||
print('Current loss value:', min_val)
|
||||
# decode the dream and save it
|
||||
x = x.reshape((3, img_width, img_height))
|
||||
x -= random_jitter
|
||||
x = np.roll(np.roll(x, -ox, -1), -oy, -2) # unshift image
|
||||
img = deprocess_image(x)
|
||||
fname = result_prefix + '_at_iteration_%d.png' % i
|
||||
imsave(fname, img)
|
||||
|
||||
@@ -55,7 +55,7 @@ model.compile('adam', {'output': 'binary_crossentropy'})
|
||||
print('Train...')
|
||||
model.fit({'input': X_train, 'output': y_train},
|
||||
batch_size=batch_size,
|
||||
nb_epoch=4)
|
||||
nb_epoch=4, show_accuracy=True)
|
||||
acc = accuracy(y_test,
|
||||
np.round(np.array(model.predict({'input': X_test},
|
||||
batch_size=batch_size)['output'])))
|
||||
|
||||
@@ -71,8 +71,7 @@ model.add(Dense(1))
|
||||
model.add(Activation('sigmoid'))
|
||||
|
||||
model.compile(loss='binary_crossentropy',
|
||||
optimizer='rmsprop',
|
||||
class_mode='binary')
|
||||
optimizer='rmsprop')
|
||||
model.fit(X_train, y_train, batch_size=batch_size,
|
||||
nb_epoch=nb_epoch, show_accuracy=True,
|
||||
validation_data=(X_test, y_test))
|
||||
|
||||
@@ -38,7 +38,7 @@ print('Loading data...')
|
||||
print(len(X_train), 'train sequences')
|
||||
print(len(X_test), 'test sequences')
|
||||
|
||||
print("Pad sequences (samples x time)")
|
||||
print('Pad sequences (samples x time)')
|
||||
X_train = sequence.pad_sequences(X_train, maxlen=maxlen)
|
||||
X_test = sequence.pad_sequences(X_test, maxlen=maxlen)
|
||||
print('X_train shape:', X_train.shape)
|
||||
@@ -46,19 +46,18 @@ print('X_test shape:', X_test.shape)
|
||||
|
||||
print('Build model...')
|
||||
model = Sequential()
|
||||
model.add(Embedding(max_features, 128, input_length=maxlen))
|
||||
model.add(LSTM(128)) # try using a GRU instead, for fun
|
||||
model.add(Embedding(max_features, 128, input_length=maxlen, dropout=0.5))
|
||||
model.add(LSTM(128, dropout_W=0.5, dropout_U=0.1)) # try using a GRU instead, for fun
|
||||
model.add(Dropout(0.5))
|
||||
model.add(Dense(1))
|
||||
model.add(Activation('sigmoid'))
|
||||
|
||||
# try using different optimizers and different optimizer configs
|
||||
model.compile(loss='binary_crossentropy',
|
||||
optimizer='adam',
|
||||
class_mode="binary")
|
||||
optimizer='adam')
|
||||
|
||||
print("Train...")
|
||||
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=3,
|
||||
print('Train...')
|
||||
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=15,
|
||||
validation_data=(X_test, y_test), show_accuracy=True)
|
||||
score, acc = model.evaluate(X_test, y_test,
|
||||
batch_size=batch_size,
|
||||
|
||||
@@ -14,13 +14,19 @@ from __future__ import print_function
|
||||
from keras.models import Sequential
|
||||
from keras.layers.core import Dense, Activation, Dropout
|
||||
from keras.layers.recurrent import LSTM
|
||||
from keras.datasets.data_utils import get_file
|
||||
from keras.utils.data_utils import get_file
|
||||
import numpy as np
|
||||
import random
|
||||
import sys
|
||||
|
||||
path = get_file('nietzsche.txt', origin="https://s3.amazonaws.com/text-datasets/nietzsche.txt")
|
||||
text = open(path).read().lower()
|
||||
|
||||
try:
|
||||
text = open(path).read().lower()
|
||||
except UnicodeDecodeError:
|
||||
import codecs
|
||||
text = codecs.open(path, encoding='utf-8').read().lower()
|
||||
|
||||
print('corpus length:', len(text))
|
||||
|
||||
chars = set(text)
|
||||
|
||||
@@ -29,7 +29,7 @@ nb_pool = 2
|
||||
# convolution kernel size
|
||||
nb_conv = 3
|
||||
|
||||
# the data, shuffled and split between tran and test sets
|
||||
# the data, shuffled and split between train and test sets
|
||||
(X_train, y_train), (X_test, y_test) = mnist.load_data()
|
||||
|
||||
X_train = X_train.reshape(X_train.shape[0], 1, img_rows, img_cols)
|
||||
|
||||
@@ -20,7 +20,7 @@ batch_size = 128
|
||||
nb_classes = 10
|
||||
nb_epoch = 20
|
||||
|
||||
# the data, shuffled and split between tran and test sets
|
||||
# the data, shuffled and split between train and test sets
|
||||
(X_train, y_train), (X_test, y_test) = mnist.load_data()
|
||||
|
||||
X_train = X_train.reshape(60000, 784)
|
||||
|
||||
@@ -77,7 +77,7 @@ def compute_accuracy(predictions, labels):
|
||||
return labels[predictions.ravel() < 0.5].mean()
|
||||
|
||||
|
||||
# the data, shuffled and split between tran and test sets
|
||||
# the data, shuffled and split between train and test sets
|
||||
(X_train, y_train), (X_test, y_test) = mnist.load_data()
|
||||
X_train = X_train.reshape(60000, 784)
|
||||
X_test = X_test.reshape(10000, 784)
|
||||
|
||||
@@ -7,11 +7,11 @@ and make sure the variable `weights_path` in this script matches the location of
|
||||
|
||||
Run the script with:
|
||||
```
|
||||
python neural_style.py path_to_your_base_image.jpg path_to_your_reference.jpg prefix_for_results
|
||||
python neural_style_transfer.py path_to_your_base_image.jpg path_to_your_reference.jpg prefix_for_results
|
||||
```
|
||||
e.g.:
|
||||
```
|
||||
python neural_style.py img/tuebingen.jpg img/starry_night.jpg results/my_result
|
||||
python neural_style_transfer.py img/tuebingen.jpg img/starry_night.jpg results/my_result
|
||||
```
|
||||
|
||||
It is preferrable to run this script on GPU, for speed.
|
||||
@@ -89,17 +89,11 @@ assert img_height == img_width, 'Due to the use of the Gram matrix, width and he
|
||||
def preprocess_image(image_path):
|
||||
img = imresize(imread(image_path), (img_width, img_height))
|
||||
img = img.transpose((2, 0, 1)).astype('float64')
|
||||
img[:, :, 0] -= 103.939
|
||||
img[:, :, 1] -= 116.779
|
||||
img[:, :, 2] -= 123.68
|
||||
img = np.expand_dims(img, axis=0)
|
||||
return img
|
||||
|
||||
# util function to convert a tensor into a valid image
|
||||
def deprocess_image(x):
|
||||
x[:, :, 0] += 103.939
|
||||
x[:, :, 1] += 116.779
|
||||
x[:, :, 2] += 123.68
|
||||
x = x.transpose((1, 2, 0))
|
||||
x = np.clip(x, 0, 255).astype('uint8')
|
||||
return x
|
||||
|
||||
@@ -59,7 +59,7 @@ model.add(LSTM(50,
|
||||
return_sequences=False,
|
||||
stateful=True))
|
||||
model.add(Dense(1))
|
||||
model.compile(loss='rmse', optimizer='rmsprop')
|
||||
model.compile(loss='mse', optimizer='rmsprop')
|
||||
|
||||
print('Training')
|
||||
for i in range(epochs):
|
||||
@@ -68,7 +68,8 @@ for i in range(epochs):
|
||||
expected_output,
|
||||
batch_size=batch_size,
|
||||
verbose=1,
|
||||
nb_epoch=1)
|
||||
nb_epoch=1,
|
||||
shuffle=False)
|
||||
model.reset_states()
|
||||
|
||||
print('Predicting')
|
||||
|
||||
+1
-1
@@ -1 +1 @@
|
||||
__version__ = '0.3.1'
|
||||
__version__ = '0.3.3'
|
||||
|
||||
@@ -7,13 +7,9 @@ def softmax(x):
|
||||
if ndim == 2:
|
||||
return K.softmax(x)
|
||||
elif ndim == 3:
|
||||
# apply softmax to each timestep
|
||||
def step(x, states):
|
||||
return K.softmax(x), []
|
||||
last_output, outputs, states = K.rnn(step, x,
|
||||
[],
|
||||
mask=None)
|
||||
return outputs
|
||||
e = K.exp(x - K.max(x, axis=-1, keepdims=True))
|
||||
s = K.sum(e, axis=-1, keepdims=True)
|
||||
return e / s
|
||||
else:
|
||||
raise Exception('Cannot apply softmax to a tensor that is not 2D or 3D. ' +
|
||||
'Here, ndim=' + str(ndim))
|
||||
|
||||
@@ -18,7 +18,7 @@ _config_path = os.path.expanduser(os.path.join(_keras_dir, 'keras.json'))
|
||||
if os.path.exists(_config_path):
|
||||
_config = json.load(open(_config_path))
|
||||
_floatx = _config.get('floatx', floatx())
|
||||
assert _floatx in {'float32', 'float64'}
|
||||
assert _floatx in {'float16', 'float32', 'float64'}
|
||||
_epsilon = _config.get('epsilon', epsilon())
|
||||
assert type(_epsilon) == float
|
||||
_backend = _config.get('backend', _BACKEND)
|
||||
|
||||
@@ -20,7 +20,7 @@ def floatx():
|
||||
|
||||
def set_floatx(floatx):
|
||||
global _FLOATX
|
||||
if floatx not in {'float32', 'float64'}:
|
||||
if floatx not in {'float16', 'float32', 'float64'}:
|
||||
raise Exception('Unknown floatx type: ' + str(floatx))
|
||||
floatx = str(floatx)
|
||||
_FLOATX = floatx
|
||||
|
||||
@@ -1,5 +1,7 @@
|
||||
import tensorflow as tf
|
||||
import numpy as np
|
||||
import os
|
||||
import warnings
|
||||
from .common import _FLOATX, _EPSILON
|
||||
|
||||
# INTERNAL UTILS
|
||||
@@ -7,14 +9,18 @@ from .common import _FLOATX, _EPSILON
|
||||
_SESSION = None
|
||||
|
||||
|
||||
def _get_session():
|
||||
def get_session():
|
||||
global _SESSION
|
||||
if _SESSION is None:
|
||||
_SESSION = tf.Session('')
|
||||
if not os.environ.get('OMP_NUM_THREADS'):
|
||||
_SESSION = tf.Session(config=tf.ConfigProto(allow_soft_placement=True))
|
||||
else:
|
||||
nb_thread = int(os.environ.get('OMP_NUM_THREADS'))
|
||||
_SESSION = tf.Session(config=tf.ConfigProto(intra_op_parallelism_threads=nb_thread, allow_soft_placement=True))
|
||||
return _SESSION
|
||||
|
||||
|
||||
def _set_session(session):
|
||||
def set_session(session):
|
||||
global _SESSION
|
||||
_SESSION = session
|
||||
|
||||
@@ -23,7 +29,7 @@ def _set_session(session):
|
||||
|
||||
def variable(value, dtype=_FLOATX, name=None):
|
||||
v = tf.Variable(np.asarray(value, dtype=dtype), name=name)
|
||||
_get_session().run(v.initializer)
|
||||
get_session().run(v.initializer)
|
||||
return v
|
||||
|
||||
|
||||
@@ -35,7 +41,13 @@ def placeholder(shape=None, ndim=None, dtype=_FLOATX, name=None):
|
||||
|
||||
|
||||
def shape(x):
|
||||
return x.get_shape()
|
||||
# symbolic shape
|
||||
return tf.shape(x)
|
||||
|
||||
|
||||
def int_shape(x):
|
||||
shape = x.get_shape()
|
||||
return tuple([i.__int__() for i in shape])
|
||||
|
||||
|
||||
def ndim(x):
|
||||
@@ -45,7 +57,7 @@ def ndim(x):
|
||||
def eval(x):
|
||||
'''Run a graph.
|
||||
'''
|
||||
return x.eval(session=_get_session())
|
||||
return x.eval(session=get_session())
|
||||
|
||||
|
||||
def zeros(shape, dtype=_FLOATX, name=None):
|
||||
@@ -81,15 +93,28 @@ def dot(x, y):
|
||||
return tf.matmul(x, y)
|
||||
|
||||
|
||||
def batch_dot(x, y, axes=None):
|
||||
if axes:
|
||||
adj_x = None if axes[0][0] == ndim(x)-1 else True
|
||||
adj_y = True if axes[1][0] == ndim(y)-1 else None
|
||||
else:
|
||||
adj_x = None
|
||||
adj_y = None
|
||||
return tf.batch_matmul(x, y, adj_x=adj_x, adj_y=adj_y)
|
||||
|
||||
|
||||
def transpose(x):
|
||||
return tf.transpose(x)
|
||||
|
||||
|
||||
def gather(reference, indices):
|
||||
'''reference: a tensor.
|
||||
indices: an int tensor of indices.
|
||||
'''
|
||||
# Arguments
|
||||
reference: a tensor.
|
||||
indices: an int tensor of indices.
|
||||
|
||||
Return: a tensor of same type as reference.
|
||||
# Returns
|
||||
a tensor of same type as `reference`.
|
||||
'''
|
||||
return tf.gather(reference, indices)
|
||||
|
||||
@@ -200,6 +225,10 @@ def round(x):
|
||||
return tf.round(x)
|
||||
|
||||
|
||||
def sign(x):
|
||||
return tf.sign(x)
|
||||
|
||||
|
||||
def pow(x, a):
|
||||
return tf.pow(x, a)
|
||||
|
||||
@@ -231,7 +260,10 @@ def minimum(x, y):
|
||||
|
||||
def concatenate(tensors, axis=-1):
|
||||
if axis < 0:
|
||||
axis = axis % len(tensors[0].get_shape())
|
||||
if len(tensors[0].get_shape()):
|
||||
axis = axis % len(tensors[0].get_shape())
|
||||
else:
|
||||
axis = 0
|
||||
return tf.concat(axis, tensors)
|
||||
|
||||
|
||||
@@ -242,8 +274,9 @@ def reshape(x, shape):
|
||||
def permute_dimensions(x, pattern):
|
||||
'''Transpose dimensions.
|
||||
|
||||
pattern should be a tuple or list of
|
||||
dimension indices, e.g. [0, 2, 1].
|
||||
# Arguments
|
||||
pattern: should be a tuple or list of
|
||||
dimension indices, e.g. [0, 2, 1].
|
||||
'''
|
||||
return tf.transpose(x, perm=pattern)
|
||||
|
||||
@@ -256,15 +289,15 @@ def resize_images(X, height_factor, width_factor, dim_ordering):
|
||||
positive integers.
|
||||
'''
|
||||
if dim_ordering == 'th':
|
||||
new_height = shape(X)[2].value * height_factor
|
||||
new_width = shape(X)[3].value * width_factor
|
||||
new_shape = tf.shape(X)[2:]
|
||||
new_shape *= tf.constant(np.array([height_factor, width_factor]).astype('int32'))
|
||||
X = permute_dimensions(X, [0, 2, 3, 1])
|
||||
X = tf.image.resize_nearest_neighbor(X, (new_height, new_width))
|
||||
X = tf.image.resize_nearest_neighbor(X, new_shape)
|
||||
return permute_dimensions(X, [0, 3, 1, 2])
|
||||
elif dim_ordering == 'tf':
|
||||
new_height = shape(X)[1].value * height_factor
|
||||
new_width = shape(X)[2].value * width_factor
|
||||
return tf.image.resize_nearest_neighbor(X, (new_height, new_width))
|
||||
new_shape = tf.shape(X)[1:3]
|
||||
new_shape *= tf.constant(np.array([height_factor, width_factor]).astype('int32'))
|
||||
return tf.image.resize_nearest_neighbor(X, new_shape)
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + dim_ordering)
|
||||
|
||||
@@ -345,16 +378,21 @@ def spatial_2d_padding(x, padding=(1, 1), dim_ordering='th'):
|
||||
return tf.pad(x, pattern)
|
||||
|
||||
|
||||
def pack(x):
|
||||
return tf.pack(x)
|
||||
|
||||
|
||||
# VALUE MANIPULATION
|
||||
|
||||
|
||||
def get_value(x):
|
||||
'''Technically the same as eval() for TF.
|
||||
'''
|
||||
return x.eval(session=_get_session())
|
||||
return x.eval(session=get_session())
|
||||
|
||||
|
||||
def set_value(x, value):
|
||||
tf.assign(x, np.asarray(value)).op.run(session=_get_session())
|
||||
tf.assign(x, np.asarray(value)).op.run(session=get_session())
|
||||
|
||||
|
||||
# GRAPH MANIPULATION
|
||||
@@ -362,9 +400,9 @@ def set_value(x, value):
|
||||
class Function(object):
|
||||
|
||||
def __init__(self, inputs, outputs, updates=[]):
|
||||
assert type(inputs) in {list, tuple}
|
||||
assert type(outputs) in {list, tuple}
|
||||
assert type(updates) in {list, tuple}
|
||||
assert type(inputs) in {list, tuple}, 'Input to a TensorFlow backend function should be a list or tuple.'
|
||||
assert type(outputs) in {list, tuple}, 'Output to a TensorFlow backend function should be a list or tuple.'
|
||||
assert type(updates) in {list, tuple}, 'Updates in a TensorFlow backend function should be a list or tuple.'
|
||||
self.inputs = list(inputs)
|
||||
self.outputs = list(outputs)
|
||||
with tf.control_dependencies(self.outputs):
|
||||
@@ -374,12 +412,18 @@ class Function(object):
|
||||
assert type(inputs) in {list, tuple}
|
||||
names = [v.name for v in self.inputs]
|
||||
feed_dict = dict(zip(names, inputs))
|
||||
session = _get_session()
|
||||
session = get_session()
|
||||
updated = session.run(self.outputs + self.updates, feed_dict=feed_dict)
|
||||
return updated[:len(self.outputs)]
|
||||
|
||||
|
||||
def function(inputs, outputs, updates=[]):
|
||||
def function(inputs, outputs, updates=[], **kwargs):
|
||||
if len(kwargs) > 0:
|
||||
msg = [
|
||||
"Expected no kwargs, you passed %s" % len(kwargs),
|
||||
"kwargs passed to function are ignored with Tensorflow backend"
|
||||
]
|
||||
warnings.warn('\n'.join(msg))
|
||||
return Function(inputs, outputs, updates=updates)
|
||||
|
||||
|
||||
@@ -390,46 +434,47 @@ def gradients(loss, variables):
|
||||
# CONTROL FLOW
|
||||
|
||||
def rnn(step_function, inputs, initial_states,
|
||||
go_backwards=False, mask=None):
|
||||
go_backwards=False, mask=None, constants=None):
|
||||
'''Iterates over the time dimension of a tensor.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
inputs: tensor of temporal data of shape (samples, time, ...)
|
||||
(at least 3D).
|
||||
step_function:
|
||||
Parameters:
|
||||
input: tensor with shape (samples, ...) (no time dimension),
|
||||
representing input for the batch of samples at a certain
|
||||
time step.
|
||||
states: list of tensors.
|
||||
Returns:
|
||||
output: tensor with shape (samples, ...) (no time dimension),
|
||||
new_states: list of tensors, same length and shapes
|
||||
as 'states'.
|
||||
initial_states: tensor with shape (samples, ...) (no time dimension),
|
||||
containing the initial values for the states used in
|
||||
the step function.
|
||||
go_backwards: boolean. If True, do the iteration over
|
||||
the time dimension in reverse order.
|
||||
mask: binary tensor with shape (samples, time, 1),
|
||||
with a zero for every element that is masked.
|
||||
# Arguments
|
||||
inputs: tensor of temporal data of shape (samples, time, ...)
|
||||
(at least 3D).
|
||||
step_function:
|
||||
Parameters:
|
||||
input: tensor with shape (samples, ...) (no time dimension),
|
||||
representing input for the batch of samples at a certain
|
||||
time step.
|
||||
states: list of tensors.
|
||||
Returns:
|
||||
output: tensor with shape (samples, ...) (no time dimension),
|
||||
new_states: list of tensors, same length and shapes
|
||||
as 'states'.
|
||||
initial_states: tensor with shape (samples, ...) (no time dimension),
|
||||
containing the initial values for the states used in
|
||||
the step function.
|
||||
go_backwards: boolean. If True, do the iteration over
|
||||
the time dimension in reverse order.
|
||||
mask: binary tensor with shape (samples, time, 1),
|
||||
with a zero for every element that is masked.
|
||||
constants: a list of constant values passed at each step.
|
||||
|
||||
Returns
|
||||
-------
|
||||
A tuple (last_output, outputs, new_states).
|
||||
last_output: the latest output of the rnn, of shape (samples, ...)
|
||||
outputs: tensor with shape (samples, time, ...) where each
|
||||
entry outputs[s, t] is the output of the step function
|
||||
at time t for sample s.
|
||||
new_states: list of tensors, latest states returned by
|
||||
the step function, of shape (samples, ...).
|
||||
# Returns
|
||||
A tuple (last_output, outputs, new_states).
|
||||
last_output: the latest output of the rnn, of shape (samples, ...)
|
||||
outputs: tensor with shape (samples, time, ...) where each
|
||||
entry outputs[s, t] is the output of the step function
|
||||
at time t for sample s.
|
||||
new_states: list of tensors, latest states returned by
|
||||
the step function, of shape (samples, ...).
|
||||
'''
|
||||
ndim = len(inputs.get_shape())
|
||||
assert ndim >= 3, "Input should be at least 3D."
|
||||
axes = [1, 0] + list(range(2, ndim))
|
||||
inputs = tf.transpose(inputs, (axes))
|
||||
input_list = tf.unpack(inputs)
|
||||
if constants is None:
|
||||
constants = []
|
||||
|
||||
states = initial_states
|
||||
successive_states = []
|
||||
@@ -445,8 +490,11 @@ def rnn(step_function, inputs, initial_states,
|
||||
mask = tf.cast(tf.transpose(mask, axes), tf.bool)
|
||||
mask_list = tf.unpack(mask)
|
||||
|
||||
if go_backwards:
|
||||
mask_list.reverse()
|
||||
|
||||
for input, mask_t in zip(input_list, mask_list):
|
||||
output, new_states = step_function(input, states)
|
||||
output, new_states = step_function(input, states + constants)
|
||||
|
||||
# tf.select needs its condition tensor to be the same shape as its two
|
||||
# result tensors, but in our case the condition (mask) tensor is
|
||||
@@ -474,7 +522,7 @@ def rnn(step_function, inputs, initial_states,
|
||||
successive_states.append(states)
|
||||
else:
|
||||
for input in input_list:
|
||||
output, states = step_function(input, states)
|
||||
output, states = step_function(input, states + constants)
|
||||
successive_outputs.append(output)
|
||||
successive_states.append(states)
|
||||
|
||||
@@ -488,7 +536,12 @@ def rnn(step_function, inputs, initial_states,
|
||||
|
||||
|
||||
def switch(condition, then_expression, else_expression):
|
||||
'''condition: scalar tensor.
|
||||
'''Switch between two operations depending on a scalar value.
|
||||
|
||||
# Arguments
|
||||
condition: scalar tensor.
|
||||
then_expression: TensorFlow operation.
|
||||
else_expression: TensorFlow operation.
|
||||
'''
|
||||
return tf.python.control_flow_ops.cond(condition,
|
||||
lambda: then_expression,
|
||||
@@ -500,14 +553,18 @@ def switch(condition, then_expression, else_expression):
|
||||
def relu(x, alpha=0., max_value=None):
|
||||
'''ReLU.
|
||||
|
||||
alpha: slope of negative section.
|
||||
# Arguments
|
||||
alpha: slope of negative section.
|
||||
max_value: saturation threshold.
|
||||
'''
|
||||
negative_part = tf.nn.relu(-x)
|
||||
x = tf.nn.relu(x)
|
||||
if max_value is not None:
|
||||
x = tf.clip_by_value(x, tf.cast(0., dtype=_FLOATX),
|
||||
tf.cast(max_value, dtype=_FLOATX))
|
||||
x -= tf.constant(alpha, dtype=_FLOATX) * negative_part
|
||||
if isinstance(alpha, (tuple, list, np.ndarray)) or np.isscalar(alpha):
|
||||
alpha = tf.constant(alpha, dtype=_FLOATX)
|
||||
x -= alpha * negative_part
|
||||
return x
|
||||
|
||||
|
||||
@@ -526,13 +583,13 @@ def categorical_crossentropy(output, target, from_logits=False):
|
||||
if not from_logits:
|
||||
# scale preds so that the class probas of each sample sum to 1
|
||||
output /= tf.reduce_sum(output,
|
||||
reduction_indices=len(output.get_shape())-1,
|
||||
reduction_indices=len(output.get_shape()) - 1,
|
||||
keep_dims=True)
|
||||
# manual computation of crossentropy
|
||||
output = tf.clip_by_value(output, tf.cast(_EPSILON, dtype=_FLOATX),
|
||||
tf.cast(1.-_EPSILON, dtype=_FLOATX))
|
||||
tf.cast(1. - _EPSILON, dtype=_FLOATX))
|
||||
return - tf.reduce_sum(target * tf.log(output),
|
||||
reduction_indices=len(output.get_shape())-1)
|
||||
reduction_indices=len(output.get_shape()) - 1)
|
||||
else:
|
||||
return tf.nn.softmax_cross_entropy_with_logits(output, target)
|
||||
|
||||
@@ -584,11 +641,12 @@ def l2_normalize(x, axis):
|
||||
|
||||
def conv2d(x, kernel, strides=(1, 1), border_mode='valid', dim_ordering='th',
|
||||
image_shape=None, filter_shape=None):
|
||||
'''
|
||||
Run on cuDNN if available.
|
||||
border_mode: string, "same" or "valid".
|
||||
dim_ordering: whether to use Theano or TensorFlow dimension ordering
|
||||
in inputs/kernels/ouputs.
|
||||
'''Runs on cuDNN if available.
|
||||
|
||||
# Arguments
|
||||
border_mode: string, "same" or "valid".
|
||||
dim_ordering: whether to use Theano or TensorFlow dimension ordering
|
||||
in inputs/kernels/ouputs.
|
||||
'''
|
||||
if border_mode == 'same':
|
||||
padding = 'SAME'
|
||||
@@ -628,10 +686,11 @@ def conv2d(x, kernel, strides=(1, 1), border_mode='valid', dim_ordering='th',
|
||||
def pool2d(x, pool_size, strides=(1, 1),
|
||||
border_mode='valid', dim_ordering='th', pool_mode='max'):
|
||||
'''
|
||||
pool_size: tuple of 2 integers.
|
||||
strides: tuple of 2 integers.
|
||||
border_mode: one of "valid", "same".
|
||||
dim_ordering: one of "th", "tf".
|
||||
# Arguments
|
||||
pool_size: tuple of 2 integers.
|
||||
strides: tuple of 2 integers.
|
||||
border_mode: one of "valid", "same".
|
||||
dim_ordering: one of "th", "tf".
|
||||
'''
|
||||
if border_mode == 'same':
|
||||
padding = 'SAME'
|
||||
@@ -686,3 +745,10 @@ def random_uniform(shape, low=0.0, high=1.0, dtype=_FLOATX, seed=None):
|
||||
seed = np.random.randint(10e6)
|
||||
return tf.random_uniform(shape, minval=low, maxval=high,
|
||||
dtype=dtype, seed=seed)
|
||||
|
||||
|
||||
def random_binomial(shape, p=0.0, dtype=_FLOATX, seed=None):
|
||||
if seed is None:
|
||||
seed = np.random.randint(10e6)
|
||||
return tf.select(tf.random_uniform(shape, dtype=dtype, seed=seed) <= p,
|
||||
tf.ones(shape), tf.zeros(shape))
|
||||
|
||||
@@ -1,7 +1,9 @@
|
||||
import theano
|
||||
from theano import tensor as T
|
||||
from theano.sandbox.rng_mrg import MRG_RandomStreams as RandomStreams
|
||||
from theano.tensor.signal import downsample
|
||||
from theano.tensor.signal import pool
|
||||
from theano.tensor.nnet import conv3d2d
|
||||
import inspect
|
||||
import numpy as np
|
||||
from .common import _FLOATX, _EPSILON
|
||||
|
||||
@@ -10,21 +12,6 @@ from .common import _FLOATX, _EPSILON
|
||||
theano.config.floatX = _FLOATX
|
||||
|
||||
|
||||
def _on_gpu():
|
||||
'''Return whether the session is set to
|
||||
run on GPU or not (i.e. on CPU).
|
||||
'''
|
||||
return theano.config.device[:3] == 'gpu' or theano.sandbox.cuda.cuda_enabled
|
||||
|
||||
|
||||
if _on_gpu():
|
||||
'''Import cuDNN only if running on GPU:
|
||||
not having Cuda installed should not
|
||||
prevent from running the present code.
|
||||
'''
|
||||
from theano.sandbox.cuda import dnn
|
||||
|
||||
|
||||
# VARIABLE MANIPULATION
|
||||
|
||||
def variable(value, dtype=_FLOATX, name=None):
|
||||
@@ -41,6 +28,7 @@ def placeholder(shape=None, ndim=None, dtype=_FLOATX, name=None):
|
||||
raise Exception('Specify either a shape or ndim value.')
|
||||
if shape is not None:
|
||||
ndim = len(shape)
|
||||
|
||||
broadcast = (False,) * ndim
|
||||
return T.TensorType(dtype, broadcast)(name)
|
||||
|
||||
@@ -108,6 +96,13 @@ def dot(x, y):
|
||||
return T.dot(x, y)
|
||||
|
||||
|
||||
def batch_dot(x, y, axes=None):
|
||||
if axes is None:
|
||||
# behaves like tf.batch_matmul as default
|
||||
axes = [(x.ndim-1,), (y.ndim-2,)]
|
||||
return T.batched_tensordot(x, y, axes=axes)
|
||||
|
||||
|
||||
def transpose(x):
|
||||
return T.transpose(x)
|
||||
|
||||
@@ -145,7 +140,10 @@ def prod(x, axis=None, keepdims=False):
|
||||
|
||||
|
||||
def mean(x, axis=None, keepdims=False):
|
||||
return T.mean(x, axis=axis, keepdims=keepdims)
|
||||
dtype = None
|
||||
if 'int' in x.dtype:
|
||||
dtype = _FLOATX
|
||||
return T.mean(x, axis=axis, keepdims=keepdims, dtype=dtype)
|
||||
|
||||
|
||||
def std(x, axis=None, keepdims=False):
|
||||
@@ -191,6 +189,10 @@ def round(x):
|
||||
return T.round(x)
|
||||
|
||||
|
||||
def sign(x):
|
||||
return T.sgn(x)
|
||||
|
||||
|
||||
def pow(x, a):
|
||||
return T.pow(x, a)
|
||||
|
||||
@@ -265,6 +267,27 @@ def resize_images(X, height_factor, width_factor, dim_ordering):
|
||||
raise Exception('Invalid dim_ordering: ' + dim_ordering)
|
||||
|
||||
|
||||
def resize_volumes(X, depth_factor, height_factor, width_factor, dim_ordering):
|
||||
'''Resize the volume contained in a 5D tensor of shape
|
||||
- [batch, channels, depth, height, width] (for 'th' dim_ordering)
|
||||
- [batch, depth, height, width, channels] (for 'tf' dim_ordering)
|
||||
by a factor of (depth_factor, height_factor, width_factor).
|
||||
Both factors should be positive integers.
|
||||
'''
|
||||
if dim_ordering == 'th':
|
||||
output = repeat_elements(X, depth_factor, axis=2)
|
||||
output = repeat_elements(output, height_factor, axis=3)
|
||||
output = repeat_elements(output, width_factor, axis=4)
|
||||
return output
|
||||
elif dim_ordering == 'tf':
|
||||
output = repeat_elements(X, depth_factor, axis=1)
|
||||
output = repeat_elements(output, height_factor, axis=2)
|
||||
output = repeat_elements(output, width_factor, axis=3)
|
||||
return output
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + dim_ordering)
|
||||
|
||||
|
||||
def repeat(x, n):
|
||||
'''Repeat a 2D tensor.
|
||||
|
||||
@@ -357,6 +380,45 @@ def spatial_2d_padding(x, padding=(1, 1), dim_ordering='th'):
|
||||
raise Exception('Invalid dim_ordering: ' + dim_ordering)
|
||||
return T.set_subtensor(output[indices], x)
|
||||
|
||||
|
||||
def spatial_3d_padding(x, padding=(1, 1, 1), dim_ordering='th'):
|
||||
'''Pad the 2nd, 3rd and 4th dimensions of a 5D tensor
|
||||
with "padding[0]", "padding[1]" and "padding[2]" (resp.) zeros left and right.
|
||||
'''
|
||||
input_shape = x.shape
|
||||
if dim_ordering == 'th':
|
||||
output_shape = (input_shape[0],
|
||||
input_shape[1],
|
||||
input_shape[2] + 2 * padding[0],
|
||||
input_shape[3] + 2 * padding[1],
|
||||
input_shape[4] + 2 * padding[2])
|
||||
output = T.zeros(output_shape)
|
||||
indices = (slice(None),
|
||||
slice(None),
|
||||
slice(padding[0], input_shape[2] + padding[0]),
|
||||
slice(padding[1], input_shape[3] + padding[1]),
|
||||
slice(padding[2], input_shape[4] + padding[2]))
|
||||
|
||||
elif dim_ordering == 'tf':
|
||||
output_shape = (input_shape[0],
|
||||
input_shape[1] + 2 * padding[0],
|
||||
input_shape[2] + 2 * padding[1],
|
||||
input_shape[3] + 2 * padding[2],
|
||||
input_shape[4])
|
||||
output = T.zeros(output_shape)
|
||||
indices = (slice(None),
|
||||
slice(padding[0], input_shape[1] + padding[0]),
|
||||
slice(padding[1], input_shape[2] + padding[1]),
|
||||
slice(padding[2], input_shape[3] + padding[2]),
|
||||
slice(None))
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + dim_ordering)
|
||||
return T.set_subtensor(output[indices], x)
|
||||
|
||||
|
||||
def pack(x):
|
||||
return T.stack(*x)
|
||||
|
||||
# VALUE MANIPULATION
|
||||
|
||||
|
||||
@@ -384,8 +446,14 @@ class Function(object):
|
||||
return self.function(*inputs)
|
||||
|
||||
|
||||
def function(inputs, outputs, updates=[]):
|
||||
return Function(inputs, outputs, updates=updates)
|
||||
def function(inputs, outputs, updates=[], **kwargs):
|
||||
if len(kwargs) > 0:
|
||||
function_args = inspect.getargspec(theano.function)[0]
|
||||
for key in kwargs.keys():
|
||||
if key not in function_args:
|
||||
msg = "Invalid argument '%s' passed to K.function" % key
|
||||
raise ValueError(msg)
|
||||
return Function(inputs, outputs, updates=updates, **kwargs)
|
||||
|
||||
|
||||
def gradients(loss, variables):
|
||||
@@ -395,40 +463,40 @@ def gradients(loss, variables):
|
||||
# CONTROL FLOW
|
||||
|
||||
def rnn(step_function, inputs, initial_states,
|
||||
go_backwards=False, mask=None):
|
||||
go_backwards=False, mask=None, constants=None):
|
||||
'''Iterates over the time dimension of a tensor.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
inputs: tensor of temporal data of shape (samples, time, ...)
|
||||
(at least 3D).
|
||||
step_function:
|
||||
Parameters:
|
||||
input: tensor with shape (samples, ...) (no time dimension),
|
||||
representing input for the batch of samples at a certain
|
||||
time step.
|
||||
states: list of tensors.
|
||||
Returns:
|
||||
output: tensor with shape (samples, ...) (no time dimension),
|
||||
new_states: list of tensors, same length and shapes
|
||||
as 'states'.
|
||||
initial_states: tensor with shape (samples, ...) (no time dimension),
|
||||
containing the initial values for the states used in
|
||||
the step function.
|
||||
go_backwards: boolean. If True, do the iteration over
|
||||
the time dimension in reverse order.
|
||||
mask: binary tensor with shape (samples, time),
|
||||
with a zero for every element that is masked.
|
||||
# Arguments
|
||||
inputs: tensor of temporal data of shape (samples, time, ...)
|
||||
(at least 3D).
|
||||
step_function:
|
||||
Parameters:
|
||||
input: tensor with shape (samples, ...) (no time dimension),
|
||||
representing input for the batch of samples at a certain
|
||||
time step.
|
||||
states: list of tensors.
|
||||
Returns:
|
||||
output: tensor with shape (samples, ...) (no time dimension),
|
||||
new_states: list of tensors, same length and shapes
|
||||
as 'states'.
|
||||
initial_states: tensor with shape (samples, ...) (no time dimension),
|
||||
containing the initial values for the states used in
|
||||
the step function.
|
||||
go_backwards: boolean. If True, do the iteration over
|
||||
the time dimension in reverse order.
|
||||
mask: binary tensor with shape (samples, time),
|
||||
with a zero for every element that is masked.
|
||||
constants: a list of constant values passed at each step.
|
||||
|
||||
Returns
|
||||
-------
|
||||
A tuple (last_output, outputs, new_states).
|
||||
last_output: the latest output of the rnn, of shape (samples, ...)
|
||||
outputs: tensor with shape (samples, time, ...) where each
|
||||
entry outputs[s, t] is the output of the step function
|
||||
at time t for sample s.
|
||||
new_states: list of tensors, latest states returned by
|
||||
the step function, of shape (samples, ...).
|
||||
|
||||
# Returns
|
||||
A tuple (last_output, outputs, new_states).
|
||||
last_output: the latest output of the rnn, of shape (samples, ...)
|
||||
outputs: tensor with shape (samples, time, ...) where each
|
||||
entry outputs[s, t] is the output of the step function
|
||||
at time t for sample s.
|
||||
new_states: list of tensors, latest states returned by
|
||||
the step function, of shape (samples, ...).
|
||||
'''
|
||||
ndim = inputs.ndim
|
||||
assert ndim >= 3, 'Input should be at least 3D.'
|
||||
@@ -442,8 +510,10 @@ def rnn(step_function, inputs, initial_states,
|
||||
assert mask.ndim == ndim
|
||||
mask = mask.dimshuffle(axes)
|
||||
|
||||
if constants is None:
|
||||
constants = []
|
||||
# build an all-zero tensor of shape (samples, output_dim)
|
||||
initial_output = step_function(inputs[0], initial_states)[0] * 0
|
||||
initial_output = step_function(inputs[0], initial_states + constants)[0] * 0
|
||||
# Theano gets confused by broadcasting patterns in the scan op
|
||||
initial_output = T.unbroadcast(initial_output, 0, 1)
|
||||
|
||||
@@ -460,6 +530,7 @@ def rnn(step_function, inputs, initial_states,
|
||||
_step,
|
||||
sequences=[inputs, mask],
|
||||
outputs_info=[initial_output] + initial_states,
|
||||
non_sequences=constants,
|
||||
go_backwards=go_backwards)
|
||||
else:
|
||||
def _step(input, *states):
|
||||
@@ -470,6 +541,7 @@ def rnn(step_function, inputs, initial_states,
|
||||
_step,
|
||||
sequences=inputs,
|
||||
outputs_info=[None] + initial_states,
|
||||
non_sequences=constants,
|
||||
go_backwards=go_backwards)
|
||||
|
||||
# deal with Theano API inconsistency
|
||||
@@ -569,7 +641,6 @@ def l2_normalize(x, axis):
|
||||
def conv2d(x, kernel, strides=(1, 1), border_mode='valid', dim_ordering='th',
|
||||
image_shape=None, filter_shape=None):
|
||||
'''
|
||||
Run on cuDNN if available.
|
||||
border_mode: string, "same" or "valid".
|
||||
'''
|
||||
if dim_ordering not in {'th', 'tf'}:
|
||||
@@ -591,51 +662,153 @@ def conv2d(x, kernel, strides=(1, 1), border_mode='valid', dim_ordering='th',
|
||||
filter_shape = (filter_shape[3], filter_shape[2],
|
||||
filter_shape[0], filter_shape[1])
|
||||
|
||||
if _on_gpu() and dnn.dnn_available():
|
||||
if border_mode == 'same':
|
||||
assert(strides == (1, 1))
|
||||
conv_out = dnn.dnn_conv(img=x,
|
||||
kerns=kernel,
|
||||
border_mode='full')
|
||||
np_kernel = kernel.eval()
|
||||
shift_x = (np_kernel.shape[2] - 1) // 2
|
||||
shift_y = (np_kernel.shape[3] - 1) // 2
|
||||
conv_out = conv_out[:, :,
|
||||
shift_x:x.shape[2] + shift_x,
|
||||
shift_y:x.shape[3] + shift_y]
|
||||
else:
|
||||
conv_out = dnn.dnn_conv(img=x,
|
||||
kerns=kernel,
|
||||
border_mode=border_mode,
|
||||
subsample=strides)
|
||||
if border_mode == 'same':
|
||||
th_border_mode = 'half'
|
||||
np_kernel = kernel.eval()
|
||||
assert strides[0] <= np_kernel.shape[2], 'strides should be smaller than the convolution window.'
|
||||
assert strides[1] <= np_kernel.shape[3], 'strides should be smaller than the convolution window.'
|
||||
elif border_mode == 'valid':
|
||||
th_border_mode = 'valid'
|
||||
else:
|
||||
if border_mode == 'same':
|
||||
th_border_mode = 'full'
|
||||
assert(strides == (1, 1))
|
||||
elif border_mode == 'valid':
|
||||
th_border_mode = 'valid'
|
||||
else:
|
||||
raise Exception('Border mode not supported: ' + str(border_mode))
|
||||
raise Exception('Border mode not supported: ' + str(border_mode))
|
||||
|
||||
# Theano might not accept like longs
|
||||
def int_or_none(value):
|
||||
try:
|
||||
return int(value)
|
||||
except TypeError:
|
||||
return None
|
||||
|
||||
if image_shape is not None:
|
||||
image_shape = tuple(int_or_none(v) for v in image_shape)
|
||||
|
||||
if filter_shape is not None:
|
||||
filter_shape = tuple(int_or_none(v) for v in filter_shape)
|
||||
|
||||
conv_out = T.nnet.conv2d(x, kernel,
|
||||
border_mode=th_border_mode,
|
||||
subsample=strides,
|
||||
input_shape=image_shape,
|
||||
filter_shape=filter_shape)
|
||||
|
||||
if border_mode == 'same':
|
||||
if np_kernel.shape[2] % 2 == 0:
|
||||
conv_out = conv_out[:,:,:(x.shape[2]+strides[0]-1) // strides[0],:]
|
||||
if np_kernel.shape[3] % 2 == 0:
|
||||
conv_out = conv_out[:,:,:,:(x.shape[3]+strides[1]-1) // strides[1]]
|
||||
|
||||
conv_out = T.nnet.conv.conv2d(x, kernel,
|
||||
border_mode=th_border_mode,
|
||||
subsample=strides,
|
||||
image_shape=image_shape,
|
||||
filter_shape=filter_shape)
|
||||
if border_mode == 'same':
|
||||
np_kernel = kernel.eval()
|
||||
shift_x = (np_kernel.shape[2] - 1) // 2
|
||||
shift_y = (np_kernel.shape[3] - 1) // 2
|
||||
conv_out = conv_out[:, :,
|
||||
shift_x:x.shape[2] + shift_x,
|
||||
shift_y:x.shape[3] + shift_y]
|
||||
if dim_ordering == 'tf':
|
||||
conv_out = conv_out.dimshuffle((0, 2, 3, 1))
|
||||
return conv_out
|
||||
|
||||
|
||||
def conv3d(x, kernel, strides=(1, 1, 1),
|
||||
border_mode='valid', dim_ordering='th',
|
||||
volume_shape=None, filter_shape=None):
|
||||
'''
|
||||
Run on cuDNN if available.
|
||||
border_mode: string, "same" or "valid".
|
||||
'''
|
||||
if dim_ordering not in {'th', 'tf'}:
|
||||
raise Exception('Unknown dim_ordering ' + str(dim_ordering))
|
||||
|
||||
if border_mode not in {'same', 'valid'}:
|
||||
raise Exception('Invalid border mode: ' + str(border_mode))
|
||||
|
||||
if dim_ordering == 'tf':
|
||||
# TF uses the last dimension as channel dimension,
|
||||
# instead of the 2nd one.
|
||||
# TH input shape: (samples, input_depth, conv_dim1, conv_dim2, conv_dim3)
|
||||
# TF input shape: (samples, conv_dim1, conv_dim2, conv_dim3, input_depth)
|
||||
# TH kernel shape: (out_depth, input_depth, kernel_dim1, kernel_dim2, kernel_dim3)
|
||||
# TF kernel shape: (kernel_dim1, kernel_dim2, kernel_dim3, input_depth, out_depth)
|
||||
x = x.dimshuffle((0, 4, 1, 2, 3))
|
||||
kernel = kernel.dimshuffle((4, 3, 0, 1, 2))
|
||||
if volume_shape:
|
||||
volume_shape = (volume_shape[0], volume_shape[4],
|
||||
volume_shape[1], volume_shape[2], volume_shape[3])
|
||||
if filter_shape:
|
||||
filter_shape = (filter_shape[4], filter_shape[3],
|
||||
filter_shape[0], filter_shape[1], filter_shape[2])
|
||||
|
||||
if border_mode == 'same':
|
||||
assert(strides == (1, 1, 1))
|
||||
pad_dim1 = (kernel.shape[2] - 1)
|
||||
pad_dim2 = (kernel.shape[3] - 1)
|
||||
pad_dim3 = (kernel.shape[4] - 1)
|
||||
output_shape = (x.shape[0], x.shape[1],
|
||||
x.shape[2] + pad_dim1,
|
||||
x.shape[3] + pad_dim2,
|
||||
x.shape[4] + pad_dim3)
|
||||
output = T.zeros(output_shape)
|
||||
indices = (slice(None), slice(None),
|
||||
slice(pad_dim1 // 2, x.shape[2] + pad_dim1 // 2),
|
||||
slice(pad_dim2 // 2, x.shape[3] + pad_dim2 // 2),
|
||||
slice(pad_dim3 // 2, x.shape[4] + pad_dim3 // 2))
|
||||
x = T.set_subtensor(output[indices], x)
|
||||
border_mode = 'valid'
|
||||
|
||||
border_mode_3d = (border_mode, border_mode, border_mode)
|
||||
conv_out = conv3d2d.conv3d(signals=x.dimshuffle(0, 2, 1, 3, 4),
|
||||
filters=kernel.dimshuffle(0, 2, 1, 3, 4),
|
||||
border_mode=border_mode_3d)
|
||||
conv_out = conv_out.dimshuffle(0, 2, 1, 3, 4)
|
||||
|
||||
# support strides by manually slicing the output
|
||||
if strides != (1, 1, 1):
|
||||
conv_out = conv_out[:, :, ::strides[0], ::strides[1], ::strides[2]]
|
||||
|
||||
if dim_ordering == 'tf':
|
||||
conv_out = conv_out.dimshuffle((0, 2, 3, 4, 1))
|
||||
|
||||
return conv_out
|
||||
|
||||
|
||||
def pool2d(x, pool_size, strides=(1, 1), border_mode='valid',
|
||||
dim_ordering='th', pool_mode='max'):
|
||||
if border_mode == 'same':
|
||||
w_pad = pool_size[0] - 2 if pool_size[0] % 2 == 1 else pool_size[0] - 1
|
||||
h_pad = pool_size[1] - 2 if pool_size[1] % 2 == 1 else pool_size[1] - 1
|
||||
padding = (w_pad, h_pad)
|
||||
elif border_mode == 'valid':
|
||||
padding = (0, 0)
|
||||
else:
|
||||
raise Exception('Invalid border mode: ' + str(border_mode))
|
||||
|
||||
if dim_ordering not in {'th', 'tf'}:
|
||||
raise Exception('Unknown dim_ordering ' + str(dim_ordering))
|
||||
|
||||
if dim_ordering == 'tf':
|
||||
x = x.dimshuffle((0, 3, 1, 2))
|
||||
|
||||
if pool_mode == 'max':
|
||||
pool_out = pool.pool_2d(x, ds=pool_size, st=strides,
|
||||
ignore_border=True,
|
||||
padding=padding,
|
||||
mode='max')
|
||||
elif pool_mode == 'avg':
|
||||
pool_out = pool.pool_2d(x, ds=pool_size, st=strides,
|
||||
ignore_border=True,
|
||||
padding=padding,
|
||||
mode='average_exc_pad')
|
||||
else:
|
||||
raise Exception('Invalid pooling mode: ' + str(pool_mode))
|
||||
|
||||
if border_mode == 'same':
|
||||
expected_width = (x.shape[2] + strides[0] - 1) // strides[0]
|
||||
expected_height = (x.shape[3] + strides[1] - 1) // strides[1]
|
||||
|
||||
pool_out = pool_out[:, :,
|
||||
: expected_width,
|
||||
: expected_height]
|
||||
|
||||
if dim_ordering == 'tf':
|
||||
pool_out = pool_out.dimshuffle((0, 2, 3, 1))
|
||||
return pool_out
|
||||
|
||||
|
||||
def pool3d(x, pool_size, strides=(1, 1, 1), border_mode='valid',
|
||||
dim_ordering='th', pool_mode='max'):
|
||||
if border_mode == 'same':
|
||||
# TODO: add implementation for border_mode="same"
|
||||
raise Exception('border_mode="same" not supported with Theano.')
|
||||
@@ -649,23 +822,46 @@ def pool2d(x, pool_size, strides=(1, 1), border_mode='valid',
|
||||
raise Exception('Unknown dim_ordering ' + str(dim_ordering))
|
||||
|
||||
if dim_ordering == 'tf':
|
||||
x = x.dimshuffle((0, 3, 1, 2))
|
||||
x = x.dimshuffle((0, 4, 1, 2, 3))
|
||||
|
||||
if pool_mode == 'max':
|
||||
pool_out = downsample.max_pool_2d(x, ds=pool_size, st=strides,
|
||||
ignore_border=ignore_border,
|
||||
padding=padding,
|
||||
mode='max')
|
||||
# pooling over conv_dim2, conv_dim1 (last two channels)
|
||||
output = pool.pool_2d(input=x.dimshuffle(0, 1, 4, 3, 2),
|
||||
ds=(pool_size[1], pool_size[0]),
|
||||
st=(strides[1], strides[0]),
|
||||
ignore_border=ignore_border,
|
||||
padding=padding,
|
||||
mode='max')
|
||||
|
||||
# pooling over conv_dim3
|
||||
pool_out = pool.pool_2d(input=output.dimshuffle(0, 1, 4, 3, 2),
|
||||
ds=(1, pool_size[2]),
|
||||
st=(1, strides[2]),
|
||||
ignore_border=ignore_border,
|
||||
padding=padding,
|
||||
mode='max')
|
||||
|
||||
elif pool_mode == 'avg':
|
||||
pool_out = downsample.max_pool_2d(x, ds=pool_size, st=strides,
|
||||
ignore_border=ignore_border,
|
||||
padding=padding,
|
||||
mode='average_exc_pad')
|
||||
# pooling over conv_dim2, conv_dim1 (last two channels)
|
||||
output = pool.pool_2d(input=x.dimshuffle(0, 1, 4, 3, 2),
|
||||
ds=(pool_size[1], pool_size[0]),
|
||||
st=(strides[1], strides[0]),
|
||||
ignore_border=ignore_border,
|
||||
padding=padding,
|
||||
mode='average_exc_pad')
|
||||
|
||||
# pooling over conv_dim3
|
||||
pool_out = pool.pool_2d(input=output.dimshuffle(0, 1, 4, 3, 2),
|
||||
ds=(1, pool_size[2]),
|
||||
st=(1, strides[2]),
|
||||
ignore_border=ignore_border,
|
||||
padding=padding,
|
||||
mode='average_exc_pad')
|
||||
else:
|
||||
raise Exception('Invalid pooling mode: ' + str(pool_mode))
|
||||
|
||||
if dim_ordering == 'tf':
|
||||
pool_out = pool_out.dimshuffle((0, 2, 3, 1))
|
||||
pool_out = pool_out.dimshuffle((0, 2, 3, 4, 1))
|
||||
return pool_out
|
||||
|
||||
|
||||
@@ -685,6 +881,13 @@ def random_uniform(shape, low=0.0, high=1.0, dtype=_FLOATX, seed=None):
|
||||
rng = RandomStreams(seed=seed)
|
||||
return rng.uniform(shape, low=low, high=high, dtype=dtype)
|
||||
|
||||
|
||||
def random_binomial(shape, p=0.0, dtype=_FLOATX, seed=None):
|
||||
if seed is None:
|
||||
seed = np.random.randint(10e6)
|
||||
rng = RandomStreams(seed=seed)
|
||||
return rng.binomial(shape, p=p, dtype=dtype)
|
||||
|
||||
'''
|
||||
more TODO:
|
||||
|
||||
|
||||
+34
-65
@@ -92,7 +92,8 @@ class Callback(object):
|
||||
will include the following quantities in the `logs` that
|
||||
it passes to its callbacks:
|
||||
|
||||
on_epoch_end: logs optionally include `val_loss`
|
||||
on_epoch_end: logs include `acc` and `loss`, and
|
||||
optionally include `val_loss`
|
||||
(if validation is enabled in `fit`), and `val_acc`
|
||||
(if validation and accuracy monitoring are enabled).
|
||||
on_batch_begin: logs include `size`,
|
||||
@@ -129,11 +130,35 @@ class Callback(object):
|
||||
|
||||
|
||||
class BaseLogger(Callback):
|
||||
'''Callback that prints events to the standard output.
|
||||
'''Callback that accumulates epoch averages of
|
||||
the metrics being monitored.
|
||||
|
||||
This callback is automatically applied to
|
||||
every Keras model (it is the basis of the verbosity modes
|
||||
in models).
|
||||
every Keras model.
|
||||
'''
|
||||
def on_epoch_begin(self, epoch, logs={}):
|
||||
self.seen = 0
|
||||
self.totals = {}
|
||||
|
||||
def on_batch_end(self, batch, logs={}):
|
||||
batch_size = logs.get('size', 0)
|
||||
self.seen += batch_size
|
||||
|
||||
for k, v in logs.items():
|
||||
if k in self.totals:
|
||||
self.totals[k] += v * batch_size
|
||||
else:
|
||||
self.totals[k] = v * batch_size
|
||||
|
||||
def on_epoch_end(self, epoch, logs={}):
|
||||
for k in self.params['metrics']:
|
||||
if k in self.totals:
|
||||
# make value available to next callbacks
|
||||
logs[k] = self.totals[k] / self.seen
|
||||
|
||||
|
||||
class ProgbarLogger(Callback):
|
||||
'''Callback that prints metrics to stdout.
|
||||
'''
|
||||
def on_train_begin(self, logs={}):
|
||||
self.verbose = self.params['verbose']
|
||||
@@ -145,7 +170,6 @@ class BaseLogger(Callback):
|
||||
self.progbar = Progbar(target=self.params['nb_sample'],
|
||||
verbose=self.verbose)
|
||||
self.seen = 0
|
||||
self.totals = {}
|
||||
|
||||
def on_batch_begin(self, batch, logs={}):
|
||||
if self.seen < self.params['nb_sample']:
|
||||
@@ -155,11 +179,6 @@ class BaseLogger(Callback):
|
||||
batch_size = logs.get('size', 0)
|
||||
self.seen += batch_size
|
||||
|
||||
for k, v in logs.items():
|
||||
if k in self.totals:
|
||||
self.totals[k] += v * batch_size
|
||||
else:
|
||||
self.totals[k] = v * batch_size
|
||||
for k in self.params['metrics']:
|
||||
if k in logs:
|
||||
self.log_values.append((k, logs[k]))
|
||||
@@ -171,8 +190,6 @@ class BaseLogger(Callback):
|
||||
|
||||
def on_epoch_end(self, epoch, logs={}):
|
||||
for k in self.params['metrics']:
|
||||
if k in self.totals:
|
||||
self.log_values.append((k, self.totals[k] / self.seen))
|
||||
if k in logs:
|
||||
self.log_values.append((k, logs[k]))
|
||||
if self.verbose:
|
||||
@@ -191,26 +208,8 @@ class History(Callback):
|
||||
self.epoch = []
|
||||
self.history = {}
|
||||
|
||||
def on_epoch_begin(self, epoch, logs={}):
|
||||
self.seen = 0
|
||||
self.totals = {}
|
||||
|
||||
def on_batch_end(self, batch, logs={}):
|
||||
batch_size = logs.get('size', 0)
|
||||
self.seen += batch_size
|
||||
for k, v in logs.items():
|
||||
if k in self.totals:
|
||||
self.totals[k] += v * batch_size
|
||||
else:
|
||||
self.totals[k] = v * batch_size
|
||||
|
||||
def on_epoch_end(self, epoch, logs={}):
|
||||
self.epoch.append(epoch)
|
||||
for k, v in self.totals.items():
|
||||
if k not in self.history:
|
||||
self.history[k] = []
|
||||
self.history[k].append(v / self.seen)
|
||||
|
||||
for k, v in logs.items():
|
||||
if k not in self.history:
|
||||
self.history[k] = []
|
||||
@@ -256,7 +255,7 @@ class ModelCheckpoint(Callback):
|
||||
|
||||
if mode not in ['auto', 'min', 'max']:
|
||||
warnings.warn('ModelCheckpoint mode %s is unknown, '
|
||||
'fallback to auto mode.' % (self.mode),
|
||||
'fallback to auto mode.' % (mode),
|
||||
RuntimeWarning)
|
||||
mode = 'auto'
|
||||
|
||||
@@ -373,26 +372,10 @@ class RemoteMonitor(Callback):
|
||||
def __init__(self, root='http://localhost:9000'):
|
||||
self.root = root
|
||||
|
||||
def on_epoch_begin(self, epoch, logs={}):
|
||||
self.seen = 0
|
||||
self.totals = {}
|
||||
|
||||
def on_batch_end(self, batch, logs={}):
|
||||
batch_size = logs.get('size', 0)
|
||||
self.seen += batch_size
|
||||
for k, v in logs.items():
|
||||
if k in self.totals:
|
||||
self.totals[k] += v * batch_size
|
||||
else:
|
||||
self.totals[k] = v * batch_size
|
||||
|
||||
def on_epoch_end(self, epoch, logs={}):
|
||||
import requests
|
||||
send = {}
|
||||
send['epoch'] = epoch
|
||||
|
||||
for k, v in self.totals.items():
|
||||
send[k] = v / self.seen
|
||||
for k, v in logs.items():
|
||||
send[k] = v
|
||||
|
||||
@@ -463,7 +446,7 @@ class TensorBoard(Callback):
|
||||
import keras.backend.tensorflow_backend as KTF
|
||||
|
||||
self.model = model
|
||||
self.sess = KTF._get_session()
|
||||
self.sess = KTF.get_session()
|
||||
if self.histogram_freq and not self.merged:
|
||||
mod_type = self.model.get_config()['name']
|
||||
if mod_type == 'Sequential':
|
||||
@@ -486,19 +469,6 @@ class TensorBoard(Callback):
|
||||
self.writer = tf.train.SummaryWriter(self.log_dir,
|
||||
self.sess.graph_def)
|
||||
|
||||
def on_epoch_begin(self, epoch, logs={}):
|
||||
self.seen = 0
|
||||
self.totals = {}
|
||||
|
||||
def on_batch_end(self, batch, logs={}):
|
||||
batch_size = logs.get('size', 0)
|
||||
self.seen += batch_size
|
||||
for k, v in logs.items():
|
||||
if k in self.totals:
|
||||
self.totals[k] += v * batch_size
|
||||
else:
|
||||
self.totals[k] = v * batch_size
|
||||
|
||||
def on_epoch_end(self, epoch, logs={}):
|
||||
import tensorflow as tf
|
||||
|
||||
@@ -509,15 +479,14 @@ class TensorBoard(Callback):
|
||||
else:
|
||||
test_function = self.model._test
|
||||
names = [v.name for v in test_function.inputs]
|
||||
# TODO: implement batched calls to sess.run
|
||||
# (current call will likely go OOM on GPU)
|
||||
feed_dict = dict(zip(names, self.model.validation_data))
|
||||
result = self.sess.run([self.merged], feed_dict=feed_dict)
|
||||
summary_str = result[0]
|
||||
self.writer.add_summary(summary_str, epoch)
|
||||
|
||||
all_values = self.totals.copy()
|
||||
all_values.update(logs)
|
||||
|
||||
for name, value in all_values.items():
|
||||
for name, value in logs.items():
|
||||
if name in ['batch', 'size']:
|
||||
continue
|
||||
summary = tf.Summary()
|
||||
|
||||
@@ -4,6 +4,7 @@ import sys
|
||||
from six.moves import cPickle
|
||||
from six.moves import range
|
||||
|
||||
|
||||
def load_batch(fpath, label_key='labels'):
|
||||
f = open(fpath, 'rb')
|
||||
if sys.version_info < (3,):
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from __future__ import absolute_import
|
||||
from .cifar import load_batch
|
||||
from .data_utils import get_file
|
||||
from ..utils.data_utils import get_file
|
||||
import numpy as np
|
||||
import os
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from __future__ import absolute_import
|
||||
from .cifar import load_batch
|
||||
from .data_utils import get_file
|
||||
from ..utils.data_utils import get_file
|
||||
import numpy as np
|
||||
import os
|
||||
|
||||
|
||||
@@ -1,53 +1,4 @@
|
||||
from __future__ import absolute_import
|
||||
from __future__ import print_function
|
||||
from ..utils.data_utils import *
|
||||
import warnings
|
||||
|
||||
import tarfile
|
||||
import os
|
||||
from six.moves.urllib.request import FancyURLopener
|
||||
|
||||
from ..utils.generic_utils import Progbar
|
||||
|
||||
|
||||
class ParanoidURLopener(FancyURLopener):
|
||||
def http_error_default(self, url, fp, errcode, errmsg, headers):
|
||||
raise Exception('URL fetch failure on {}: {} -- {}'.format(url, errcode, errmsg))
|
||||
|
||||
|
||||
def get_file(fname, origin, untar=False):
|
||||
datadir_base = os.path.expanduser(os.path.join('~', '.keras'))
|
||||
if not os.access(datadir_base, os.W_OK):
|
||||
datadir_base = os.path.join('/tmp', '.keras')
|
||||
datadir = os.path.join(datadir_base, 'datasets')
|
||||
if not os.path.exists(datadir):
|
||||
os.makedirs(datadir)
|
||||
|
||||
if untar:
|
||||
untar_fpath = os.path.join(datadir, fname)
|
||||
fpath = untar_fpath + '.tar.gz'
|
||||
else:
|
||||
fpath = os.path.join(datadir, fname)
|
||||
|
||||
if not os.path.exists(fpath):
|
||||
print('Downloading data from', origin)
|
||||
global progbar
|
||||
progbar = None
|
||||
|
||||
def dl_progress(count, block_size, total_size):
|
||||
global progbar
|
||||
if progbar is None:
|
||||
progbar = Progbar(total_size)
|
||||
else:
|
||||
progbar.update(count*block_size)
|
||||
|
||||
ParanoidURLopener().retrieve(origin, fpath, dl_progress)
|
||||
progbar = None
|
||||
|
||||
if untar:
|
||||
if not os.path.exists(untar_fpath):
|
||||
print('Untaring file...')
|
||||
tfile = tarfile.open(fpath, 'r:gz')
|
||||
tfile.extractall(path=datadir)
|
||||
tfile.close()
|
||||
return untar_fpath
|
||||
|
||||
return fpath
|
||||
warnings.warn('data_utils has been moved to keras.utils.data_utils.')
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
from __future__ import absolute_import
|
||||
from six.moves import cPickle
|
||||
import gzip
|
||||
from .data_utils import get_file
|
||||
from ..utils.data_utils import get_file
|
||||
from six.moves import zip
|
||||
import numpy as np
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
import gzip
|
||||
from .data_utils import get_file
|
||||
from ..utils.data_utils import get_file
|
||||
from six.moves import cPickle
|
||||
import sys
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
from __future__ import absolute_import
|
||||
from .data_utils import get_file
|
||||
from ..utils.data_utils import get_file
|
||||
from six.moves import cPickle
|
||||
from six.moves import zip
|
||||
import numpy as np
|
||||
|
||||
+33
-15
@@ -3,9 +3,26 @@ import numpy as np
|
||||
from . import backend as K
|
||||
|
||||
|
||||
def get_fans(shape):
|
||||
fan_in = shape[0] if len(shape) == 2 else np.prod(shape[1:])
|
||||
fan_out = shape[1] if len(shape) == 2 else shape[0]
|
||||
def get_fans(shape, dim_ordering='th'):
|
||||
if len(shape) == 2:
|
||||
fan_in = shape[0]
|
||||
fan_out = shape[1]
|
||||
elif len(shape) == 4 or len(shape) == 5:
|
||||
# assuming convolution kernels (2D or 3D).
|
||||
# TH kernel shape: (depth, input_depth, ...)
|
||||
# TF kernel shape: (..., input_depth, depth)
|
||||
if dim_ordering == 'th':
|
||||
fan_in = np.prod(shape[1:])
|
||||
fan_out = shape[0]
|
||||
elif dim_ordering == 'tf':
|
||||
fan_in = np.prod(shape[:-1])
|
||||
fan_out = shape[-1]
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + dim_ordering)
|
||||
else:
|
||||
# no specific assumptions
|
||||
fan_in = np.sqrt(np.prod(shape))
|
||||
fan_out = np.sqrt(np.prod(shape))
|
||||
return fan_in, fan_out
|
||||
|
||||
|
||||
@@ -19,39 +36,39 @@ def normal(shape, scale=0.05, name=None):
|
||||
name=name)
|
||||
|
||||
|
||||
def lecun_uniform(shape, name=None):
|
||||
def lecun_uniform(shape, name=None, dim_ordering='th'):
|
||||
''' Reference: LeCun 98, Efficient Backprop
|
||||
http://yann.lecun.com/exdb/publis/pdf/lecun-98b.pdf
|
||||
'''
|
||||
fan_in, fan_out = get_fans(shape)
|
||||
fan_in, fan_out = get_fans(shape, dim_ordering=dim_ordering)
|
||||
scale = np.sqrt(3. / fan_in)
|
||||
return uniform(shape, scale, name=name)
|
||||
|
||||
|
||||
def glorot_normal(shape, name=None):
|
||||
def glorot_normal(shape, name=None, dim_ordering='th'):
|
||||
''' Reference: Glorot & Bengio, AISTATS 2010
|
||||
'''
|
||||
fan_in, fan_out = get_fans(shape)
|
||||
fan_in, fan_out = get_fans(shape, dim_ordering=dim_ordering)
|
||||
s = np.sqrt(2. / (fan_in + fan_out))
|
||||
return normal(shape, s, name=name)
|
||||
|
||||
|
||||
def glorot_uniform(shape, name=None):
|
||||
fan_in, fan_out = get_fans(shape)
|
||||
def glorot_uniform(shape, name=None, dim_ordering='th'):
|
||||
fan_in, fan_out = get_fans(shape, dim_ordering=dim_ordering)
|
||||
s = np.sqrt(6. / (fan_in + fan_out))
|
||||
return uniform(shape, s, name=name)
|
||||
|
||||
|
||||
def he_normal(shape, name=None):
|
||||
def he_normal(shape, name=None, dim_ordering='th'):
|
||||
''' Reference: He et al., http://arxiv.org/abs/1502.01852
|
||||
'''
|
||||
fan_in, fan_out = get_fans(shape)
|
||||
fan_in, fan_out = get_fans(shape, dim_ordering=dim_ordering)
|
||||
s = np.sqrt(2. / fan_in)
|
||||
return normal(shape, s, name=name)
|
||||
|
||||
|
||||
def he_uniform(shape, name=None):
|
||||
fan_in, fan_out = get_fans(shape)
|
||||
def he_uniform(shape, name=None, dim_ordering='th'):
|
||||
fan_in, fan_out = get_fans(shape, dim_ordering=dim_ordering)
|
||||
s = np.sqrt(6. / fan_in)
|
||||
return uniform(shape, s, name=name)
|
||||
|
||||
@@ -85,5 +102,6 @@ def one(shape, name=None):
|
||||
|
||||
|
||||
from .utils.generic_utils import get_from_module
|
||||
def get(identifier):
|
||||
return get_from_module(identifier, globals(), 'initialization')
|
||||
def get(identifier, **kwargs):
|
||||
return get_from_module(identifier, globals(),
|
||||
'initialization', kwargs=kwargs)
|
||||
|
||||
@@ -29,8 +29,8 @@ class LeakyReLU(MaskedLayer):
|
||||
return K.relu(X, alpha=self.alpha)
|
||||
|
||||
def get_config(self):
|
||||
config = {"name": self.__class__.__name__,
|
||||
"alpha": self.alpha}
|
||||
config = {'name': self.__class__.__name__,
|
||||
'alpha': self.alpha}
|
||||
base_config = super(LeakyReLU, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
@@ -59,7 +59,8 @@ class PReLU(MaskedLayer):
|
||||
|
||||
def build(self):
|
||||
input_shape = self.input_shape[1:]
|
||||
self.alphas = self.init(input_shape)
|
||||
self.alphas = self.init(input_shape,
|
||||
name='{}_alphas'.format(self.name))
|
||||
self.trainable_weights = [self.alphas]
|
||||
|
||||
if self.initial_weights is not None:
|
||||
@@ -73,8 +74,8 @@ class PReLU(MaskedLayer):
|
||||
return pos + neg
|
||||
|
||||
def get_config(self):
|
||||
config = {"name": self.__class__.__name__,
|
||||
"init": self.init.__name__}
|
||||
config = {'name': self.__class__.__name__,
|
||||
'init': self.init.__name__}
|
||||
base_config = super(PReLU, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
@@ -106,8 +107,8 @@ class ELU(MaskedLayer):
|
||||
return pos + self.alpha * (K.exp(neg) - 1.)
|
||||
|
||||
def get_config(self):
|
||||
config = {"name": self.__class__.__name__,
|
||||
"alpha": self.alpha}
|
||||
config = {'name': self.__class__.__name__,
|
||||
'alpha': self.alpha}
|
||||
base_config = super(ELU, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
@@ -140,8 +141,10 @@ class ParametricSoftplus(MaskedLayer):
|
||||
|
||||
def build(self):
|
||||
input_shape = self.input_shape[1:]
|
||||
self.alphas = K.variable(self.alpha_init * np.ones(input_shape))
|
||||
self.betas = K.variable(self.beta_init * np.ones(input_shape))
|
||||
self.alphas = K.variable(self.alpha_init * np.ones(input_shape),
|
||||
name='{}_alphas'.format(self.name))
|
||||
self.betas = K.variable(self.beta_init * np.ones(input_shape),
|
||||
name='{}_betas'.format(self.name))
|
||||
self.trainable_weights = [self.alphas, self.betas]
|
||||
|
||||
if self.initial_weights is not None:
|
||||
@@ -153,9 +156,9 @@ class ParametricSoftplus(MaskedLayer):
|
||||
return K.softplus(self.betas * X) * self.alphas
|
||||
|
||||
def get_config(self):
|
||||
config = {"name": self.__class__.__name__,
|
||||
"alpha_init": self.alpha_init,
|
||||
"beta_init": self.beta_init}
|
||||
config = {'name': self.__class__.__name__,
|
||||
'alpha_init': self.alpha_init,
|
||||
'beta_init': self.beta_init}
|
||||
base_config = super(ParametricSoftplus, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
@@ -186,8 +189,8 @@ class ThresholdedLinear(MaskedLayer):
|
||||
return K.switch(K.abs(X) < self.theta, 0, X)
|
||||
|
||||
def get_config(self):
|
||||
config = {"name": self.__class__.__name__,
|
||||
"theta": self.theta}
|
||||
config = {'name': self.__class__.__name__,
|
||||
'theta': self.theta}
|
||||
base_config = super(ThresholdedLinear, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
@@ -218,7 +221,66 @@ class ThresholdedReLU(MaskedLayer):
|
||||
return K.switch(X > self.theta, X, 0)
|
||||
|
||||
def get_config(self):
|
||||
config = {"name": self.__class__.__name__,
|
||||
"theta": self.theta}
|
||||
config = {'name': self.__class__.__name__,
|
||||
'theta': self.theta}
|
||||
base_config = super(ThresholdedReLU, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
|
||||
class SReLU(MaskedLayer):
|
||||
'''SReLU
|
||||
|
||||
# Input shape
|
||||
Arbitrary. Use the keyword argument `input_shape`
|
||||
(tuple of integers, does not include the samples axis)
|
||||
when using this layer as the first layer in a model.
|
||||
|
||||
# Output shape
|
||||
Same shape as the input.
|
||||
|
||||
# Arguments
|
||||
t_left_init: initialization function for the left part intercept
|
||||
a_left_init: initialization function for the left part slope
|
||||
t_right_init: initialization function for the right part intercept
|
||||
a_right_init: initialization function for the right part slope
|
||||
|
||||
# References
|
||||
[Deep Learning with S-shaped Rectified Linear Activation Units](http://arxiv.org/abs/1512.07030)
|
||||
'''
|
||||
def __init__(self, t_left_init='zero', a_left_init='glorot_uniform',
|
||||
t_right_init='glorot_uniform', a_right_init='one', **kwargs):
|
||||
self.t_left_init = initializations.get(t_left_init)
|
||||
self.a_left_init = initializations.get(a_left_init)
|
||||
self.t_right_init = initializations.get(t_right_init)
|
||||
self.a_right_init = initializations.get(a_right_init)
|
||||
super(SReLU, self).__init__(**kwargs)
|
||||
|
||||
def build(self):
|
||||
input_shape = self.input_shape[1:]
|
||||
self.t_left = self.t_left_init(input_shape,
|
||||
name='{}_t_left'.format(self.name))
|
||||
self.a_left = self.a_left_init(input_shape,
|
||||
name='{}_a_left'.format(self.name))
|
||||
self.t_right = self.t_right_init(input_shape,
|
||||
name='{}_t_right'.format(self.name))
|
||||
self.a_right = self.a_right_init(input_shape,
|
||||
name='{}_a_right'.format(self.name))
|
||||
# ensure the the right part is always to the right of the left
|
||||
self.t_right_actual = self.t_left + abs(self.t_right)
|
||||
self.trainable_weights = [self.t_left, self.a_left,
|
||||
self.t_right, self.a_right]
|
||||
|
||||
def get_output(self, train=False):
|
||||
X = self.get_input(train)
|
||||
Y_left_and_center = self.t_left + K.relu(X - self.t_left,
|
||||
self.a_left,
|
||||
self.t_right_actual - self.t_left)
|
||||
Y_right = K.relu(X - self.t_right_actual) * self.a_right
|
||||
return Y_left_and_center + Y_right
|
||||
|
||||
def get_config(self):
|
||||
return {'name': self.__class__.__name__,
|
||||
't_left_init': self.t_left_init.__name__,
|
||||
'a_left_init': self.a_left_init.__name__,
|
||||
't_right_init': self.t_right_init.__name__,
|
||||
'a_right_init': self.a_right_init.__name__}
|
||||
|
||||
+114
-31
@@ -21,33 +21,11 @@ class Sequential(Layer):
|
||||
def __init__(self, layers=[]):
|
||||
self.layers = []
|
||||
self.layer_cache = {}
|
||||
self.shape_cache = {}
|
||||
for layer in layers:
|
||||
self.add(layer)
|
||||
self._cache_enabled = True
|
||||
|
||||
def __call__(self, X, mask=None, train=False):
|
||||
# turn off layer cache temporarily
|
||||
tmp_cache_enabled = self.cache_enabled
|
||||
self.cache_enabled = False
|
||||
# recursively search for a layer which is not a Sequential model
|
||||
layer = self
|
||||
while issubclass(layer.__class__, Sequential):
|
||||
layer = layer.layers[0]
|
||||
# set temporary input to first layer
|
||||
tmp_input = layer.get_input
|
||||
tmp_mask = None
|
||||
layer.get_input = lambda _: X
|
||||
if hasattr(layer, 'get_input_mask'):
|
||||
tmp_mask = layer.get_input_mask
|
||||
layer.get_input_mask = lambda _: mask
|
||||
Y = self.get_output(train=train)
|
||||
# return input from first layer to what it was
|
||||
layer.get_input = tmp_input
|
||||
if hasattr(layer, 'get_input_mask'):
|
||||
layer.get_input_mask = tmp_mask
|
||||
self.cache_enabled = tmp_cache_enabled
|
||||
return Y
|
||||
|
||||
@property
|
||||
def cache_enabled(self):
|
||||
return self._cache_enabled
|
||||
@@ -58,11 +36,35 @@ class Sequential(Layer):
|
||||
for l in self.layers:
|
||||
l.cache_enabled = value
|
||||
|
||||
def set_previous(self, layer):
|
||||
self.layers[0].previous = layer
|
||||
@property
|
||||
def layer_cache(self):
|
||||
return super(Sequential, self).layer_cache
|
||||
|
||||
@layer_cache.setter
|
||||
def layer_cache(self, value):
|
||||
self._layer_cache = value
|
||||
for layer in self.layers:
|
||||
layer.layer_cache = self._layer_cache
|
||||
|
||||
@property
|
||||
def shape_cache(self):
|
||||
return super(Sequential, self).shape_cache
|
||||
|
||||
@shape_cache.setter
|
||||
def shape_cache(self, value):
|
||||
self._shape_cache = value
|
||||
for layer in self.layers:
|
||||
layer.shape_cache = self._shape_cache
|
||||
|
||||
def set_previous(self, layer, reset_weights=True):
|
||||
self.layers[0].set_previous(layer, reset_weights)
|
||||
|
||||
def clear_previous(self, reset_weights=True):
|
||||
self.layers[0].clear_previous(reset_weights)
|
||||
|
||||
def add(self, layer):
|
||||
layer.layer_cache = self.layer_cache
|
||||
layer.shape_cache = self.shape_cache
|
||||
self.layers.append(layer)
|
||||
if len(self.layers) > 1:
|
||||
self.layers[-1].set_previous(self.layers[-2])
|
||||
@@ -154,9 +156,9 @@ class Sequential(Layer):
|
||||
return weights
|
||||
|
||||
def set_weights(self, weights):
|
||||
for i in range(len(self.layers)):
|
||||
nb_param = len(self.layers[i].trainable_weights) + len(self.layers[i].non_trainable_weights)
|
||||
self.layers[i].set_weights(weights[:nb_param])
|
||||
for layer in self.layers:
|
||||
nb_param = len(layer.get_weights())
|
||||
layer.set_weights(weights[:nb_param])
|
||||
weights = weights[nb_param:]
|
||||
|
||||
def get_config(self):
|
||||
@@ -188,6 +190,72 @@ class Graph(Layer):
|
||||
self.output_config = [] # dicts
|
||||
self.node_config = [] # dicts
|
||||
self.layer_cache = {}
|
||||
self.shape_cache = {}
|
||||
self._cache_enabled = True
|
||||
|
||||
def __call__(self, X, mask=None, train=False):
|
||||
if type(X) != dict:
|
||||
return super(Graph, self).__call__(X, mask, train)
|
||||
else:
|
||||
# turn off layer cache temporarily
|
||||
tmp_cache_enabled = self.cache_enabled
|
||||
self.cache_enabled = False
|
||||
# create a temporary layer for each input
|
||||
tmp_previous = {}
|
||||
for name, input in self.inputs.items():
|
||||
layer = Layer(batch_input_shape=input.input_shape)
|
||||
layer.input = X[name]
|
||||
if hasattr(self, 'get_input_mask'):
|
||||
layer.get_input_mask = lambda _: mask[name]
|
||||
# set temporary previous
|
||||
if hasattr(input, 'previous'):
|
||||
tmp_previous[name] = input.previous
|
||||
input.set_previous(layer, False)
|
||||
Y = self.get_output(train=train)
|
||||
# return previous to what it was
|
||||
for name, input in self.inputs.items():
|
||||
if name in tmp_previous:
|
||||
input.set_previous(tmp_previous[name], False)
|
||||
else:
|
||||
input.clear_previous(False)
|
||||
self.cache_enabled = tmp_cache_enabled
|
||||
return Y
|
||||
|
||||
@property
|
||||
def cache_enabled(self):
|
||||
return self._cache_enabled
|
||||
|
||||
@cache_enabled.setter
|
||||
def cache_enabled(self, value):
|
||||
self._cache_enabled = value
|
||||
for l in self.nodes.values():
|
||||
l.cache_enabled = value
|
||||
for l in self.inputs.values():
|
||||
l.cache_enabled = value
|
||||
|
||||
@property
|
||||
def layer_cache(self):
|
||||
return super(Graph, self).layer_cache
|
||||
|
||||
@layer_cache.setter
|
||||
def layer_cache(self, value):
|
||||
self._layer_cache = value
|
||||
for layer in self.nodes.values():
|
||||
layer.layer_cache = self._layer_cache
|
||||
for layer in self.inputs.values():
|
||||
layer.layer_cache = self._layer_cache
|
||||
|
||||
@property
|
||||
def shape_cache(self):
|
||||
return super(Graph, self).shape_cache
|
||||
|
||||
@shape_cache.setter
|
||||
def shape_cache(self, value):
|
||||
self._shape_cache = value
|
||||
for layer in self.nodes.values():
|
||||
layer.shape_cache = self._shape_cache
|
||||
for layer in self.inputs.values():
|
||||
layer.shape_cache = self._shape_cache
|
||||
|
||||
@property
|
||||
def nb_input(self):
|
||||
@@ -248,22 +316,35 @@ class Graph(Layer):
|
||||
if hasattr(l, 'reset_states') and getattr(l, 'stateful', False):
|
||||
l.reset_states()
|
||||
|
||||
def set_previous(self, layer, connection_map={}):
|
||||
def set_previous(self, layer, connection_map={}, reset_weights=True):
|
||||
if self.nb_input != layer.nb_output:
|
||||
raise Exception('Cannot connect layers: '
|
||||
'input count does not match output count.')
|
||||
if self.nb_input == 1:
|
||||
self.inputs[self.input_order[0]].set_previous(layer)
|
||||
self.inputs[self.input_order[0]].set_previous(layer, reset_weights)
|
||||
else:
|
||||
if not connection_map:
|
||||
raise Exception('Cannot attach multi-input layer: '
|
||||
'no connection_map provided.')
|
||||
for k, v in connection_map.items():
|
||||
if k in self.inputs and v in layer.outputs:
|
||||
self.inputs[k].set_previous(layer.outputs[v])
|
||||
self.inputs[k].set_previous(layer.outputs[v], reset_weights)
|
||||
else:
|
||||
raise Exception('Invalid connection map.')
|
||||
|
||||
def clear_previous(self, reset_weights=True):
|
||||
for k in self.inputs.values():
|
||||
k.clear_previous(reset_weights)
|
||||
|
||||
@property
|
||||
def input_shape(self):
|
||||
if self.nb_input == 1:
|
||||
# return tuple
|
||||
return self.inputs[self.input_order[0]].input_shape
|
||||
else:
|
||||
# return dictionary mapping input names to shape tuples
|
||||
return dict([(k, v.input_shape) for k, v in self.inputs.items()])
|
||||
|
||||
def get_input(self, train=False):
|
||||
if len(self.inputs) == len(self.outputs) == 1:
|
||||
return self.inputs[self.input_order[0]].get_input(train)
|
||||
@@ -374,6 +455,7 @@ class Graph(Layer):
|
||||
|
||||
self.namespace.add(name)
|
||||
layer.layer_cache = self.layer_cache
|
||||
layer.shape_cache = self.shape_cache
|
||||
self.nodes[name] = layer
|
||||
self.node_config.append({'name': name,
|
||||
'input': input,
|
||||
@@ -450,6 +532,7 @@ class Graph(Layer):
|
||||
sh = SiameseHead(i)
|
||||
sh.previous = s
|
||||
sh_name = outputs[i]
|
||||
sh.name = sh_name
|
||||
self.namespace.add(sh_name)
|
||||
self.nodes[sh_name] = sh
|
||||
self.node_config.append({'name': sh_name,
|
||||
|
||||
+490
-19
@@ -79,7 +79,7 @@ class Convolution1D(Layer):
|
||||
raise Exception('Invalid border mode for Convolution1D:', border_mode)
|
||||
self.nb_filter = nb_filter
|
||||
self.filter_length = filter_length
|
||||
self.init = initializations.get(init)
|
||||
self.init = initializations.get(init, dim_ordering='th')
|
||||
self.activation = activations.get(activation)
|
||||
assert border_mode in {'valid', 'same'}, 'border_mode must be in {valid, same}'
|
||||
self.border_mode = border_mode
|
||||
@@ -101,14 +101,13 @@ class Convolution1D(Layer):
|
||||
self.input_length = input_length
|
||||
if self.input_dim:
|
||||
kwargs['input_shape'] = (self.input_length, self.input_dim)
|
||||
self.input = K.placeholder(ndim=3)
|
||||
super(Convolution1D, self).__init__(**kwargs)
|
||||
|
||||
def build(self):
|
||||
input_dim = self.input_shape[2]
|
||||
self.W_shape = (self.nb_filter, input_dim, self.filter_length, 1)
|
||||
self.W = self.init(self.W_shape)
|
||||
self.b = K.zeros((self.nb_filter,))
|
||||
self.W = self.init(self.W_shape, name='{}_W'.format(self.name))
|
||||
self.b = K.zeros((self.nb_filter,), name='{}_b'.format(self.name))
|
||||
self.trainable_weights = [self.W, self.b]
|
||||
self.regularizers = []
|
||||
|
||||
@@ -234,7 +233,7 @@ class Convolution2D(Layer):
|
||||
self.nb_filter = nb_filter
|
||||
self.nb_row = nb_row
|
||||
self.nb_col = nb_col
|
||||
self.init = initializations.get(init)
|
||||
self.init = initializations.get(init, dim_ordering=dim_ordering)
|
||||
self.activation = activations.get(activation)
|
||||
assert border_mode in {'valid', 'same'}, 'border_mode must be in {valid, same}'
|
||||
self.border_mode = border_mode
|
||||
@@ -251,7 +250,6 @@ class Convolution2D(Layer):
|
||||
self.constraints = [self.W_constraint, self.b_constraint]
|
||||
|
||||
self.initial_weights = weights
|
||||
self.input = K.placeholder(ndim=4)
|
||||
super(Convolution2D, self).__init__(**kwargs)
|
||||
|
||||
def build(self):
|
||||
@@ -263,8 +261,8 @@ class Convolution2D(Layer):
|
||||
self.W_shape = (self.nb_row, self.nb_col, stack_size, self.nb_filter)
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + self.dim_ordering)
|
||||
self.W = self.init(self.W_shape)
|
||||
self.b = K.zeros((self.nb_filter,))
|
||||
self.W = self.init(self.W_shape, name='{}_W'.format(self.name))
|
||||
self.b = K.zeros((self.nb_filter,), name='{}_b'.format(self.name))
|
||||
self.trainable_weights = [self.W, self.b]
|
||||
self.regularizers = []
|
||||
|
||||
@@ -343,6 +341,195 @@ class Convolution2D(Layer):
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
|
||||
class Convolution3D(Layer):
|
||||
'''Convolution operator for filtering windows of three-dimensional inputs.
|
||||
When using this layer as the first layer in a model,
|
||||
provide the keyword argument `input_shape`
|
||||
(tuple of integers, does not include the sample axis),
|
||||
e.g. `input_shape=(3, 10, 128, 128)` for 10 frames of 128x128 RGB pictures.
|
||||
|
||||
Note: this layer will only work with Theano for the time being.
|
||||
|
||||
# Input shape
|
||||
5D tensor with shape:
|
||||
`(samples, channels, conv_dim1, conv_dim2, conv_dim3)` if dim_ordering='th'
|
||||
or 5D tensor with shape:
|
||||
`(samples, conv_dim1, conv_dim2, conv_dim3, channels)` if dim_ordering='tf'.
|
||||
|
||||
# Output shape
|
||||
5D tensor with shape:
|
||||
`(samples, nb_filter, new_conv_dim1, new_conv_dim2, new_conv_dim3)` if dim_ordering='th'
|
||||
or 5D tensor with shape:
|
||||
`(samples, new_conv_dim1, new_conv_dim2, new_conv_dim3, nb_filter)` if dim_ordering='tf'.
|
||||
`new_conv_dim1`, `new_conv_dim2` and `new_conv_dim3` values might have changed due to padding.
|
||||
|
||||
# Arguments
|
||||
nb_filter: Number of convolution filters to use.
|
||||
kernel_dim1: Length of the first dimension in the covolution kernel.
|
||||
kernel_dim2: Length of the second dimension in the convolution kernel.
|
||||
kernel_dim3: Length of the third dimension in the convolution kernel.
|
||||
init: name of initialization function for the weights of the layer
|
||||
(see [initializations](../initializations.md)), or alternatively,
|
||||
Theano function to use for weights initialization.
|
||||
This parameter is only relevant if you don't pass
|
||||
a `weights` argument.
|
||||
activation: name of activation function to use
|
||||
(see [activations](../activations.md)),
|
||||
or alternatively, elementwise Theano function.
|
||||
If you don't specify anything, no activation is applied
|
||||
(ie. "linear" activation: a(x) = x).
|
||||
weights: list of numpy arrays to set as initial weights.
|
||||
border_mode: 'valid' or 'same'.
|
||||
subsample: tuple of length 3. Factor by which to subsample output.
|
||||
Also called strides elsewhere.
|
||||
Note: 'subsample' is implemented by slicing the output of conv3d with strides=(1,1,1).
|
||||
W_regularizer: instance of [WeightRegularizer](../regularizers.md)
|
||||
(eg. L1 or L2 regularization), applied to the main weights matrix.
|
||||
b_regularizer: instance of [WeightRegularizer](../regularizers.md),
|
||||
applied to the bias.
|
||||
activity_regularizer: instance of [ActivityRegularizer](../regularizers.md),
|
||||
applied to the network output.
|
||||
W_constraint: instance of the [constraints](../constraints.md) module
|
||||
(eg. maxnorm, nonneg), applied to the main weights matrix.
|
||||
b_constraint: instance of the [constraints](../constraints.md) module,
|
||||
applied to the bias.
|
||||
dim_ordering: 'th' or 'tf'. In 'th' mode, the channels dimension
|
||||
(the depth) is at index 1, in 'tf' mode is it at index 4.
|
||||
'''
|
||||
input_ndim = 5
|
||||
|
||||
def __init__(self, nb_filter, kernel_dim1, kernel_dim2, kernel_dim3,
|
||||
init='glorot_uniform', activation='linear', weights=None,
|
||||
border_mode='valid', subsample=(1, 1, 1), dim_ordering='th',
|
||||
W_regularizer=None, b_regularizer=None, activity_regularizer=None,
|
||||
W_constraint=None, b_constraint=None, **kwargs):
|
||||
if K._BACKEND != 'theano':
|
||||
raise Exception(self.__class__.__name__ +
|
||||
' is currently only working with Theano backend.')
|
||||
if border_mode not in {'valid', 'same'}:
|
||||
raise Exception('Invalid border mode for Convolution3D:', border_mode)
|
||||
self.nb_filter = nb_filter
|
||||
self.kernel_dim1 = kernel_dim1
|
||||
self.kernel_dim2 = kernel_dim2
|
||||
self.kernel_dim3 = kernel_dim3
|
||||
self.init = initializations.get(init, dim_ordering=dim_ordering)
|
||||
self.activation = activations.get(activation)
|
||||
assert border_mode in {'valid', 'same'}, 'border_mode must be in {valid, same}'
|
||||
self.border_mode = border_mode
|
||||
self.subsample = tuple(subsample)
|
||||
assert dim_ordering in {'tf', 'th'}, 'dim_ordering must be in {tf, th}'
|
||||
self.dim_ordering = dim_ordering
|
||||
|
||||
self.W_regularizer = regularizers.get(W_regularizer)
|
||||
self.b_regularizer = regularizers.get(b_regularizer)
|
||||
self.activity_regularizer = regularizers.get(activity_regularizer)
|
||||
|
||||
self.W_constraint = constraints.get(W_constraint)
|
||||
self.b_constraint = constraints.get(b_constraint)
|
||||
self.constraints = [self.W_constraint, self.b_constraint]
|
||||
|
||||
self.initial_weights = weights
|
||||
super(Convolution3D, self).__init__(**kwargs)
|
||||
|
||||
def build(self):
|
||||
|
||||
if self.dim_ordering == 'th':
|
||||
stack_size = self.input_shape[1]
|
||||
self.W_shape = (self.nb_filter, stack_size,
|
||||
self.kernel_dim1, self.kernel_dim2, self.kernel_dim3)
|
||||
elif self.dim_ordering == 'tf':
|
||||
stack_size = self.input_shape[4]
|
||||
self.W_shape = (self.kernel_dim1, self.kernel_dim2, self.kernel_dim3,
|
||||
stack_size, self.nb_filter)
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + self.dim_ordering)
|
||||
|
||||
self.W = self.init(self.W_shape, name='{}_W'.format(self.name))
|
||||
self.b = K.zeros((self.nb_filter,), name='{}_b'.format(self.name))
|
||||
self.trainable_weights = [self.W, self.b]
|
||||
self.regularizers = []
|
||||
|
||||
if self.W_regularizer:
|
||||
self.W_regularizer.set_param(self.W)
|
||||
self.regularizers.append(self.W_regularizer)
|
||||
|
||||
if self.b_regularizer:
|
||||
self.b_regularizer.set_param(self.b)
|
||||
self.regularizers.append(self.b_regularizer)
|
||||
|
||||
if self.activity_regularizer:
|
||||
self.activity_regularizer.set_layer(self)
|
||||
self.regularizers.append(self.activity_regularizer)
|
||||
|
||||
if self.initial_weights is not None:
|
||||
self.set_weights(self.initial_weights)
|
||||
del self.initial_weights
|
||||
|
||||
@property
|
||||
def output_shape(self):
|
||||
input_shape = self.input_shape
|
||||
if self.dim_ordering == 'th':
|
||||
conv_dim1 = input_shape[2]
|
||||
conv_dim2 = input_shape[3]
|
||||
conv_dim3 = input_shape[4]
|
||||
elif self.dim_ordering == 'tf':
|
||||
conv_dim1 = input_shape[1]
|
||||
conv_dim2 = input_shape[2]
|
||||
conv_dim3 = input_shape[3]
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + self.dim_ordering)
|
||||
|
||||
conv_dim1 = conv_output_length(conv_dim1, self.kernel_dim1,
|
||||
self.border_mode, self.subsample[0])
|
||||
conv_dim2 = conv_output_length(conv_dim2, self.kernel_dim2,
|
||||
self.border_mode, self.subsample[1])
|
||||
conv_dim3 = conv_output_length(conv_dim3, self.kernel_dim3,
|
||||
self.border_mode, self.subsample[2])
|
||||
|
||||
if self.dim_ordering == 'th':
|
||||
return (input_shape[0], self.nb_filter, conv_dim1, conv_dim2, conv_dim3)
|
||||
elif self.dim_ordering == 'tf':
|
||||
return (input_shape[0], conv_dim1, conv_dim2, conv_dim3, self.nb_filter)
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + self.dim_ordering)
|
||||
|
||||
def get_output(self, train=False):
|
||||
X = self.get_input(train)
|
||||
conv_out = K.conv3d(X, self.W, strides=self.subsample,
|
||||
border_mode=self.border_mode,
|
||||
dim_ordering=self.dim_ordering,
|
||||
volume_shape=self.input_shape,
|
||||
filter_shape=self.W_shape)
|
||||
|
||||
if self.dim_ordering == 'th':
|
||||
output = conv_out + K.reshape(self.b, (1, self.nb_filter, 1, 1, 1))
|
||||
elif self.dim_ordering == 'tf':
|
||||
output = conv_out + K.reshape(self.b, (1, 1, 1, 1, self.nb_filter))
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + self.dim_ordering)
|
||||
output = self.activation(output)
|
||||
return output
|
||||
|
||||
def get_config(self):
|
||||
config = {"name": self.__class__.__name__,
|
||||
"nb_filter": self.nb_filter,
|
||||
"kernel_dim1": self.kernel_dim1,
|
||||
"kernel_dim2": self.kernel_dim2,
|
||||
"kernel_dim3": self.kernel_dim3,
|
||||
"dim_ordering": self.dim_ordering,
|
||||
"init": self.init.__name__,
|
||||
"activation": self.activation.__name__,
|
||||
"border_mode": self.border_mode,
|
||||
"subsample": self.subsample,
|
||||
"W_regularizer": self.W_regularizer.get_config() if self.W_regularizer else None,
|
||||
"b_regularizer": self.b_regularizer.get_config() if self.b_regularizer else None,
|
||||
"activity_regularizer": self.activity_regularizer.get_config() if self.activity_regularizer else None,
|
||||
"W_constraint": self.W_constraint.get_config() if self.W_constraint else None,
|
||||
"b_constraint": self.b_constraint.get_config() if self.b_constraint else None}
|
||||
base_config = super(Convolution3D, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
|
||||
class _Pooling1D(Layer):
|
||||
'''Abstract class for different pooling 1D layers.
|
||||
'''
|
||||
@@ -356,7 +543,6 @@ class _Pooling1D(Layer):
|
||||
self.pool_length = pool_length
|
||||
self.stride = stride
|
||||
self.st = (self.stride, 1)
|
||||
self.input = K.placeholder(ndim=3)
|
||||
self.pool_size = (pool_length, 1)
|
||||
assert border_mode in {'valid', 'same'}, 'border_mode must be in {valid, same}'
|
||||
self.border_mode = border_mode
|
||||
@@ -407,6 +593,7 @@ class MaxPooling1D(_Pooling1D):
|
||||
border_mode: 'valid' or 'same'.
|
||||
Note: 'same' will only work with TensorFlow for the time being.
|
||||
'''
|
||||
|
||||
def __init__(self, pool_length=2, stride=None,
|
||||
border_mode='valid', **kwargs):
|
||||
super(MaxPooling1D, self).__init__(pool_length, stride,
|
||||
@@ -434,6 +621,7 @@ class AveragePooling1D(_Pooling1D):
|
||||
border_mode: 'valid' or 'same'.
|
||||
Note: 'same' will only work with TensorFlow for the time being.
|
||||
'''
|
||||
|
||||
def __init__(self, pool_length=2, stride=None,
|
||||
border_mode='valid', **kwargs):
|
||||
super(AveragePooling1D, self).__init__(pool_length, stride,
|
||||
@@ -454,7 +642,6 @@ class _Pooling2D(Layer):
|
||||
def __init__(self, pool_size=(2, 2), strides=None, border_mode='valid',
|
||||
dim_ordering='th', **kwargs):
|
||||
super(_Pooling2D, self).__init__(**kwargs)
|
||||
self.input = K.placeholder(ndim=4)
|
||||
self.pool_size = tuple(pool_size)
|
||||
if strides is None:
|
||||
strides = self.pool_size
|
||||
@@ -535,6 +722,7 @@ class MaxPooling2D(_Pooling2D):
|
||||
dim_ordering: 'th' or 'tf'. In 'th' mode, the channels dimension
|
||||
(the depth) is at index 1, in 'tf' mode is it at index 3.
|
||||
'''
|
||||
|
||||
def __init__(self, pool_size=(2, 2), strides=None, border_mode='valid',
|
||||
dim_ordering='th', **kwargs):
|
||||
super(MaxPooling2D, self).__init__(pool_size, strides, border_mode,
|
||||
@@ -572,6 +760,7 @@ class AveragePooling2D(_Pooling2D):
|
||||
dim_ordering: 'th' or 'tf'. In 'th' mode, the channels dimension
|
||||
(the depth) is at index 1, in 'tf' mode is it at index 3.
|
||||
'''
|
||||
|
||||
def __init__(self, pool_size=(2, 2), strides=None, border_mode='valid',
|
||||
dim_ordering='th', **kwargs):
|
||||
super(AveragePooling2D, self).__init__(pool_size, strides, border_mode,
|
||||
@@ -584,6 +773,157 @@ class AveragePooling2D(_Pooling2D):
|
||||
return output
|
||||
|
||||
|
||||
class _Pooling3D(Layer):
|
||||
'''Abstract class for different pooling 3D layers.
|
||||
'''
|
||||
input_ndim = 5
|
||||
|
||||
def __init__(self, pool_size=(2, 2, 2), strides=None, border_mode='valid',
|
||||
dim_ordering='th', **kwargs):
|
||||
super(_Pooling3D, self).__init__(**kwargs)
|
||||
self.pool_size = tuple(pool_size)
|
||||
if strides is None:
|
||||
strides = self.pool_size
|
||||
self.strides = tuple(strides)
|
||||
assert border_mode in {'valid', 'same'}, 'border_mode must be in {valid, same}'
|
||||
self.border_mode = border_mode
|
||||
assert dim_ordering in {'tf', 'th'}, 'dim_ordering must be in {tf, th}'
|
||||
self.dim_ordering = dim_ordering
|
||||
|
||||
@property
|
||||
def output_shape(self):
|
||||
input_shape = self.input_shape
|
||||
if self.dim_ordering == 'th':
|
||||
len_dim1 = input_shape[2]
|
||||
len_dim2 = input_shape[3]
|
||||
len_dim3 = input_shape[4]
|
||||
elif self.dim_ordering == 'tf':
|
||||
len_dim1 = input_shape[1]
|
||||
len_dim2 = input_shape[2]
|
||||
len_dim3 = input_shape[3]
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + self.dim_ordering)
|
||||
|
||||
len_dim1 = conv_output_length(len_dim1, self.pool_size[0],
|
||||
self.border_mode, self.strides[0])
|
||||
len_dim2 = conv_output_length(len_dim2, self.pool_size[1],
|
||||
self.border_mode, self.strides[1])
|
||||
len_dim3 = conv_output_length(len_dim3, self.pool_size[2],
|
||||
self.border_mode, self.strides[2])
|
||||
|
||||
if self.dim_ordering == 'th':
|
||||
return (input_shape[0], input_shape[1], len_dim1, len_dim2, len_dim3)
|
||||
elif self.dim_ordering == 'tf':
|
||||
return (input_shape[0], len_dim1, len_dim2, len_dim3, input_shape[4])
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + self.dim_ordering)
|
||||
|
||||
def _pooling_function(self, inputs, pool_size, strides,
|
||||
border_mode, dim_ordering):
|
||||
raise NotImplementedError
|
||||
|
||||
def get_output(self, train=False):
|
||||
X = self.get_input(train)
|
||||
output = self._pooling_function(inputs=X, pool_size=self.pool_size,
|
||||
strides=self.strides,
|
||||
border_mode=self.border_mode,
|
||||
dim_ordering=self.dim_ordering)
|
||||
return output
|
||||
|
||||
def get_config(self):
|
||||
config = {'name': self.__class__.__name__,
|
||||
'pool_size': self.pool_size,
|
||||
'border_mode': self.border_mode,
|
||||
'strides': self.strides,
|
||||
'dim_ordering': self.dim_ordering}
|
||||
base_config = super(_Pooling3D, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
|
||||
class MaxPooling3D(_Pooling3D):
|
||||
'''Max pooling operation for 3D data (spatial or spatio-temporal).
|
||||
|
||||
Note: this layer will only work with Theano for the time being.
|
||||
|
||||
# Input shape
|
||||
5D tensor with shape:
|
||||
`(samples, channels, len_pool_dim1, len_pool_dim2, len_pool_dim3)` if dim_ordering='th'
|
||||
or 5D tensor with shape:
|
||||
`(samples, len_pool_dim1, len_pool_dim2, len_pool_dim3, channels)` if dim_ordering='tf'.
|
||||
|
||||
# Output shape
|
||||
5D tensor with shape:
|
||||
`(nb_samples, channels, pooled_dim1, pooled_dim2, pooled_dim3)` if dim_ordering='th'
|
||||
or 5D tensor with shape:
|
||||
`(samples, pooled_dim1, pooled_dim2, pooled_dim3, channels)` if dim_ordering='tf'.
|
||||
|
||||
# Arguments
|
||||
pool_size: tuple of 3 integers,
|
||||
factors by which to downscale (dim1, dim2, dim3).
|
||||
(2, 2, 2) will halve the size of the 3D input in each dimension.
|
||||
strides: tuple of 3 integers, or None. Strides values.
|
||||
border_mode: 'valid' or 'same'.
|
||||
dim_ordering: 'th' or 'tf'. In 'th' mode, the channels dimension
|
||||
(the depth) is at index 1, in 'tf' mode is it at index 4.
|
||||
'''
|
||||
|
||||
def __init__(self, pool_size=(2, 2, 2), strides=None, border_mode='valid',
|
||||
dim_ordering='th', **kwargs):
|
||||
if K._BACKEND != 'theano':
|
||||
raise Exception(self.__class__.__name__ +
|
||||
' is currently only working with Theano backend.')
|
||||
super(MaxPooling3D, self).__init__(pool_size, strides, border_mode,
|
||||
dim_ordering, **kwargs)
|
||||
|
||||
def _pooling_function(self, inputs, pool_size, strides,
|
||||
border_mode, dim_ordering):
|
||||
output = K.pool3d(inputs, pool_size, strides,
|
||||
border_mode, dim_ordering, pool_mode='max')
|
||||
return output
|
||||
|
||||
|
||||
class AveragePooling3D(_Pooling3D):
|
||||
'''Average pooling operation for 3D data (spatial or spatio-temporal).
|
||||
|
||||
Note: this layer will only work with Theano for the time being.
|
||||
|
||||
# Input shape
|
||||
5D tensor with shape:
|
||||
`(samples, channels, len_pool_dim1, len_pool_dim2, len_pool_dim3)` if dim_ordering='th'
|
||||
or 5D tensor with shape:
|
||||
`(samples, len_pool_dim1, len_pool_dim2, len_pool_dim3, channels)` if dim_ordering='tf'.
|
||||
|
||||
# Output shape
|
||||
5D tensor with shape:
|
||||
`(nb_samples, channels, pooled_dim1, pooled_dim2, pooled_dim3)` if dim_ordering='th'
|
||||
or 5D tensor with shape:
|
||||
`(samples, pooled_dim1, pooled_dim2, pooled_dim3, channels)` if dim_ordering='tf'.
|
||||
|
||||
# Arguments
|
||||
pool_size: tuple of 3 integers,
|
||||
factors by which to downscale (dim1, dim2, dim3).
|
||||
(2, 2, 2) will halve the size of the 3D input in each dimension.
|
||||
strides: tuple of 3 integers, or None. Strides values.
|
||||
border_mode: 'valid' or 'same'.
|
||||
dim_ordering: 'th' or 'tf'. In 'th' mode, the channels dimension
|
||||
(the depth) is at index 1, in 'tf' mode is it at index 4.
|
||||
'''
|
||||
|
||||
def __init__(self, pool_size=(2, 2, 2), strides=None, border_mode='valid',
|
||||
dim_ordering='th', **kwargs):
|
||||
if K._BACKEND != 'theano':
|
||||
raise Exception(self.__class__.__name__ +
|
||||
' is currently only working with Theano backend.')
|
||||
super(AveragePooling3D, self).__init__(pool_size, strides, border_mode,
|
||||
dim_ordering, **kwargs)
|
||||
|
||||
def _pooling_function(self, inputs, pool_size, strides,
|
||||
border_mode, dim_ordering):
|
||||
output = K.pool3d(inputs, pool_size, strides,
|
||||
border_mode, dim_ordering, pool_mode='avg')
|
||||
return output
|
||||
|
||||
|
||||
class UpSampling1D(Layer):
|
||||
'''Repeat each temporal step `length` times along the time axis.
|
||||
|
||||
@@ -601,7 +941,6 @@ class UpSampling1D(Layer):
|
||||
def __init__(self, length=2, **kwargs):
|
||||
super(UpSampling1D, self).__init__(**kwargs)
|
||||
self.length = length
|
||||
self.input = K.placeholder(ndim=3)
|
||||
|
||||
@property
|
||||
def output_shape(self):
|
||||
@@ -646,7 +985,6 @@ class UpSampling2D(Layer):
|
||||
|
||||
def __init__(self, size=(2, 2), dim_ordering='th', **kwargs):
|
||||
super(UpSampling2D, self).__init__(**kwargs)
|
||||
self.input = K.placeholder(ndim=4)
|
||||
self.size = tuple(size)
|
||||
assert dim_ordering in {'tf', 'th'}, 'dim_ordering must be in {tf, th}'
|
||||
self.dim_ordering = dim_ordering
|
||||
@@ -679,6 +1017,71 @@ class UpSampling2D(Layer):
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
|
||||
class UpSampling3D(Layer):
|
||||
'''Repeat the first, second and third dimension of the data
|
||||
by size[0], size[1] and size[2] respectively.
|
||||
|
||||
Note: this layer will only work with Theano for the time being.
|
||||
|
||||
# Input shape
|
||||
5D tensor with shape:
|
||||
`(samples, channels, dim1, dim2, dim3)` if dim_ordering='th'
|
||||
or 5D tensor with shape:
|
||||
`(samples, dim1, dim2, dim3, channels)` if dim_ordering='tf'.
|
||||
|
||||
# Output shape
|
||||
5D tensor with shape:
|
||||
`(samples, channels, upsampled_dim1, upsampled_dim2, upsampled_dim3)` if dim_ordering='th'
|
||||
or 5D tensor with shape:
|
||||
`(samples, upsampled_dim1, upsampled_dim2, upsampled_dim3, channels)` if dim_ordering='tf'.
|
||||
|
||||
# Arguments
|
||||
size: tuple of 3 integers. The upsampling factors for dim1, dim2 and dim3.
|
||||
dim_ordering: 'th' or 'tf'.
|
||||
In 'th' mode, the channels dimension (the depth)
|
||||
is at index 1, in 'tf' mode is it at index 4.
|
||||
'''
|
||||
input_ndim = 5
|
||||
|
||||
def __init__(self, size=(2, 2, 2), dim_ordering='th', **kwargs):
|
||||
if K._BACKEND != 'theano':
|
||||
raise Exception(self.__class__.__name__ +
|
||||
' is currently only working with Theano backend.')
|
||||
super(UpSampling3D, self).__init__(**kwargs)
|
||||
self.size = tuple(size)
|
||||
assert dim_ordering in {'tf', 'th'}, 'dim_ordering must be in {tf, th}'
|
||||
self.dim_ordering = dim_ordering
|
||||
|
||||
@property
|
||||
def output_shape(self):
|
||||
input_shape = self.input_shape
|
||||
if self.dim_ordering == 'th':
|
||||
return (input_shape[0],
|
||||
input_shape[1],
|
||||
self.size[0] * input_shape[2],
|
||||
self.size[1] * input_shape[3],
|
||||
self.size[2] * input_shape[4])
|
||||
elif self.dim_ordering == 'tf':
|
||||
return (input_shape[0],
|
||||
self.size[0] * input_shape[1],
|
||||
self.size[1] * input_shape[2],
|
||||
self.size[2] * input_shape[3],
|
||||
input_shape[4])
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + self.dim_ordering)
|
||||
|
||||
def get_output(self, train=False):
|
||||
X = self.get_input(train)
|
||||
return K.resize_volumes(X, self.size[0], self.size[1], self.size[2],
|
||||
self.dim_ordering)
|
||||
|
||||
def get_config(self):
|
||||
config = {'name': self.__class__.__name__,
|
||||
'size': self.size}
|
||||
base_config = super(UpSampling3D, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
|
||||
class ZeroPadding1D(Layer):
|
||||
'''Zero-padding layer for 1D input (e.g. temporal sequence).
|
||||
|
||||
@@ -698,13 +1101,13 @@ class ZeroPadding1D(Layer):
|
||||
def __init__(self, padding=1, **kwargs):
|
||||
super(ZeroPadding1D, self).__init__(**kwargs)
|
||||
self.padding = padding
|
||||
self.input = K.placeholder(ndim=3)
|
||||
|
||||
@property
|
||||
def output_shape(self):
|
||||
input_shape = self.input_shape
|
||||
length = input_shape[1] + self.padding * 2 if input_shape[1] is not None else None
|
||||
return (input_shape[0],
|
||||
input_shape[1] + self.padding * 2,
|
||||
length,
|
||||
input_shape[2])
|
||||
|
||||
def get_output(self, train=False):
|
||||
@@ -739,7 +1142,6 @@ class ZeroPadding2D(Layer):
|
||||
def __init__(self, padding=(1, 1), dim_ordering='th', **kwargs):
|
||||
super(ZeroPadding2D, self).__init__(**kwargs)
|
||||
self.padding = tuple(padding)
|
||||
self.input = K.placeholder(ndim=4)
|
||||
assert dim_ordering in {'tf', 'th'}, 'dim_ordering must be in {tf, th}'
|
||||
self.dim_ordering = dim_ordering
|
||||
|
||||
@@ -747,14 +1149,18 @@ class ZeroPadding2D(Layer):
|
||||
def output_shape(self):
|
||||
input_shape = self.input_shape
|
||||
if self.dim_ordering == 'th':
|
||||
width = input_shape[2] + 2 * self.padding[0] if input_shape[2] is not None else None
|
||||
height = input_shape[3] + 2 * self.padding[1] if input_shape[3] is not None else None
|
||||
return (input_shape[0],
|
||||
input_shape[1],
|
||||
input_shape[2] + 2 * self.padding[0],
|
||||
input_shape[3] + 2 * self.padding[1])
|
||||
width,
|
||||
height)
|
||||
elif self.dim_ordering == 'tf':
|
||||
width = input_shape[1] + 2 * self.padding[0] if input_shape[1] is not None else None
|
||||
height = input_shape[2] + 2 * self.padding[1] if input_shape[2] is not None else None
|
||||
return (input_shape[0],
|
||||
input_shape[1] + 2 * self.padding[0],
|
||||
input_shape[2] + 2 * self.padding[1],
|
||||
width,
|
||||
height,
|
||||
input_shape[3])
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + self.dim_ordering)
|
||||
@@ -769,3 +1175,68 @@ class ZeroPadding2D(Layer):
|
||||
'padding': self.padding}
|
||||
base_config = super(ZeroPadding2D, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
|
||||
class ZeroPadding3D(Layer):
|
||||
'''Zero-padding layer for 3D data (spatial or spatio-temporal).
|
||||
|
||||
Note: this layer will only work with Theano for the time being.
|
||||
|
||||
# Input shape
|
||||
5D tensor with shape:
|
||||
(samples, depth, first_axis_to_pad, second_axis_to_pad, third_axis_to_pad)
|
||||
|
||||
# Output shape
|
||||
5D tensor with shape:
|
||||
(samples, depth, first_padded_axis, second_padded_axis, third_axis_to_pad)
|
||||
|
||||
# Arguments
|
||||
padding: tuple of int (length 3)
|
||||
How many zeros to add at the beginning and end of
|
||||
the 3 padding dimensions (axis 3, 4 and 5).
|
||||
'''
|
||||
input_ndim = 5
|
||||
|
||||
def __init__(self, padding=(1, 1, 1), dim_ordering='th', **kwargs):
|
||||
if K._BACKEND != 'theano':
|
||||
raise Exception(self.__class__.__name__ +
|
||||
' is currently only working with Theano backend.')
|
||||
super(ZeroPadding3D, self).__init__(**kwargs)
|
||||
self.padding = tuple(padding)
|
||||
assert dim_ordering in {'tf', 'th'}, 'dim_ordering must be in {tf, th}'
|
||||
self.dim_ordering = dim_ordering
|
||||
|
||||
@property
|
||||
def output_shape(self):
|
||||
input_shape = self.input_shape
|
||||
if self.dim_ordering == 'th':
|
||||
dim1 = input_shape[2] + 2 * self.padding[0] if input_shape[2] is not None else None
|
||||
dim2 = input_shape[3] + 2 * self.padding[1] if input_shape[3] is not None else None
|
||||
dim3 = input_shape[4] + 2 * self.padding[2] if input_shape[4] is not None else None
|
||||
return (input_shape[0],
|
||||
input_shape[1],
|
||||
dim1,
|
||||
dim2,
|
||||
dim3)
|
||||
elif self.dim_ordering == 'tf':
|
||||
dim1 = input_shape[1] + 2 * self.padding[0] if input_shape[1] is not None else None
|
||||
dim2 = input_shape[2] + 2 * self.padding[1] if input_shape[2] is not None else None
|
||||
dim3 = input_shape[3] + 2 * self.padding[2] if input_shape[3] is not None else None
|
||||
return (input_shape[0],
|
||||
dim1,
|
||||
dim2,
|
||||
dim3,
|
||||
input_shape[4])
|
||||
else:
|
||||
raise Exception('Invalid dim_ordering: ' + self.dim_ordering)
|
||||
|
||||
def get_output(self, train=False):
|
||||
X = self.get_input(train)
|
||||
return K.spatial_3d_padding(X, padding=self.padding,
|
||||
dim_ordering=self.dim_ordering)
|
||||
|
||||
def get_config(self):
|
||||
config = {'name': self.__class__.__name__,
|
||||
'padding': self.padding}
|
||||
base_config = super(ZeroPadding3D, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
+229
-139
@@ -12,9 +12,7 @@ from .. import backend as K
|
||||
from .. import activations, initializations, regularizers, constraints
|
||||
from ..regularizers import ActivityRegularizer
|
||||
|
||||
import marshal
|
||||
import types
|
||||
import sys
|
||||
import inspect
|
||||
|
||||
|
||||
class Layer(object):
|
||||
@@ -45,19 +43,26 @@ class Layer(object):
|
||||
'name'}
|
||||
for kwarg in kwargs:
|
||||
assert kwarg in allowed_kwargs, 'Keyword argument not understood: ' + kwarg
|
||||
|
||||
if 'name' in kwargs:
|
||||
self.name = kwargs['name']
|
||||
else:
|
||||
self.name = self.__class__.__name__.lower()
|
||||
|
||||
if 'cache_enabled' in kwargs:
|
||||
self.cache_enabled = kwargs['cache_enabled']
|
||||
else:
|
||||
self.cache_enabled = True
|
||||
|
||||
if 'batch_input_shape' in kwargs:
|
||||
self.set_input_shape(tuple(kwargs['batch_input_shape']))
|
||||
elif 'input_shape' in kwargs:
|
||||
self.set_input_shape((None,) + tuple(kwargs['input_shape']))
|
||||
self.trainable = True
|
||||
|
||||
if 'trainable' in kwargs:
|
||||
self.trainable = kwargs['trainable']
|
||||
self.name = self.__class__.__name__.lower()
|
||||
if 'name' in kwargs:
|
||||
self.name = kwargs['name']
|
||||
self.cache_enabled = True
|
||||
if 'cache_enabled' in kwargs:
|
||||
self.cache_enabled = kwargs['cache_enabled']
|
||||
else:
|
||||
self.trainable = True
|
||||
|
||||
@property
|
||||
def name(self):
|
||||
@@ -75,22 +80,56 @@ class Layer(object):
|
||||
def cache_enabled(self, value):
|
||||
self._cache_enabled = value
|
||||
|
||||
@property
|
||||
def layer_cache(self):
|
||||
if hasattr(self, '_layer_cache'):
|
||||
return self._layer_cache
|
||||
else:
|
||||
return None
|
||||
|
||||
@layer_cache.setter
|
||||
def layer_cache(self, value):
|
||||
self._layer_cache = value
|
||||
|
||||
@property
|
||||
def shape_cache(self):
|
||||
if hasattr(self, '_shape_cache'):
|
||||
return self._shape_cache
|
||||
else:
|
||||
return None
|
||||
|
||||
@shape_cache.setter
|
||||
def shape_cache(self, value):
|
||||
self._shape_cache = value
|
||||
|
||||
def __call__(self, X, mask=None, train=False):
|
||||
# set temporary input
|
||||
tmp_input = self.get_input
|
||||
tmp_mask = None
|
||||
# reset layer cache temporarily
|
||||
tmp_layer_cache = self.layer_cache
|
||||
tmp_shape_cache = self.shape_cache
|
||||
self.layer_cache = {}
|
||||
self.shape_cache = {}
|
||||
# create a temporary layer
|
||||
layer = Layer(batch_input_shape=self.input_shape)
|
||||
layer.name = "dummy"
|
||||
layer.input = X
|
||||
if hasattr(self, 'get_input_mask'):
|
||||
tmp_mask = self.get_input_mask
|
||||
self.get_input_mask = lambda _: mask
|
||||
self.get_input = lambda _: X
|
||||
layer.get_input_mask = lambda _: mask
|
||||
# set temporary previous
|
||||
tmp_previous = None
|
||||
if hasattr(self, 'previous'):
|
||||
tmp_previous = self.previous
|
||||
self.set_previous(layer, False)
|
||||
Y = self.get_output(train=train)
|
||||
# return input to what it was
|
||||
if hasattr(self, 'get_input_mask'):
|
||||
self.get_input_mask = tmp_mask
|
||||
self.get_input = tmp_input
|
||||
# return previous to what it was
|
||||
if tmp_previous is not None:
|
||||
self.set_previous(tmp_previous, False)
|
||||
else:
|
||||
self.clear_previous(False)
|
||||
self.layer_cache = tmp_layer_cache
|
||||
self.shape_cache = tmp_shape_cache
|
||||
return Y
|
||||
|
||||
def set_previous(self, layer):
|
||||
def set_previous(self, layer, reset_weights=True):
|
||||
'''Connect a layer to its parent in the computational graph.
|
||||
'''
|
||||
assert self.nb_input == layer.nb_output == 1, 'Cannot connect layers: input count and output count should be 1.'
|
||||
@@ -101,8 +140,27 @@ class Layer(object):
|
||||
str(layer.output_shape))
|
||||
if layer.get_output_mask() is not None:
|
||||
assert self.supports_masked_input(), 'Cannot connect non-masking layer to layer with masked output.'
|
||||
if not reset_weights:
|
||||
assert layer.output_shape == self.input_shape, ('Cannot connect layers without resetting weights: ' +
|
||||
'expected input with shape ' +
|
||||
str(self.input_shape) +
|
||||
' but previous layer has output_shape ' +
|
||||
str(layer.output_shape))
|
||||
self.previous = layer
|
||||
self.build()
|
||||
if reset_weights:
|
||||
self.build()
|
||||
|
||||
def clear_previous(self, reset_weights=True):
|
||||
'''Unlink a layer from its parent in the computational graph.
|
||||
|
||||
This is only allowed if the layer has an `input` attribute.
|
||||
'''
|
||||
if not hasattr(self, 'input'):
|
||||
raise Exception('Cannot clear previous for non-input layers')
|
||||
if hasattr(self, 'previous'):
|
||||
del self.previous
|
||||
if reset_weights:
|
||||
self.build()
|
||||
|
||||
def build(self):
|
||||
'''Instantiation of layer weights.
|
||||
@@ -137,7 +195,15 @@ class Layer(object):
|
||||
# if layer is not connected (e.g. input layer),
|
||||
# input shape can be set manually via _input_shape attribute.
|
||||
if hasattr(self, 'previous'):
|
||||
return self.previous.output_shape
|
||||
if self.shape_cache is not None and self.cache_enabled:
|
||||
previous_layer_id = id(self.previous)
|
||||
if previous_layer_id in self.shape_cache:
|
||||
return self.shape_cache[previous_layer_id]
|
||||
previous_size = self.previous.output_shape
|
||||
if self.shape_cache is not None and self.cache_enabled:
|
||||
previous_layer_id = id(self.previous)
|
||||
self.shape_cache[previous_layer_id] = previous_size
|
||||
return previous_size
|
||||
elif hasattr(self, '_input_shape'):
|
||||
return self._input_shape
|
||||
else:
|
||||
@@ -168,20 +234,20 @@ class Layer(object):
|
||||
if hasattr(self, 'previous'):
|
||||
# to avoid redundant computations,
|
||||
# layer outputs are cached when possible.
|
||||
if hasattr(self, 'layer_cache') and self.cache_enabled:
|
||||
if self.layer_cache is not None and self.cache_enabled:
|
||||
previous_layer_id = '%s_%s' % (id(self.previous), train)
|
||||
if previous_layer_id in self.layer_cache:
|
||||
return self.layer_cache[previous_layer_id]
|
||||
previous_output = self.previous.get_output(train=train)
|
||||
if hasattr(self, 'layer_cache') and self.cache_enabled:
|
||||
if self.layer_cache is not None and self.cache_enabled:
|
||||
previous_layer_id = '%s_%s' % (id(self.previous), train)
|
||||
self.layer_cache[previous_layer_id] = previous_output
|
||||
return previous_output
|
||||
elif hasattr(self, 'input'):
|
||||
return self.input
|
||||
else:
|
||||
raise Exception('Layer is not connected' +
|
||||
' and is not an input layer.')
|
||||
self.input = K.placeholder(shape=self.input_shape)
|
||||
return self.input
|
||||
|
||||
def supports_masked_input(self):
|
||||
'''Whether or not this layer respects the output mask of its previous
|
||||
@@ -230,7 +296,7 @@ class Layer(object):
|
||||
str(len(weights)) + ' provided weights)')
|
||||
for p, w in zip(params, weights):
|
||||
if K.get_value(p).shape != w.shape:
|
||||
raise Exception('Layer shape %s not compatible with weight shape %s.' % (K.get_value(p).shape, w.shape))
|
||||
raise Exception('Layer weight shape %s not compatible with provided weight shape %s.' % (K.get_value(p).shape, w.shape))
|
||||
K.set_value(p, w)
|
||||
|
||||
def get_weights(self):
|
||||
@@ -327,8 +393,6 @@ class Masking(MaskedLayer):
|
||||
def __init__(self, mask_value=0., **kwargs):
|
||||
super(Masking, self).__init__(**kwargs)
|
||||
self.mask_value = mask_value
|
||||
if (not hasattr(self, 'input')):
|
||||
self.input = K.placeholder(ndim=3)
|
||||
|
||||
def get_output_mask(self, train=False):
|
||||
X = self.get_input(train)
|
||||
@@ -349,18 +413,16 @@ class Merge(Layer):
|
||||
'''Merge the output of a list of layers or containers into a single tensor.
|
||||
|
||||
# Arguments
|
||||
mode: one of {sum, mul, concat, ave, dot}.
|
||||
mode: one of {sum, mul, concat, ave, join, cos, dot}.
|
||||
sum: sum the outputs (shapes must match)
|
||||
mul: multiply the outputs element-wise (shapes must match)
|
||||
concat: concatenate the outputs along the axis specified by `concat_axis`
|
||||
ave: average the outputs (shapes must match)
|
||||
join: places the outputs in an OrderedDict (inputs must be named)
|
||||
concat_axis: axis to use in `concat` mode.
|
||||
dot_axes: axis or axes to use in `dot` mode
|
||||
(see [the Numpy documentation](http://docs.scipy.org/doc/numpy-1.10.1/reference/generated/numpy.tensordot.html) for more details).
|
||||
|
||||
# TensorFlow warning
|
||||
`dot` mode only works with Theano for the time being.
|
||||
|
||||
# Examples
|
||||
|
||||
```python
|
||||
@@ -399,9 +461,6 @@ class Merge(Layer):
|
||||
'be merged using ' + mode + ' mode. ' +
|
||||
'Layer shapes: %s' % ([l.output_shape for l in layers]))
|
||||
if mode in {'cos', 'dot'}:
|
||||
if K._BACKEND != 'theano':
|
||||
raise Exception('"' + mode + '" merge mode will only work with Theano.')
|
||||
|
||||
if len(layers) > 2:
|
||||
raise Exception(mode + ' merge takes exactly 2 layers')
|
||||
shape1 = layers[0].output_shape
|
||||
@@ -455,6 +514,10 @@ class Merge(Layer):
|
||||
self.constraints.append(c)
|
||||
super(Merge, self).__init__()
|
||||
|
||||
@property
|
||||
def input_shape(self):
|
||||
return [layer.input_shape for layer in self.layers]
|
||||
|
||||
@property
|
||||
def output_shape(self):
|
||||
input_shapes = [layer.output_shape for layer in self.layers]
|
||||
@@ -514,23 +577,18 @@ class Merge(Layer):
|
||||
s *= self.layers[i].get_output(train)
|
||||
return s
|
||||
elif self.mode == 'dot':
|
||||
if K._BACKEND != 'theano':
|
||||
raise Exception('"dot" merge mode will only work with Theano.')
|
||||
from theano import tensor as T
|
||||
l1 = self.layers[0].get_output(train)
|
||||
l2 = self.layers[1].get_output(train)
|
||||
output = T.batched_tensordot(l1, l2, self.dot_axes)
|
||||
output = K.batch_dot(l1, l2, self.dot_axes)
|
||||
output_shape = list(self.output_shape)
|
||||
output_shape[0] = l1.shape[0]
|
||||
output = output.reshape(tuple(output_shape))
|
||||
output_shape[0] = -1
|
||||
output = K.reshape(output, (tuple(output_shape)))
|
||||
return output
|
||||
elif self.mode == 'cos':
|
||||
if K._BACKEND != 'theano':
|
||||
raise Exception('"dot" merge mode will only work with Theano.')
|
||||
import theano
|
||||
l1 = self.layers[0].get_output(train)
|
||||
l2 = self.layers[1].get_output(train)
|
||||
output = T.batched_tensordot(l1, l2, self.dot_axes) / T.sqrt(T.batched_tensordot(l1, l1, self.dot_axes) * T.batched_tensordot(l2, l2, self.dot_axes))
|
||||
output = K.batch_dot(l1, l2, self.dot_axes) / K.sqrt(
|
||||
K.batch_dot(l1, l1, self.dot_axes) * K.batch_dot(l2, l2, self.dot_axes))
|
||||
output = output.dimshuffle((0, 'x'))
|
||||
return output
|
||||
else:
|
||||
@@ -897,7 +955,8 @@ class Dense(Layer):
|
||||
If you don't specify anything, no activation is applied
|
||||
(ie. "linear" activation: a(x) = x).
|
||||
weights: list of numpy arrays to set as initial weights.
|
||||
The list should have 1 element, of shape `(input_dim, output_dim)`.
|
||||
The list should have 2 elements, of shape `(input_dim, output_dim)`
|
||||
and (output_dim,) for weights and biases respectively.
|
||||
W_regularizer: instance of [WeightRegularizer](../regularizers.md)
|
||||
(eg. L1 or L2 regularization), applied to the main weights matrix.
|
||||
b_regularizer: instance of [WeightRegularizer](../regularizers.md),
|
||||
@@ -934,14 +993,15 @@ class Dense(Layer):
|
||||
self.input_dim = input_dim
|
||||
if self.input_dim:
|
||||
kwargs['input_shape'] = (self.input_dim,)
|
||||
self.input = K.placeholder(ndim=2)
|
||||
super(Dense, self).__init__(**kwargs)
|
||||
|
||||
def build(self):
|
||||
input_dim = self.input_shape[1]
|
||||
|
||||
self.W = self.init((input_dim, self.output_dim))
|
||||
self.b = K.zeros((self.output_dim,))
|
||||
self.W = self.init((input_dim, self.output_dim),
|
||||
name='{}_W'.format(self.name))
|
||||
self.b = K.zeros((self.output_dim,),
|
||||
name='{}_b'.format(self.name))
|
||||
|
||||
self.trainable_weights = [self.W, self.b]
|
||||
|
||||
@@ -1009,7 +1069,8 @@ class TimeDistributedDense(MaskedLayer):
|
||||
If you don't specify anything, no activation is applied
|
||||
(ie. "linear" activation: a(x) = x).
|
||||
weights: list of numpy arrays to set as initial weights.
|
||||
The list should have 1 element, of shape `(input_dim, output_dim)`.
|
||||
The list should have 2 elements, of shape `(input_dim, output_dim)`
|
||||
and (output_dim,) for weights and biases respectively.
|
||||
W_regularizer: instance of [WeightRegularizer](../regularizers.md)
|
||||
(eg. L1 or L2 regularization), applied to the main weights matrix.
|
||||
b_regularizer: instance of [WeightRegularizer](../regularizers.md),
|
||||
@@ -1049,14 +1110,15 @@ class TimeDistributedDense(MaskedLayer):
|
||||
self.input_length = input_length
|
||||
if self.input_dim:
|
||||
kwargs['input_shape'] = (self.input_length, self.input_dim)
|
||||
self.input = K.placeholder(ndim=3)
|
||||
super(TimeDistributedDense, self).__init__(**kwargs)
|
||||
|
||||
def build(self):
|
||||
input_dim = self.input_shape[2]
|
||||
|
||||
self.W = self.init((input_dim, self.output_dim))
|
||||
self.b = K.zeros((self.output_dim,))
|
||||
self.W = self.init((input_dim, self.output_dim),
|
||||
name='{}_W'.format(self.name))
|
||||
self.b = K.zeros((self.output_dim,),
|
||||
name='{}_b'.format(self.name))
|
||||
|
||||
self.trainable_weights = [self.W, self.b]
|
||||
self.regularizers = []
|
||||
@@ -1083,17 +1145,18 @@ class TimeDistributedDense(MaskedLayer):
|
||||
return (input_shape[0], input_shape[1], self.output_dim)
|
||||
|
||||
def get_output(self, train=False):
|
||||
X = self.get_input(train)
|
||||
|
||||
def step(x, states):
|
||||
output = K.dot(x, self.W) + self.b
|
||||
return output, []
|
||||
|
||||
last_output, outputs, states = K.rnn(step, X,
|
||||
initial_states=[],
|
||||
mask=None)
|
||||
outputs = self.activation(outputs)
|
||||
return outputs
|
||||
X = self.get_input(train) # (samples, timesteps, input_dim)
|
||||
# Squash samples and timesteps into a single axis
|
||||
x = K.reshape(X, (-1, self.input_shape[-1])) # (samples * timesteps, input_dim)
|
||||
Y = K.dot(x, self.W) + self.b # (samples * timesteps, output_dim)
|
||||
# We have to reshape Y to (samples, timesteps, output_dim)
|
||||
input_length = self.input_shape[1]
|
||||
# Note: input_length will always be provided when using tensorflow backend.
|
||||
if not input_length:
|
||||
input_length = K.shape(X)[1]
|
||||
Y = K.reshape(Y, (-1, input_length, self.output_shape[-1])) # (samples, timesteps, output_dim)
|
||||
Y = self.activation(Y)
|
||||
return Y
|
||||
|
||||
def get_config(self):
|
||||
config = {'name': self.__class__.__name__,
|
||||
@@ -1203,7 +1266,9 @@ class AutoEncoder(Layer):
|
||||
|
||||
self._output_reconstruction = output_reconstruction
|
||||
self.encoder = encoder
|
||||
self.encoder.layer_cache = self.layer_cache
|
||||
self.decoder = decoder
|
||||
self.decoder.layer_cache = self.layer_cache
|
||||
|
||||
if output_reconstruction:
|
||||
self.decoder.set_previous(self.encoder)
|
||||
@@ -1241,8 +1306,30 @@ class AutoEncoder(Layer):
|
||||
self.trainable_weights.append(p)
|
||||
self.constraints.append(c)
|
||||
|
||||
def set_previous(self, node):
|
||||
self.encoder.set_previous(node)
|
||||
@property
|
||||
def layer_cache(self):
|
||||
return super(AutoEncoder, self).layer_cache
|
||||
|
||||
@layer_cache.setter
|
||||
def layer_cache(self, value):
|
||||
self._layer_cache = value
|
||||
self.encoder.layer_cache = self._layer_cache
|
||||
self.decoder.layer_cache = self._layer_cache
|
||||
|
||||
@property
|
||||
def shape_cache(self):
|
||||
return super(AutoEncoder, self).shape_cache
|
||||
|
||||
@shape_cache.setter
|
||||
def shape_cache(self, value):
|
||||
self._shape_cache = value
|
||||
self.encoder.shape_cache = self._shape_cache
|
||||
self.decoder.shape_cache = self._shape_cache
|
||||
|
||||
def set_previous(self, node, reset_weights=True):
|
||||
self.encoder.set_previous(node, reset_weights)
|
||||
if reset_weights:
|
||||
self.build()
|
||||
|
||||
def get_weights(self):
|
||||
weights = []
|
||||
@@ -1330,14 +1417,15 @@ class MaxoutDense(Layer):
|
||||
self.input_dim = input_dim
|
||||
if self.input_dim:
|
||||
kwargs['input_shape'] = (self.input_dim,)
|
||||
self.input = K.placeholder(ndim=2)
|
||||
super(MaxoutDense, self).__init__(**kwargs)
|
||||
|
||||
def build(self):
|
||||
input_dim = self.input_shape[1]
|
||||
|
||||
self.W = self.init((self.nb_feature, input_dim, self.output_dim))
|
||||
self.b = K.zeros((self.nb_feature, self.output_dim))
|
||||
self.W = self.init((self.nb_feature, input_dim, self.output_dim),
|
||||
name='{}_W'.format(self.name))
|
||||
self.b = K.zeros((self.nb_feature, self.output_dim),
|
||||
name='{}_b'.format(self.name))
|
||||
|
||||
self.trainable_weights = [self.W, self.b]
|
||||
self.regularizers = []
|
||||
@@ -1400,46 +1488,56 @@ class Lambda(Layer):
|
||||
Takes one argument: the output of previous layer
|
||||
output_shape: Expected output shape from function.
|
||||
Could be a tuple or a function of the shape of the input
|
||||
arguments: optional dictionary of keyword arguments to be passed
|
||||
to the function.
|
||||
'''
|
||||
def __init__(self, function, output_shape=None, **kwargs):
|
||||
def __init__(self, function, output_shape=None, arguments={}, **kwargs):
|
||||
super(Lambda, self).__init__(**kwargs)
|
||||
py3 = sys.version_info[0] == 3
|
||||
if py3:
|
||||
self.function = marshal.dumps(function.__code__)
|
||||
else:
|
||||
assert hasattr(function, 'func_code'), ('The Lambda layer "function"'
|
||||
' argument must be a Python function.')
|
||||
self.function = marshal.dumps(function.func_code)
|
||||
self.function = function
|
||||
self.arguments = arguments
|
||||
if output_shape is None:
|
||||
self._output_shape = None
|
||||
elif type(output_shape) in {tuple, list}:
|
||||
self._output_shape = tuple(output_shape)
|
||||
else:
|
||||
if py3:
|
||||
self._output_shape = marshal.dumps(output_shape.__code__)
|
||||
else:
|
||||
self._output_shape = marshal.dumps(output_shape.func_code)
|
||||
assert hasattr(output_shape, '__call__'), 'In Lambda, `output_shape` must be a list, a tuple, or a function.'
|
||||
self._output_shape = output_shape
|
||||
super(Lambda, self).__init__()
|
||||
|
||||
@property
|
||||
def output_shape(self):
|
||||
if self._output_shape is None:
|
||||
# if TensorFlow, we can infer the output shape directly:
|
||||
if K._BACKEND == 'tensorflow':
|
||||
# we assume output shape is not dependent on train/test mode
|
||||
x = self.get_output()
|
||||
return K.int_shape(x)
|
||||
# otherwise, we default to the input shape
|
||||
return self.input_shape
|
||||
elif type(self._output_shape) == tuple:
|
||||
return (self.input_shape[0], ) + self._output_shape
|
||||
elif type(self._output_shape) in {tuple, list}:
|
||||
nb_samples = self.input_shape[0] if self.input_shape else None
|
||||
return (nb_samples,) + tuple(self._output_shape)
|
||||
else:
|
||||
output_shape_func = marshal.loads(self._output_shape)
|
||||
output_shape_func = types.FunctionType(output_shape_func, globals())
|
||||
shape = output_shape_func(self.input_shape)
|
||||
shape = self._output_shape(self.input_shape)
|
||||
if type(shape) not in {list, tuple}:
|
||||
raise Exception('output_shape function must return a tuple')
|
||||
return tuple(shape)
|
||||
|
||||
def get_output(self, train=False):
|
||||
X = self.get_input(train)
|
||||
func = marshal.loads(self.function)
|
||||
func = types.FunctionType(func, globals())
|
||||
return func(X)
|
||||
arguments = self.arguments
|
||||
arg_spec = inspect.getargspec(self.function)
|
||||
if 'train' in arg_spec.args:
|
||||
arguments['train'] = train
|
||||
return self.function(X, **arguments)
|
||||
|
||||
def get_config(self):
|
||||
# note: not serializable at the moment.
|
||||
config = {'function': self.function,
|
||||
'output_shape': self._output_shape,
|
||||
'arguments': self.arguments}
|
||||
base_config = super(Lambda, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
|
||||
class MaskedLambda(MaskedLayer, Lambda):
|
||||
@@ -1459,8 +1557,10 @@ class LambdaMerge(Lambda):
|
||||
list of outputs from input layers
|
||||
output_shape - Expected output shape from function.
|
||||
Could be a tuple or a function of list of input shapes
|
||||
arguments: optional dictionary of keyword arguments to be passed
|
||||
to the function.
|
||||
'''
|
||||
def __init__(self, layers, function, output_shape=None):
|
||||
def __init__(self, layers, function, output_shape=None, arguments={}):
|
||||
if len(layers) < 2:
|
||||
raise Exception('Please specify two or more input layers '
|
||||
'(or containers) to merge.')
|
||||
@@ -1469,6 +1569,7 @@ class LambdaMerge(Lambda):
|
||||
self.regularizers = []
|
||||
self.constraints = []
|
||||
self.updates = []
|
||||
self.arguments = arguments
|
||||
for l in self.layers:
|
||||
params, regs, consts, updates = l.get_params()
|
||||
self.regularizers += regs
|
||||
@@ -1478,20 +1579,14 @@ class LambdaMerge(Lambda):
|
||||
if p not in self.trainable_weights:
|
||||
self.trainable_weights.append(p)
|
||||
self.constraints.append(c)
|
||||
py3 = sys.version_info[0] == 3
|
||||
if py3:
|
||||
self.function = marshal.dumps(function.__code__)
|
||||
else:
|
||||
self.function = marshal.dumps(function.func_code)
|
||||
self.function = function
|
||||
if output_shape is None:
|
||||
self._output_shape = None
|
||||
elif type(output_shape) in {tuple, list}:
|
||||
self._output_shape = tuple(output_shape)
|
||||
else:
|
||||
if py3:
|
||||
self._output_shape = marshal.dumps(output_shape.__code__)
|
||||
else:
|
||||
self._output_shape = marshal.dumps(output_shape.func_code)
|
||||
assert hasattr(output_shape, '__call__'), 'In LambdaMerge, `output_shape` must be a list, a tuple, or a function.'
|
||||
self._output_shape = output_shape
|
||||
super(Lambda, self).__init__()
|
||||
|
||||
@property
|
||||
@@ -1499,24 +1594,24 @@ class LambdaMerge(Lambda):
|
||||
input_shapes = [layer.output_shape for layer in self.layers]
|
||||
if self._output_shape is None:
|
||||
return input_shapes[0]
|
||||
elif type(self._output_shape) == tuple:
|
||||
return (input_shapes[0][0], ) + self._output_shape
|
||||
elif type(self._output_shape) in {tuple, list}:
|
||||
return (input_shapes[0][0],) + self._output_shape
|
||||
else:
|
||||
output_shape_func = marshal.loads(self._output_shape)
|
||||
output_shape_func = types.FunctionType(output_shape_func, globals())
|
||||
shape = output_shape_func(input_shapes)
|
||||
shape = self._output_shape(input_shapes)
|
||||
if type(shape) not in {list, tuple}:
|
||||
raise Exception('output_shape function must return a tuple.')
|
||||
raise Exception('In LambdaMerge, the `output_shape` function must return a tuple.')
|
||||
return tuple(shape)
|
||||
|
||||
def get_params(self):
|
||||
return self.trainable_weights, self.regularizers, self.constraints, self.updates
|
||||
|
||||
def get_output(self, train=False):
|
||||
func = marshal.loads(self.function)
|
||||
func = types.FunctionType(func, globals())
|
||||
inputs = [layer.get_output(train) for layer in self.layers]
|
||||
return func(inputs)
|
||||
arguments = self.arguments
|
||||
arg_spec = inspect.getargspec(self.function)
|
||||
if 'train' in arg_spec.args:
|
||||
arguments['train'] = train
|
||||
return self.function(inputs, **arguments)
|
||||
|
||||
def get_input(self, train=False):
|
||||
res = []
|
||||
@@ -1552,10 +1647,12 @@ class LambdaMerge(Lambda):
|
||||
weights = weights[nb_param:]
|
||||
|
||||
def get_config(self):
|
||||
# note: not serializable at the moment.
|
||||
config = {'name': self.__class__.__name__,
|
||||
'layers': [l.get_config() for l in self.layers],
|
||||
'function': self.function,
|
||||
'output_shape': self._output_shape}
|
||||
'output_shape': self._output_shape,
|
||||
'arguments': self.arguments}
|
||||
base_config = super(LambdaMerge, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
@@ -1614,6 +1711,10 @@ class Siamese(Layer):
|
||||
self.constraints.append(c)
|
||||
super(Siamese, self).__init__()
|
||||
|
||||
@property
|
||||
def input_shape(self):
|
||||
return [layer.output_shape for layer in self.inputs]
|
||||
|
||||
@property
|
||||
def output_shape(self):
|
||||
if self.merge_mode is None:
|
||||
@@ -1651,16 +1752,12 @@ class Siamese(Layer):
|
||||
return self.trainable_weights, self.regularizers, self.constraints, self.updates
|
||||
|
||||
def set_layer_input(self, head):
|
||||
layer = self.layer
|
||||
from ..layers.containers import Sequential
|
||||
while issubclass(layer.__class__, Sequential):
|
||||
layer = layer.layers[0]
|
||||
layer.previous = self.inputs[head]
|
||||
self.layer.set_previous(self.inputs[head], reset_weights=False)
|
||||
|
||||
def get_output_at(self, head, train=False):
|
||||
X = self.inputs[head].get_output(train)
|
||||
mask = self.inputs[head].get_output_mask(train)
|
||||
Y = self.layer(X, mask)
|
||||
Y = self.layer(X, mask=mask, train=train)
|
||||
return Y
|
||||
|
||||
def get_output_shape(self, head, train=False):
|
||||
@@ -1703,24 +1800,17 @@ class Siamese(Layer):
|
||||
return s
|
||||
|
||||
def get_output_dot(self, train=False):
|
||||
if K._BACKEND != 'theano':
|
||||
raise Exception('"dot" merge mode will only work with Theano.')
|
||||
from theano import tensor as T
|
||||
l1 = self.get_output_at(0, train)
|
||||
l2 = self.get_output_at(1, train)
|
||||
output = T.batched_tensordot(l1, l2, self.dot_axes)
|
||||
output = output.dimshuffle((0, 'x'))
|
||||
output = K.batch_dot(l1, l2, self.dot_axes)
|
||||
output = K.expand_dims(output, -1)
|
||||
return output
|
||||
|
||||
def get_output_cos(self, train=False):
|
||||
if K._BACKEND != 'theano':
|
||||
raise Exception('"cos" merge mode will only work with Theano.')
|
||||
import theano
|
||||
from theano import tensor as T
|
||||
l1 = self.get_output_at(0, train)
|
||||
l2 = self.get_output_at(1, train)
|
||||
output = T.batched_tensordot(l1, l2, self.dot_axes) / T.sqrt(T.batched_tensordot(l1, l1, self.dot_axes) * T.batched_tensordot(l2, l2, self.dot_axes))
|
||||
output = output.dimshuffle((0, 'x'))
|
||||
output = K.batch_dot(l1, l2, self.dot_axes) / K.sqrt(K.batch_dot(l1, l1, self.dot_axes) * K.batch_dot(l2, l2, self.dot_axes))
|
||||
output = K.expand_dims(output, -1)
|
||||
return output
|
||||
|
||||
def get_output(self, train=False):
|
||||
@@ -1769,12 +1859,12 @@ class Siamese(Layer):
|
||||
return weights
|
||||
|
||||
def set_weights(self, weights):
|
||||
nb_param = len(self.layer.trainable_weights)
|
||||
nb_param = len(self.layer.get_weights())
|
||||
self.layer.set_weights(weights[:nb_param])
|
||||
weights = weights[nb_param:]
|
||||
if self.merge_mode and not self.is_graph:
|
||||
for i in range(len(self.inputs)):
|
||||
nb_param = len(self.inputs[i].trainable_weights)
|
||||
nb_param = len(self.inputs[i].get_weights())
|
||||
self.inputs[i].set_weights(weights[:nb_param])
|
||||
weights = weights[nb_param:]
|
||||
|
||||
@@ -1824,9 +1914,6 @@ class SiameseHead(Layer):
|
||||
base_config = super(SiameseHead, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
def set_previous(self, layer):
|
||||
self.previous = layer
|
||||
|
||||
|
||||
def add_shared_layer(layer, inputs):
|
||||
'''Use this function to add a shared layer across
|
||||
@@ -1863,7 +1950,8 @@ class Highway(Layer):
|
||||
If you don't specify anything, no activation is applied
|
||||
(ie. "linear" activation: a(x) = x).
|
||||
weights: list of numpy arrays to set as initial weights.
|
||||
The list should have 1 element, of shape `(input_dim, output_dim)`.
|
||||
The list should have 2 elements, of shape `(input_dim, output_dim)`
|
||||
and (output_dim,) for weights and biases respectively.
|
||||
W_regularizer: instance of [WeightRegularizer](../regularizers.md)
|
||||
(eg. L1 or L2 regularization), applied to the main weights matrix.
|
||||
b_regularizer: instance of [WeightRegularizer](../regularizers.md),
|
||||
@@ -1904,18 +1992,20 @@ class Highway(Layer):
|
||||
self.input_dim = input_dim
|
||||
if self.input_dim:
|
||||
kwargs['input_shape'] = (self.input_dim,)
|
||||
self.input = K.placeholder(ndim=2)
|
||||
super(Highway, self).__init__(**kwargs)
|
||||
|
||||
def build(self):
|
||||
input_dim = self.input_shape[1]
|
||||
|
||||
self.W = self.init((input_dim, input_dim))
|
||||
self.W_carry = self.init((input_dim, input_dim))
|
||||
self.W = self.init((input_dim, input_dim),
|
||||
name='{}_W'.format(self.name))
|
||||
self.W_carry = self.init((input_dim, input_dim),
|
||||
name='{}_W_carry'.format(self.name))
|
||||
|
||||
self.b = K.zeros((input_dim,))
|
||||
self.b = K.zeros((input_dim,), name='{}_b'.format(self.name))
|
||||
# initialize with a vector of values `transform_bias`
|
||||
self.b_carry = K.variable(np.ones((input_dim,)) * self.transform_bias)
|
||||
self.b_carry = K.variable(np.ones((input_dim,)) * self.transform_bias,
|
||||
name='{}_b_carry'.format(self.name))
|
||||
|
||||
self.trainable_weights = [self.W, self.b, self.W_carry, self.b_carry]
|
||||
|
||||
|
||||
@@ -1,10 +1,8 @@
|
||||
from __future__ import absolute_import
|
||||
|
||||
from .. import backend as K
|
||||
|
||||
from .. import activations, initializations, regularizers, constraints
|
||||
from ..layers.core import Layer, MaskedLayer
|
||||
|
||||
from ..constraints import unitnorm
|
||||
from .. import initializations, regularizers, constraints
|
||||
from ..layers.core import Layer
|
||||
|
||||
|
||||
class Embedding(Layer):
|
||||
@@ -42,6 +40,10 @@ class Embedding(Layer):
|
||||
This argument is required if you are going to connect
|
||||
`Flatten` then `Dense` layers upstream
|
||||
(without it, the shape of the dense outputs cannot be computed).
|
||||
dropout: float between 0 and 1. Fraction of the embeddings to drop.
|
||||
|
||||
# References
|
||||
- [A Theoretically Grounded Application of Dropout in Recurrent Neural Networks](http://arxiv.org/abs/1512.05287)
|
||||
'''
|
||||
input_ndim = 2
|
||||
|
||||
@@ -50,12 +52,13 @@ class Embedding(Layer):
|
||||
W_regularizer=None, activity_regularizer=None,
|
||||
W_constraint=None,
|
||||
mask_zero=False,
|
||||
weights=None, **kwargs):
|
||||
weights=None, dropout=0., **kwargs):
|
||||
self.input_dim = input_dim
|
||||
self.output_dim = output_dim
|
||||
self.init = initializations.get(init)
|
||||
self.input_length = input_length
|
||||
self.mask_zero = mask_zero
|
||||
self.dropout = dropout
|
||||
|
||||
self.W_constraint = constraints.get(W_constraint)
|
||||
self.constraints = [self.W_constraint]
|
||||
@@ -70,7 +73,8 @@ class Embedding(Layer):
|
||||
def build(self):
|
||||
self.input = K.placeholder(shape=(self.input_shape[0], self.input_length),
|
||||
dtype='int32')
|
||||
self.W = self.init((self.input_dim, self.output_dim))
|
||||
self.W = self.init((self.input_dim, self.output_dim),
|
||||
name='{}_W'.format(self.name))
|
||||
self.trainable_weights = [self.W]
|
||||
self.regularizers = []
|
||||
if self.W_regularizer:
|
||||
@@ -97,7 +101,13 @@ class Embedding(Layer):
|
||||
|
||||
def get_output(self, train=False):
|
||||
X = self.get_input(train)
|
||||
out = K.gather(self.W, X)
|
||||
retain_p = 1. - self.dropout
|
||||
if train and self.dropout > 0:
|
||||
B = K.random_binomial((self.input_dim,), p=retain_p)
|
||||
else:
|
||||
B = K.ones((self.input_dim)) * retain_p
|
||||
# we zero-out rows of W at random
|
||||
out = K.gather(self.W * K.expand_dims(B), X)
|
||||
return out
|
||||
|
||||
def get_config(self):
|
||||
@@ -109,6 +119,7 @@ class Embedding(Layer):
|
||||
"mask_zero": self.mask_zero,
|
||||
"activity_regularizer": self.activity_regularizer.get_config() if self.activity_regularizer else None,
|
||||
"W_regularizer": self.W_regularizer.get_config() if self.W_regularizer else None,
|
||||
"W_constraint": self.W_constraint.get_config() if self.W_constraint else None}
|
||||
"W_constraint": self.W_constraint.get_config() if self.W_constraint else None,
|
||||
"dropout": self.dropout}
|
||||
base_config = super(Embedding, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
@@ -37,13 +37,21 @@ class BatchNormalization(Layer):
|
||||
weights: Initialization weights.
|
||||
List of 2 numpy arrays, with shapes:
|
||||
`[(input_shape,), (input_shape,)]`
|
||||
|
||||
beta_init: name of initialization function for shift parameter
|
||||
(see [initializations](../initializations.md)), or alternatively,
|
||||
Theano/TensorFlow function to use for weights initialization.
|
||||
This parameter is only relevant if you don't pass a `weights` argument.
|
||||
gamma_init: name of initialization function for scale parameter (see
|
||||
[initializations](../initializations.md)), or alternatively,
|
||||
Theano/TensorFlow function to use for weights initialization.
|
||||
This parameter is only relevant if you don't pass a `weights` argument.
|
||||
# References
|
||||
- [Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift](http://arxiv.org/pdf/1502.03167v3.pdf)
|
||||
'''
|
||||
def __init__(self, epsilon=1e-6, mode=0, axis=-1, momentum=0.9,
|
||||
weights=None, **kwargs):
|
||||
self.init = initializations.get("uniform")
|
||||
weights=None, beta_init='zero', gamma_init='one', **kwargs):
|
||||
self.beta_init = initializations.get(beta_init)
|
||||
self.gamma_init = initializations.get(gamma_init)
|
||||
self.epsilon = epsilon
|
||||
self.mode = mode
|
||||
self.axis = axis
|
||||
@@ -55,12 +63,14 @@ class BatchNormalization(Layer):
|
||||
input_shape = self.input_shape # starts with samples axis
|
||||
shape = (input_shape[self.axis],)
|
||||
|
||||
self.gamma = self.init(shape)
|
||||
self.beta = K.zeros(shape)
|
||||
self.gamma = self.gamma_init(shape, name='{}_gamma'.format(self.name))
|
||||
self.beta = self.beta_init(shape, name='{}_beta'.format(self.name))
|
||||
self.trainable_weights = [self.gamma, self.beta]
|
||||
|
||||
self.running_mean = K.zeros(shape)
|
||||
self.running_std = K.ones(shape)
|
||||
self.running_mean = K.zeros(shape,
|
||||
name='{}_running_mean'.format(self.name))
|
||||
self.running_std = K.ones(shape,
|
||||
name='{}_running_std'.format(self.name))
|
||||
self.non_trainable_weights = [self.running_mean, self.running_std]
|
||||
|
||||
if self.initial_weights is not None:
|
||||
|
||||
+316
-69
@@ -3,10 +3,42 @@ from __future__ import absolute_import
|
||||
import numpy as np
|
||||
|
||||
from .. import backend as K
|
||||
from .. import activations, initializations
|
||||
from .. import activations, initializations, regularizers
|
||||
from ..layers.core import MaskedLayer
|
||||
|
||||
|
||||
def time_distributed_dense(x, w, b=None, dropout=None,
|
||||
input_dim=None, output_dim=None, timesteps=None):
|
||||
'''Apply y.w + b for every temporal slice y of x.
|
||||
'''
|
||||
if not input_dim:
|
||||
# won't work with TensorFlow
|
||||
input_dim = K.shape(x)[2]
|
||||
if not timesteps:
|
||||
# won't work with TensorFlow
|
||||
timesteps = K.shape(x)[1]
|
||||
if not output_dim:
|
||||
# won't work with TensorFlow
|
||||
output_dim = K.shape(w)[1]
|
||||
|
||||
if dropout:
|
||||
# apply the same dropout pattern at every timestep
|
||||
ones = K.ones_like(K.reshape(x[:, 0, :], (-1, input_dim)))
|
||||
dropout_matrix = K.dropout(ones, dropout)
|
||||
expanded_dropout_matrix = K.repeat(dropout_matrix, timesteps)
|
||||
x *= expanded_dropout_matrix
|
||||
|
||||
# collapse time dimension and batch dimension together
|
||||
x = K.reshape(x, (-1, input_dim))
|
||||
|
||||
x = K.dot(x, w)
|
||||
if b:
|
||||
x = x + b
|
||||
# reshape to 3D tensor
|
||||
x = K.reshape(x, (-1, timesteps, output_dim))
|
||||
return x
|
||||
|
||||
|
||||
class Recurrent(MaskedLayer):
|
||||
'''Abstract base class for recurrent layers.
|
||||
Do not use in a model -- it's not a functional layer!
|
||||
@@ -78,6 +110,10 @@ class Recurrent(MaskedLayer):
|
||||
|
||||
To reset the states of your model, call `.reset_states()` on either
|
||||
a specific layer, or on your entire model.
|
||||
|
||||
# Note on using dropout with TensorFlow
|
||||
When using the TensorFlow backend, specify a fixed batch size for your model
|
||||
following the notes on statefulness RNNs.
|
||||
'''
|
||||
input_ndim = 3
|
||||
|
||||
@@ -112,15 +148,21 @@ class Recurrent(MaskedLayer):
|
||||
def step(self, x, states):
|
||||
raise NotImplementedError
|
||||
|
||||
def get_initial_states(self, X):
|
||||
def get_constants(self, x, train=False):
|
||||
return []
|
||||
|
||||
def get_initial_states(self, x):
|
||||
# build an all-zero tensor of shape (samples, output_dim)
|
||||
initial_state = K.zeros_like(X) # (samples, timesteps, input_dim)
|
||||
initial_state = K.zeros_like(x) # (samples, timesteps, input_dim)
|
||||
initial_state = K.sum(initial_state, axis=1) # (samples, input_dim)
|
||||
reducer = K.zeros((self.input_dim, self.output_dim))
|
||||
initial_state = K.dot(initial_state, reducer) # (samples, output_dim)
|
||||
initial_states = [initial_state for _ in range(len(self.states))]
|
||||
return initial_states
|
||||
|
||||
def preprocess_input(self, x, train=False):
|
||||
return x
|
||||
|
||||
def get_output(self, train=False):
|
||||
# input shape: (nb_samples, time (padded with zeros), input_dim)
|
||||
X = self.get_input(train)
|
||||
@@ -142,11 +184,14 @@ class Recurrent(MaskedLayer):
|
||||
initial_states = self.states
|
||||
else:
|
||||
initial_states = self.get_initial_states(X)
|
||||
constants = self.get_constants(X, train)
|
||||
preprocessed_input = self.preprocess_input(X, train)
|
||||
|
||||
last_output, outputs, states = K.rnn(self.step, X,
|
||||
last_output, outputs, states = K.rnn(self.step, preprocessed_input,
|
||||
initial_states,
|
||||
go_backwards=self.go_backwards,
|
||||
mask=mask)
|
||||
mask=mask,
|
||||
constants=constants)
|
||||
if self.stateful:
|
||||
self.updates = []
|
||||
for i in range(len(states)):
|
||||
@@ -167,13 +212,13 @@ class Recurrent(MaskedLayer):
|
||||
else:
|
||||
config['input_dim'] = self.input_dim
|
||||
config['input_length'] = self.input_length
|
||||
|
||||
|
||||
base_config = super(Recurrent, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
|
||||
class SimpleRNN(Recurrent):
|
||||
'''Fully-connected RNN where the output is to fed back to input.
|
||||
'''Fully-connected RNN where the output is to be fed back to input.
|
||||
|
||||
# Arguments
|
||||
output_dim: dimension of the internal projections and the final output.
|
||||
@@ -184,14 +229,31 @@ class SimpleRNN(Recurrent):
|
||||
activation: activation function.
|
||||
Can be the name of an existing function (str),
|
||||
or a Theano function (see: [activations](../activations.md)).
|
||||
W_regularizer: instance of [WeightRegularizer](../regularizers.md)
|
||||
(eg. L1 or L2 regularization), applied to the input weights matrices.
|
||||
U_regularizer: instance of [WeightRegularizer](../regularizers.md)
|
||||
(eg. L1 or L2 regularization), applied to the recurrent weights matrices.
|
||||
b_regularizer: instance of [WeightRegularizer](../regularizers.md),
|
||||
applied to the bias.
|
||||
dropout_W: float between 0 and 1. Fraction of the input units to drop for input gates.
|
||||
dropout_U: float between 0 and 1. Fraction of the input units to drop for recurrent connections.
|
||||
|
||||
# References
|
||||
- [A Theoretically Grounded Application of Dropout in Recurrent Neural Networks](http://arxiv.org/abs/1512.05287)
|
||||
'''
|
||||
def __init__(self, output_dim,
|
||||
init='glorot_uniform', inner_init='orthogonal',
|
||||
activation='sigmoid', **kwargs):
|
||||
activation='tanh',
|
||||
W_regularizer=None, U_regularizer=None, b_regularizer=None,
|
||||
dropout_W=0., dropout_U=0., **kwargs):
|
||||
self.output_dim = output_dim
|
||||
self.init = initializations.get(init)
|
||||
self.inner_init = initializations.get(inner_init)
|
||||
self.activation = activations.get(activation)
|
||||
self.W_regularizer = regularizers.get(W_regularizer)
|
||||
self.U_regularizer = regularizers.get(U_regularizer)
|
||||
self.b_regularizer = regularizers.get(b_regularizer)
|
||||
self.dropout_W, self.dropout_U = dropout_W, dropout_U
|
||||
super(SimpleRNN, self).__init__(**kwargs)
|
||||
|
||||
def build(self):
|
||||
@@ -204,9 +266,23 @@ class SimpleRNN(Recurrent):
|
||||
input_dim = input_shape[2]
|
||||
self.input_dim = input_dim
|
||||
|
||||
self.W = self.init((input_dim, self.output_dim))
|
||||
self.U = self.inner_init((self.output_dim, self.output_dim))
|
||||
self.b = K.zeros((self.output_dim,))
|
||||
self.W = self.init((input_dim, self.output_dim),
|
||||
name='{}_W'.format(self.name))
|
||||
self.U = self.inner_init((self.output_dim, self.output_dim),
|
||||
name='{}_U'.format(self.name))
|
||||
self.b = K.zeros((self.output_dim,), name='{}_b'.format(self.name))
|
||||
|
||||
self.regularizers = []
|
||||
if self.W_regularizer:
|
||||
self.W_regularizer.set_param(self.W)
|
||||
self.regularizers.append(self.W_regularizer)
|
||||
if self.U_regularizer:
|
||||
self.W_regularizer.set_param(self.U)
|
||||
self.regularizers.append(self.U_regularizer)
|
||||
if self.b_regularizer:
|
||||
self.W_regularizer.set_param(self.b)
|
||||
self.regularizers.append(self.b_regularizer)
|
||||
|
||||
self.trainable_weights = [self.W, self.U, self.b]
|
||||
|
||||
if self.initial_weights is not None:
|
||||
@@ -218,27 +294,51 @@ class SimpleRNN(Recurrent):
|
||||
input_shape = self.input_shape
|
||||
if not input_shape[0]:
|
||||
raise Exception('If a RNN is stateful, a complete ' +
|
||||
'input_shape must be provided ' +
|
||||
'(including batch size).')
|
||||
'input_shape must be provided (including batch size).')
|
||||
if hasattr(self, 'states'):
|
||||
K.set_value(self.states[0],
|
||||
np.zeros((input_shape[0], self.output_dim)))
|
||||
else:
|
||||
self.states = [K.zeros((input_shape[0], self.output_dim))]
|
||||
|
||||
def step(self, x, states):
|
||||
# states only contains the previous output.
|
||||
assert len(states) == 1
|
||||
def preprocess_input(self, x, train=False):
|
||||
if train and (0 < self.dropout_W < 1):
|
||||
dropout = self.dropout_W
|
||||
else:
|
||||
dropout = 0
|
||||
input_shape = self.input_shape
|
||||
input_dim = input_shape[2]
|
||||
timesteps = input_shape[1]
|
||||
return time_distributed_dense(x, self.W, self.b, dropout,
|
||||
input_dim, self.output_dim, timesteps)
|
||||
|
||||
def step(self, h, states):
|
||||
prev_output = states[0]
|
||||
h = K.dot(x, self.W) + self.b
|
||||
output = self.activation(h + K.dot(prev_output, self.U))
|
||||
if len(states) == 2:
|
||||
B_U = states[1]
|
||||
else:
|
||||
B_U = 1.
|
||||
output = self.activation(h + K.dot(prev_output * B_U, self.U))
|
||||
return output, [output]
|
||||
|
||||
def get_constants(self, x, train=False):
|
||||
if train and (0 < self.dropout_U < 1):
|
||||
ones = K.ones_like(K.reshape(x[:, 0, 0], (-1, 1)))
|
||||
ones = K.concatenate([ones] * self.output_dim, 1)
|
||||
B_U = K.dropout(ones, self.dropout_U)
|
||||
return [B_U]
|
||||
return []
|
||||
|
||||
def get_config(self):
|
||||
config = {"output_dim": self.output_dim,
|
||||
"init": self.init.__name__,
|
||||
"inner_init": self.inner_init.__name__,
|
||||
"activation": self.activation.__name__}
|
||||
"activation": self.activation.__name__,
|
||||
"W_regularizer": self.W_regularizer.get_config() if self.W_regularizer else None,
|
||||
"U_regularizer": self.U_regularizer.get_config() if self.U_regularizer else None,
|
||||
"b_regularizer": self.b_regularizer.get_config() if self.b_regularizer else None,
|
||||
"dropout_W": self.dropout_W,
|
||||
"dropout_U": self.dropout_U}
|
||||
base_config = super(SimpleRNN, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
@@ -256,39 +356,75 @@ class GRU(Recurrent):
|
||||
Can be the name of an existing function (str),
|
||||
or a Theano function (see: [activations](../activations.md)).
|
||||
inner_activation: activation function for the inner cells.
|
||||
W_regularizer: instance of [WeightRegularizer](../regularizers.md)
|
||||
(eg. L1 or L2 regularization), applied to the input weights matrices.
|
||||
U_regularizer: instance of [WeightRegularizer](../regularizers.md)
|
||||
(eg. L1 or L2 regularization), applied to the recurrent weights matrices.
|
||||
b_regularizer: instance of [WeightRegularizer](../regularizers.md),
|
||||
applied to the bias.
|
||||
dropout_W: float between 0 and 1. Fraction of the input units to drop for input gates.
|
||||
dropout_U: float between 0 and 1. Fraction of the input units to drop for recurrent connections.
|
||||
|
||||
# References
|
||||
- [On the Properties of Neural Machine Translation: Encoder–Decoder Approaches](http://www.aclweb.org/anthology/W14-4012)
|
||||
- [Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling](http://arxiv.org/pdf/1412.3555v1.pdf)
|
||||
- [A Theoretically Grounded Application of Dropout in Recurrent Neural Networks](http://arxiv.org/abs/1512.05287)
|
||||
'''
|
||||
def __init__(self, output_dim,
|
||||
init='glorot_uniform', inner_init='orthogonal',
|
||||
activation='sigmoid', inner_activation='hard_sigmoid',
|
||||
**kwargs):
|
||||
activation='tanh', inner_activation='hard_sigmoid',
|
||||
W_regularizer=None, U_regularizer=None, b_regularizer=None,
|
||||
dropout_W=0., dropout_U=0., **kwargs):
|
||||
self.output_dim = output_dim
|
||||
self.init = initializations.get(init)
|
||||
self.inner_init = initializations.get(inner_init)
|
||||
self.activation = activations.get(activation)
|
||||
self.inner_activation = activations.get(inner_activation)
|
||||
self.W_regularizer = regularizers.get(W_regularizer)
|
||||
self.U_regularizer = regularizers.get(U_regularizer)
|
||||
self.b_regularizer = regularizers.get(b_regularizer)
|
||||
self.dropout_W, self.dropout_U = dropout_W, dropout_U
|
||||
super(GRU, self).__init__(**kwargs)
|
||||
|
||||
def build(self):
|
||||
input_shape = self.input_shape
|
||||
input_dim = input_shape[2]
|
||||
self.input_dim = input_dim
|
||||
self.input = K.placeholder(input_shape)
|
||||
|
||||
self.W_z = self.init((input_dim, self.output_dim))
|
||||
self.U_z = self.inner_init((self.output_dim, self.output_dim))
|
||||
self.b_z = K.zeros((self.output_dim,))
|
||||
self.W_z = self.init((input_dim, self.output_dim),
|
||||
name='{}_W_z'.format(self.name))
|
||||
self.U_z = self.inner_init((self.output_dim, self.output_dim),
|
||||
name='{}_U_z'.format(self.name))
|
||||
self.b_z = K.zeros((self.output_dim,), name='{}_b_z'.format(self.name))
|
||||
|
||||
self.W_r = self.init((input_dim, self.output_dim))
|
||||
self.U_r = self.inner_init((self.output_dim, self.output_dim))
|
||||
self.b_r = K.zeros((self.output_dim,))
|
||||
self.W_r = self.init((input_dim, self.output_dim),
|
||||
name='{}_W_r'.format(self.name))
|
||||
self.U_r = self.inner_init((self.output_dim, self.output_dim),
|
||||
name='{}_U_r'.format(self.name))
|
||||
self.b_r = K.zeros((self.output_dim,), name='{}_b_r'.format(self.name))
|
||||
|
||||
self.W_h = self.init((input_dim, self.output_dim))
|
||||
self.U_h = self.inner_init((self.output_dim, self.output_dim))
|
||||
self.b_h = K.zeros((self.output_dim,))
|
||||
self.W_h = self.init((input_dim, self.output_dim),
|
||||
name='{}_W_h'.format(self.name))
|
||||
self.U_h = self.inner_init((self.output_dim, self.output_dim),
|
||||
name='{}_U_h'.format(self.name))
|
||||
self.b_h = K.zeros((self.output_dim,), name='{}_b_h'.format(self.name))
|
||||
|
||||
self.regularizers = []
|
||||
if self.W_regularizer:
|
||||
self.W_regularizer.set_param(K.concatenate([self.W_z,
|
||||
self.W_r,
|
||||
self.W_h]))
|
||||
self.regularizers.append(self.W_regularizer)
|
||||
if self.U_regularizer:
|
||||
self.U_regularizer.set_param(K.concatenate([self.U_z,
|
||||
self.U_r,
|
||||
self.U_h]))
|
||||
self.regularizers.append(self.U_regularizer)
|
||||
if self.b_regularizer:
|
||||
self.b_regularizer.set_param(K.concatenate([self.b_z,
|
||||
self.b_r,
|
||||
self.b_h]))
|
||||
self.regularizers.append(self.b_regularizer)
|
||||
|
||||
self.trainable_weights = [self.W_z, self.U_z, self.b_z,
|
||||
self.W_r, self.U_r, self.b_r,
|
||||
@@ -308,34 +444,67 @@ class GRU(Recurrent):
|
||||
input_shape = self.input_shape
|
||||
if not input_shape[0]:
|
||||
raise Exception('If a RNN is stateful, a complete ' +
|
||||
'input_shape must be provided ' +
|
||||
'(including batch size).')
|
||||
'input_shape must be provided (including batch size).')
|
||||
if hasattr(self, 'states'):
|
||||
K.set_value(self.states[0],
|
||||
np.zeros((input_shape[0], self.output_dim)))
|
||||
else:
|
||||
self.states = [K.zeros((input_shape[0], self.output_dim))]
|
||||
|
||||
def preprocess_input(self, x, train=False):
|
||||
if train and (0 < self.dropout_W < 1):
|
||||
dropout = self.dropout_W
|
||||
else:
|
||||
dropout = 0
|
||||
input_shape = self.input_shape
|
||||
input_dim = input_shape[2]
|
||||
timesteps = input_shape[1]
|
||||
|
||||
x_z = time_distributed_dense(x, self.W_z, self.b_z, dropout,
|
||||
input_dim, self.output_dim, timesteps)
|
||||
x_r = time_distributed_dense(x, self.W_r, self.b_r, dropout,
|
||||
input_dim, self.output_dim, timesteps)
|
||||
x_h = time_distributed_dense(x, self.W_h, self.b_h, dropout,
|
||||
input_dim, self.output_dim, timesteps)
|
||||
return K.concatenate([x_z, x_r, x_h], axis=2)
|
||||
|
||||
def step(self, x, states):
|
||||
assert len(states) == 1
|
||||
x_z = K.dot(x, self.W_z) + self.b_z
|
||||
x_r = K.dot(x, self.W_r) + self.b_r
|
||||
x_h = K.dot(x, self.W_h) + self.b_h
|
||||
h_tm1 = states[0] # previous memory
|
||||
if len(states) == 2:
|
||||
B_U = states[1] # dropout matrices for recurrent units
|
||||
else:
|
||||
B_U = [1., 1., 1.]
|
||||
|
||||
h_tm1 = states[0]
|
||||
z = self.inner_activation(x_z + K.dot(h_tm1, self.U_z))
|
||||
r = self.inner_activation(x_r + K.dot(h_tm1, self.U_r))
|
||||
x_z = x[:, :self.output_dim]
|
||||
x_r = x[:, self.output_dim: 2 * self.output_dim]
|
||||
x_h = x[:, 2 * self.output_dim:]
|
||||
|
||||
hh = self.activation(x_h + K.dot(r * h_tm1, self.U_h))
|
||||
z = self.inner_activation(x_z + K.dot(h_tm1 * B_U[0], self.U_z))
|
||||
r = self.inner_activation(x_r + K.dot(h_tm1 * B_U[1], self.U_r))
|
||||
|
||||
hh = self.activation(x_h + K.dot(r * h_tm1 * B_U[2], self.U_h))
|
||||
h = z * h_tm1 + (1 - z) * hh
|
||||
return h, [h]
|
||||
|
||||
def get_constants(self, x, train=False):
|
||||
if train and (0 < self.dropout_U < 1):
|
||||
ones = K.ones_like(K.reshape(x[:, 0, 0], (-1, 1)))
|
||||
ones = K.concatenate([ones] * self.output_dim, 1)
|
||||
B_U = [K.dropout(ones, self.dropout_U) for _ in range(3)]
|
||||
return [B_U]
|
||||
return []
|
||||
|
||||
def get_config(self):
|
||||
config = {"output_dim": self.output_dim,
|
||||
"init": self.init.__name__,
|
||||
"inner_init": self.inner_init.__name__,
|
||||
"activation": self.activation.__name__,
|
||||
"inner_activation": self.inner_activation.__name__}
|
||||
"inner_activation": self.inner_activation.__name__,
|
||||
"W_regularizer": self.W_regularizer.get_config() if self.W_regularizer else None,
|
||||
"U_regularizer": self.U_regularizer.get_config() if self.U_regularizer else None,
|
||||
"b_regularizer": self.b_regularizer.get_config() if self.b_regularizer else None,
|
||||
"dropout_W": self.dropout_W,
|
||||
"dropout_U": self.dropout_U}
|
||||
base_config = super(GRU, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
@@ -359,51 +528,94 @@ class LSTM(Recurrent):
|
||||
Can be the name of an existing function (str),
|
||||
or a Theano function (see: [activations](../activations.md)).
|
||||
inner_activation: activation function for the inner cells.
|
||||
W_regularizer: instance of [WeightRegularizer](../regularizers.md)
|
||||
(eg. L1 or L2 regularization), applied to the input weights matrices.
|
||||
U_regularizer: instance of [WeightRegularizer](../regularizers.md)
|
||||
(eg. L1 or L2 regularization), applied to the recurrent weights matrices.
|
||||
b_regularizer: instance of [WeightRegularizer](../regularizers.md),
|
||||
applied to the bias.
|
||||
dropout_W: float between 0 and 1. Fraction of the input units to drop for input gates.
|
||||
dropout_U: float between 0 and 1. Fraction of the input units to drop for recurrent connections.
|
||||
|
||||
# References
|
||||
- [Long short-term memory](http://deeplearning.cs.cmu.edu/pdfs/Hochreiter97_lstm.pdf) (original 1997 paper)
|
||||
- [Learning to forget: Continual prediction with LSTM](http://www.mitpressjournals.org/doi/pdf/10.1162/089976600300015015)
|
||||
- [Supervised sequence labelling with recurrent neural networks](http://www.cs.toronto.edu/~graves/preprint.pdf)
|
||||
- [A Theoretically Grounded Application of Dropout in Recurrent Neural Networks](http://arxiv.org/abs/1512.05287)
|
||||
'''
|
||||
def __init__(self, output_dim,
|
||||
init='glorot_uniform', inner_init='orthogonal',
|
||||
forget_bias_init='one', activation='tanh',
|
||||
inner_activation='hard_sigmoid', **kwargs):
|
||||
inner_activation='hard_sigmoid',
|
||||
W_regularizer=None, U_regularizer=None, b_regularizer=None,
|
||||
dropout_W=0., dropout_U=0., **kwargs):
|
||||
self.output_dim = output_dim
|
||||
self.init = initializations.get(init)
|
||||
self.inner_init = initializations.get(inner_init)
|
||||
self.forget_bias_init = initializations.get(forget_bias_init)
|
||||
self.activation = activations.get(activation)
|
||||
self.inner_activation = activations.get(inner_activation)
|
||||
self.W_regularizer = regularizers.get(W_regularizer)
|
||||
self.U_regularizer = regularizers.get(U_regularizer)
|
||||
self.b_regularizer = regularizers.get(b_regularizer)
|
||||
self.dropout_W, self.dropout_U = dropout_W, dropout_U
|
||||
super(LSTM, self).__init__(**kwargs)
|
||||
|
||||
def build(self):
|
||||
input_shape = self.input_shape
|
||||
input_dim = input_shape[2]
|
||||
self.input_dim = input_dim
|
||||
self.input = K.placeholder(input_shape)
|
||||
|
||||
if self.stateful:
|
||||
self.reset_states()
|
||||
else:
|
||||
# initial states: 2 all-zero tensor of shape (output_dim)
|
||||
# initial states: 2 all-zero tensors of shape (output_dim)
|
||||
self.states = [None, None]
|
||||
|
||||
self.W_i = self.init((input_dim, self.output_dim))
|
||||
self.U_i = self.inner_init((self.output_dim, self.output_dim))
|
||||
self.b_i = K.zeros((self.output_dim,))
|
||||
self.W_i = self.init((input_dim, self.output_dim),
|
||||
name='{}_W_i'.format(self.name))
|
||||
self.U_i = self.inner_init((self.output_dim, self.output_dim),
|
||||
name='{}_U_i'.format(self.name))
|
||||
self.b_i = K.zeros((self.output_dim,), name='{}_b_i'.format(self.name))
|
||||
|
||||
self.W_f = self.init((input_dim, self.output_dim))
|
||||
self.U_f = self.inner_init((self.output_dim, self.output_dim))
|
||||
self.b_f = self.forget_bias_init((self.output_dim,))
|
||||
self.W_f = self.init((input_dim, self.output_dim),
|
||||
name='{}_W_f'.format(self.name))
|
||||
self.U_f = self.inner_init((self.output_dim, self.output_dim),
|
||||
name='{}_U_f'.format(self.name))
|
||||
self.b_f = self.forget_bias_init((self.output_dim,),
|
||||
name='{}_b_f'.format(self.name))
|
||||
|
||||
self.W_c = self.init((input_dim, self.output_dim))
|
||||
self.U_c = self.inner_init((self.output_dim, self.output_dim))
|
||||
self.b_c = K.zeros((self.output_dim,))
|
||||
self.W_c = self.init((input_dim, self.output_dim),
|
||||
name='{}_W_c'.format(self.name))
|
||||
self.U_c = self.inner_init((self.output_dim, self.output_dim),
|
||||
name='{}_U_c'.format(self.name))
|
||||
self.b_c = K.zeros((self.output_dim,), name='{}_b_c'.format(self.name))
|
||||
|
||||
self.W_o = self.init((input_dim, self.output_dim))
|
||||
self.U_o = self.inner_init((self.output_dim, self.output_dim))
|
||||
self.b_o = K.zeros((self.output_dim,))
|
||||
self.W_o = self.init((input_dim, self.output_dim),
|
||||
name='{}_W_o'.format(self.name))
|
||||
self.U_o = self.inner_init((self.output_dim, self.output_dim),
|
||||
name='{}_U_o'.format(self.name))
|
||||
self.b_o = K.zeros((self.output_dim,), name='{}_b_o'.format(self.name))
|
||||
|
||||
self.regularizers = []
|
||||
if self.W_regularizer:
|
||||
self.W_regularizer.set_param(K.concatenate([self.W_i,
|
||||
self.W_f,
|
||||
self.W_c,
|
||||
self.W_o]))
|
||||
self.regularizers.append(self.W_regularizer)
|
||||
if self.U_regularizer:
|
||||
self.U_regularizer.set_param(K.concatenate([self.U_i,
|
||||
self.U_f,
|
||||
self.U_c,
|
||||
self.U_o]))
|
||||
self.regularizers.append(self.U_regularizer)
|
||||
if self.b_regularizer:
|
||||
self.b_regularizer.set_param(K.concatenate([self.b_i,
|
||||
self.b_f,
|
||||
self.b_c,
|
||||
self.b_o]))
|
||||
self.regularizers.append(self.b_regularizer)
|
||||
|
||||
self.trainable_weights = [self.W_i, self.U_i, self.b_i,
|
||||
self.W_c, self.U_c, self.b_c,
|
||||
@@ -419,8 +631,7 @@ class LSTM(Recurrent):
|
||||
input_shape = self.input_shape
|
||||
if not input_shape[0]:
|
||||
raise Exception('If a RNN is stateful, a complete ' +
|
||||
'input_shape must be provided ' +
|
||||
'(including batch size).')
|
||||
'input_shape must be provided (including batch size).')
|
||||
if hasattr(self, 'states'):
|
||||
K.set_value(self.states[0],
|
||||
np.zeros((input_shape[0], self.output_dim)))
|
||||
@@ -430,29 +641,65 @@ class LSTM(Recurrent):
|
||||
self.states = [K.zeros((input_shape[0], self.output_dim)),
|
||||
K.zeros((input_shape[0], self.output_dim))]
|
||||
|
||||
def preprocess_input(self, x, train=False):
|
||||
if train and (0 < self.dropout_W < 1):
|
||||
dropout = self.dropout_W
|
||||
else:
|
||||
dropout = 0
|
||||
input_shape = self.input_shape
|
||||
input_dim = input_shape[2]
|
||||
timesteps = input_shape[1]
|
||||
|
||||
x_i = time_distributed_dense(x, self.W_i, self.b_i, dropout,
|
||||
input_dim, self.output_dim, timesteps)
|
||||
x_f = time_distributed_dense(x, self.W_f, self.b_f, dropout,
|
||||
input_dim, self.output_dim, timesteps)
|
||||
x_c = time_distributed_dense(x, self.W_c, self.b_c, dropout,
|
||||
input_dim, self.output_dim, timesteps)
|
||||
x_o = time_distributed_dense(x, self.W_o, self.b_o, dropout,
|
||||
input_dim, self.output_dim, timesteps)
|
||||
return K.concatenate([x_i, x_f, x_c, x_o], axis=2)
|
||||
|
||||
def step(self, x, states):
|
||||
assert len(states) == 2
|
||||
h_tm1 = states[0]
|
||||
c_tm1 = states[1]
|
||||
if len(states) == 3:
|
||||
B_U = states[2]
|
||||
else:
|
||||
B_U = [1. for _ in range(4)]
|
||||
|
||||
x_i = K.dot(x, self.W_i) + self.b_i
|
||||
x_f = K.dot(x, self.W_f) + self.b_f
|
||||
x_c = K.dot(x, self.W_c) + self.b_c
|
||||
x_o = K.dot(x, self.W_o) + self.b_o
|
||||
x_i = x[:, :self.output_dim]
|
||||
x_f = x[:, self.output_dim: 2 * self.output_dim]
|
||||
x_c = x[:, 2 * self.output_dim: 3 * self.output_dim]
|
||||
x_o = x[:, 3 * self.output_dim:]
|
||||
|
||||
i = self.inner_activation(x_i + K.dot(h_tm1 * B_U[0], self.U_i))
|
||||
f = self.inner_activation(x_f + K.dot(h_tm1 * B_U[1], self.U_f))
|
||||
c = f * c_tm1 + i * self.activation(x_c + K.dot(h_tm1 * B_U[2], self.U_c))
|
||||
o = self.inner_activation(x_o + K.dot(h_tm1 * B_U[3], self.U_o))
|
||||
|
||||
i = self.inner_activation(x_i + K.dot(h_tm1, self.U_i))
|
||||
f = self.inner_activation(x_f + K.dot(h_tm1, self.U_f))
|
||||
c = f * c_tm1 + i * self.activation(x_c + K.dot(h_tm1, self.U_c))
|
||||
o = self.inner_activation(x_o + K.dot(h_tm1, self.U_o))
|
||||
h = o * self.activation(c)
|
||||
return h, [h, c]
|
||||
|
||||
def get_constants(self, x, train=False):
|
||||
if train and (0 < self.dropout_U < 1):
|
||||
ones = K.ones_like(K.reshape(x[:, 0, 0], (-1, 1)))
|
||||
ones = K.concatenate([ones] * self.output_dim, 1)
|
||||
B_U = [K.dropout(ones, self.dropout_U) for _ in range(4)]
|
||||
return [B_U]
|
||||
return []
|
||||
|
||||
def get_config(self):
|
||||
config = {"output_dim": self.output_dim,
|
||||
"init": self.init.__name__,
|
||||
"inner_init": self.inner_init.__name__,
|
||||
"forget_bias_init": self.forget_bias_init.__name__,
|
||||
"activation": self.activation.__name__,
|
||||
"inner_activation": self.inner_activation.__name__}
|
||||
"inner_activation": self.inner_activation.__name__,
|
||||
"W_regularizer": self.W_regularizer.get_config() if self.W_regularizer else None,
|
||||
"U_regularizer": self.U_regularizer.get_config() if self.U_regularizer else None,
|
||||
"b_regularizer": self.b_regularizer.get_config() if self.b_regularizer else None,
|
||||
"dropout_W": self.dropout_W,
|
||||
"dropout_U": self.dropout_U}
|
||||
base_config = super(LSTM, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
|
||||
@@ -0,0 +1,114 @@
|
||||
from .core import MaskedLayer
|
||||
from .. import backend as K
|
||||
|
||||
|
||||
class TimeDistributed(MaskedLayer):
|
||||
"""This wrapper allows to apply a layer to every
|
||||
temporal slice of an input.
|
||||
|
||||
The input should be at least 3D,
|
||||
and the dimension of index one will be considered to be
|
||||
the temporal dimension.
|
||||
|
||||
Consider a batch of 32 samples, where each sample is a sequence of 10
|
||||
vectors of 16 dimensions. The batch input shape of the layer is then `(32, 10, 16)`
|
||||
(and the `input_shape`, not including the samples dimension, is `(10, 16)`).
|
||||
|
||||
You can then use `TimeDistributed` to apply a `Dense` layer to each of the 10 timesteps, independently:
|
||||
```python
|
||||
model = Sequential()
|
||||
model.add(TimeDistributed(Dense(8), input_shape=(10, 16)))
|
||||
```
|
||||
|
||||
The output will then have shape `(32, 10, 8)`.
|
||||
|
||||
Note this is strictly equivalent to using `layers.core.TimeDistributedDense`.
|
||||
However what is different about `TimeDistributed`
|
||||
is that it can be used with arbitrary layers, not just `Dense`,
|
||||
for instance with a `Convolution2D` layer:
|
||||
|
||||
```python
|
||||
model = Sequential()
|
||||
model.add(TimeDistributed(Convolution2D(64, 3, 3), input_shape=(10, 3, 299, 299)))
|
||||
```
|
||||
|
||||
# Arguments
|
||||
layer: a layer instance.
|
||||
"""
|
||||
|
||||
def __init__(self, layer, **kwargs):
|
||||
self.layer = layer
|
||||
super(TimeDistributed, self).__init__(**kwargs)
|
||||
|
||||
def build(self):
|
||||
input_shape = self.input_shape
|
||||
assert len(input_shape) >= 3
|
||||
child_input_shape = (input_shape[0],) + input_shape[2:]
|
||||
self.layer.set_input_shape(child_input_shape)
|
||||
self.layer.build()
|
||||
|
||||
trainable_weights, regularizers, constraints, updates = self.layer.get_params()
|
||||
self.trainable_weights = trainable_weights
|
||||
self.non_trainable_weights = self.layer.non_trainable_weights
|
||||
self.regularizers = regularizers
|
||||
self.constraints = constraints
|
||||
self.updates = updates
|
||||
|
||||
@property
|
||||
def output_shape(self):
|
||||
child_output_shape = self.layer.output_shape
|
||||
timesteps = self.input_shape[1]
|
||||
return (child_output_shape[0], timesteps) + child_output_shape[1:]
|
||||
|
||||
def get_output(self, train=False):
|
||||
X = self.get_input(train)
|
||||
mask = self.get_input_mask(train)
|
||||
|
||||
if K._BACKEND == 'tensorflow':
|
||||
if not self.input_shape[1]:
|
||||
raise Exception('When using TensorFlow, you should define ' +
|
||||
'explicitly the number of timesteps of ' +
|
||||
'your sequences.\n' +
|
||||
'If your first layer is an Embedding, ' +
|
||||
'make sure to pass it an "input_length" ' +
|
||||
'argument. Otherwise, make sure ' +
|
||||
'the first layer has ' +
|
||||
'an "input_shape" or "batch_input_shape" ' +
|
||||
'argument, including the time axis.')
|
||||
|
||||
if self.input_shape[0]:
|
||||
# batch size matters, use rnn-based implementation
|
||||
def step(x, states):
|
||||
output = self.layer(x, train=train)
|
||||
return output, []
|
||||
|
||||
last_output, outputs, states = K.rnn(step, X,
|
||||
initial_states=[],
|
||||
mask=mask)
|
||||
y = outputs
|
||||
else:
|
||||
# no batch size specified, therefore the layer will be able
|
||||
# to process batches of any size
|
||||
# we can go with reshape-based implementation for performance
|
||||
input_shape = self.input_shape
|
||||
x = K.reshape(X, (-1, ) + input_shape[2:]) # (nb_samples * timesteps, ...)
|
||||
y = self.layer(x, train=False) # (nb_samples * timesteps, ...)
|
||||
input_length = input_shape[1]
|
||||
if not input_length:
|
||||
input_length = K.shape(X)[1]
|
||||
# (nb_samples, timesteps, ...)
|
||||
y = K.reshape(y, (-1, input_length) + self.layer.output_shape[1:])
|
||||
return y
|
||||
|
||||
def get_weights(self):
|
||||
weights = self.layer.get_weights()
|
||||
return weights
|
||||
|
||||
def set_weights(self, weights):
|
||||
self.layer.set_weights(weights)
|
||||
|
||||
def get_config(self):
|
||||
config = {'name': self.__class__.__name__,
|
||||
'layer': self.layer.get_config()}
|
||||
base_config = super(TimeDistributed, self).get_config()
|
||||
return dict(list(base_config.items()) + list(config.items()))
|
||||
+529
-235
Diferenças do arquivo suprimidas por serem muito extensas
Carregar Diff
@@ -1,3 +1,7 @@
|
||||
'''Fairly basic set of tools for realtime data augmentation on image data.
|
||||
Can easily be extended to include new transformations,
|
||||
new preprocessing methods, etc...
|
||||
'''
|
||||
from __future__ import absolute_import
|
||||
|
||||
import numpy as np
|
||||
@@ -7,18 +11,13 @@ from scipy import linalg
|
||||
|
||||
from os import listdir
|
||||
from os.path import isfile, join
|
||||
import random
|
||||
import math
|
||||
from six.moves import range
|
||||
import threading
|
||||
|
||||
'''Fairly basic set of tools for realtime data augmentation on image data.
|
||||
Can easily be extended to include new transformations, new preprocessing methods, etc...
|
||||
'''
|
||||
|
||||
|
||||
def random_rotation(x, rg, fill_mode="nearest", cval=0.):
|
||||
angle = random.uniform(-rg, rg)
|
||||
def random_rotation(x, rg, fill_mode='nearest', cval=0.):
|
||||
angle = np.random.uniform(-rg, rg)
|
||||
x = ndimage.interpolation.rotate(x, angle,
|
||||
axes=(1, 2),
|
||||
reshape=False,
|
||||
@@ -27,19 +26,14 @@ def random_rotation(x, rg, fill_mode="nearest", cval=0.):
|
||||
return x
|
||||
|
||||
|
||||
def random_shift(x, wrg, hrg, fill_mode="nearest", cval=0.):
|
||||
crop_left_pixels = 0
|
||||
crop_top_pixels = 0
|
||||
def random_shift(x, wrg, hrg, fill_mode='nearest', cval=0.):
|
||||
shift_x = shift_y = 0
|
||||
|
||||
if wrg:
|
||||
crop = random.uniform(0., wrg)
|
||||
split = random.uniform(0, 1)
|
||||
crop_left_pixels = int(split*crop*x.shape[1])
|
||||
shift_x = np.random.uniform(-wrg, wrg) * x.shape[2]
|
||||
if hrg:
|
||||
crop = random.uniform(0., hrg)
|
||||
split = random.uniform(0, 1)
|
||||
crop_top_pixels = int(split*crop*x.shape[2])
|
||||
x = ndimage.interpolation.shift(x, (0, crop_left_pixels, crop_top_pixels),
|
||||
shift_y = np.random.uniform(-hrg, hrg) * x.shape[1]
|
||||
x = ndimage.interpolation.shift(x, (0, shift_y, shift_x),
|
||||
order=0,
|
||||
mode=fill_mode,
|
||||
cval=cval)
|
||||
@@ -63,8 +57,8 @@ def random_barrel_transform(x, intensity):
|
||||
pass
|
||||
|
||||
|
||||
def random_shear(x, intensity, fill_mode="nearest", cval=0.):
|
||||
shear = random.uniform(-intensity, intensity)
|
||||
def random_shear(x, intensity, fill_mode='nearest', cval=0.):
|
||||
shear = np.random.uniform(-intensity, intensity)
|
||||
shear_matrix = np.array([[1.0, -math.sin(shear), 0.0],
|
||||
[0.0, math.cos(shear), 0.0],
|
||||
[0.0, 0.0, 1.0]])
|
||||
@@ -80,9 +74,9 @@ def random_channel_shift(x, rg):
|
||||
pass
|
||||
|
||||
|
||||
def random_zoom(x, rg, fill_mode="nearest", cval=0.):
|
||||
zoom_w = random.uniform(1.-rg, 1.)
|
||||
zoom_h = random.uniform(1.-rg, 1.)
|
||||
def random_zoom(x, rg, fill_mode='nearest', cval=0.):
|
||||
zoom_w = np.random.uniform(1.-rg, 1.)
|
||||
zoom_h = np.random.uniform(1.-rg, 1.)
|
||||
x = ndimage.interpolation.zoom(x, zoom=(1., zoom_w, zoom_h),
|
||||
mode=fill_mode,
|
||||
cval=cval)
|
||||
@@ -98,10 +92,10 @@ def array_to_img(x, scale=True):
|
||||
x *= 255
|
||||
if x.shape[2] == 3:
|
||||
# RGB
|
||||
return Image.fromarray(x.astype("uint8"), "RGB")
|
||||
return Image.fromarray(x.astype('uint8'), 'RGB')
|
||||
else:
|
||||
# grayscale
|
||||
return Image.fromarray(x[:, :, 0].astype("uint8"), "L")
|
||||
return Image.fromarray(x[:, :, 0].astype('uint8'), 'L')
|
||||
|
||||
|
||||
def img_to_array(img):
|
||||
@@ -132,21 +126,33 @@ def list_pictures(directory, ext='jpg|jpeg|bmp|png'):
|
||||
|
||||
class ImageDataGenerator(object):
|
||||
'''Generate minibatches with
|
||||
realtime data augmentation.
|
||||
real-time data augmentation.
|
||||
|
||||
# Arguments
|
||||
featurewise_center: set input mean to 0 over the dataset.
|
||||
samplewise_center: set each sample mean to 0.
|
||||
featurewise_std_normalization: divide inputs by std of the dataset.
|
||||
samplewise_std_normalization: divide each input by its std.
|
||||
zca_whitening: apply ZCA whitening.
|
||||
rotation_range: degrees (0 to 180).
|
||||
width_shift_range: fraction of total width.
|
||||
height_shift_range: fraction of total height.
|
||||
shear_range: shear intensity (shear angle in radians).
|
||||
horizontal_flip: whether to randomly flip images horizontally.
|
||||
vertical_flip: whether to randomly flip images vertically.
|
||||
'''
|
||||
def __init__(self,
|
||||
featurewise_center=True, # set input mean to 0 over the dataset
|
||||
samplewise_center=False, # set each sample mean to 0
|
||||
featurewise_std_normalization=True, # divide inputs by std of the dataset
|
||||
samplewise_std_normalization=False, # divide each input by its std
|
||||
zca_whitening=False, # apply ZCA whitening
|
||||
rotation_range=0., # degrees (0 to 180)
|
||||
width_shift_range=0., # fraction of total width
|
||||
height_shift_range=0., # fraction of total height
|
||||
shear_range=0., # shear intensity (shear angle in radians)
|
||||
featurewise_center=True,
|
||||
samplewise_center=False,
|
||||
featurewise_std_normalization=True,
|
||||
samplewise_std_normalization=False,
|
||||
zca_whitening=False,
|
||||
rotation_range=0.,
|
||||
width_shift_range=0.,
|
||||
height_shift_range=0.,
|
||||
shear_range=0.,
|
||||
horizontal_flip=False,
|
||||
vertical_flip=False):
|
||||
|
||||
self.__dict__.update(locals())
|
||||
self.mean = None
|
||||
self.std = None
|
||||
@@ -177,26 +183,30 @@ class ImageDataGenerator(object):
|
||||
else:
|
||||
b = 0
|
||||
total_b += 1
|
||||
yield index_array[current_index: current_index + current_batch_size], current_index, current_batch_size
|
||||
yield (index_array[current_index: current_index + current_batch_size],
|
||||
current_index, current_batch_size)
|
||||
|
||||
def flow(self, X, y, batch_size=32, shuffle=False, seed=None,
|
||||
save_to_dir=None, save_prefix="", save_format="jpeg"):
|
||||
save_to_dir=None, save_prefix='', save_format='jpeg'):
|
||||
assert len(X) == len(y)
|
||||
self.X = X
|
||||
self.y = y
|
||||
self.save_to_dir = save_to_dir
|
||||
self.save_prefix = save_prefix
|
||||
self.save_format = save_format
|
||||
self.flow_generator = self._flow_index(X.shape[0], batch_size, shuffle, seed)
|
||||
self.flow_generator = self._flow_index(X.shape[0], batch_size,
|
||||
shuffle, seed)
|
||||
return self
|
||||
|
||||
def __iter__(self):
|
||||
# needed if we want to do something like for x,y in data_gen.flow(...):
|
||||
# needed if we want to do something like:
|
||||
# for x, y in data_gen.flow(...):
|
||||
return self
|
||||
|
||||
def next(self):
|
||||
# for python 2.x
|
||||
# Keep under lock only the mechainsem which advance the indexing of each batch
|
||||
# for python 2.x.
|
||||
# Keeps under lock only the mechanism which advances
|
||||
# the indexing of each batch
|
||||
# see # http://anandology.com/blog/using-iterators-and-generators/
|
||||
with self.lock:
|
||||
index_array, current_index, current_batch_size = next(self.flow_generator)
|
||||
@@ -204,36 +214,36 @@ class ImageDataGenerator(object):
|
||||
bX = np.zeros(tuple([current_batch_size] + list(self.X.shape)[1:]))
|
||||
for i, j in enumerate(index_array):
|
||||
x = self.X[j]
|
||||
x = self.random_transform(x.astype("float32"))
|
||||
x = self.random_transform(x.astype('float32'))
|
||||
x = self.standardize(x)
|
||||
bX[i] = x
|
||||
if self.save_to_dir:
|
||||
for i in range(current_batch_size):
|
||||
img = array_to_img(bX[i], scale=True)
|
||||
img.save(self.save_to_dir + "/" + self.save_prefix + "_" + str(current_index + i) + "." + self.save_format)
|
||||
img.save(self.save_to_dir + '/' + self.save_prefix + '_' + str(current_index + i) + '.' + self.save_format)
|
||||
bY = self.y[index_array]
|
||||
return bX, bY
|
||||
|
||||
def __next__(self):
|
||||
# for python 3.x
|
||||
# for python 3.x.
|
||||
return self.next()
|
||||
|
||||
def standardize(self, x):
|
||||
if self.samplewise_center:
|
||||
x -= np.mean(x, axis=1, keepdims=True)
|
||||
if self.samplewise_std_normalization:
|
||||
x /= (np.std(x, axis=1, keepdims=True) + 1e-7)
|
||||
|
||||
if self.featurewise_center:
|
||||
x -= self.mean
|
||||
if self.featurewise_std_normalization:
|
||||
x /= self.std
|
||||
x /= (self.std + 1e-7)
|
||||
|
||||
if self.zca_whitening:
|
||||
flatx = np.reshape(x, (x.shape[0]*x.shape[1]*x.shape[2]))
|
||||
flatx = np.reshape(x, (x.shape[0] * x.shape[1] * x.shape[2]))
|
||||
whitex = np.dot(flatx, self.principal_components)
|
||||
x = np.reshape(whitex, (x.shape[0], x.shape[1], x.shape[2]))
|
||||
|
||||
if self.samplewise_center:
|
||||
x -= np.mean(x)
|
||||
if self.samplewise_std_normalization:
|
||||
x /= np.std(x)
|
||||
|
||||
return x
|
||||
|
||||
def random_transform(self, x):
|
||||
@@ -242,34 +252,41 @@ class ImageDataGenerator(object):
|
||||
if self.width_shift_range or self.height_shift_range:
|
||||
x = random_shift(x, self.width_shift_range, self.height_shift_range)
|
||||
if self.horizontal_flip:
|
||||
if random.random() < 0.5:
|
||||
if np.random.random() < 0.5:
|
||||
x = horizontal_flip(x)
|
||||
if self.vertical_flip:
|
||||
if random.random() < 0.5:
|
||||
if np.random.random() < 0.5:
|
||||
x = vertical_flip(x)
|
||||
if self.shear_range:
|
||||
x = random_shear(x,self.shear_range)
|
||||
x = random_shear(x, self.shear_range)
|
||||
# TODO:
|
||||
# zoom
|
||||
# barrel/fisheye
|
||||
# shearing
|
||||
# channel shifting
|
||||
return x
|
||||
|
||||
def fit(self, X,
|
||||
augment=False, # fit on randomly augmented samples
|
||||
rounds=1, # if augment, how many augmentation passes over the data do we use
|
||||
augment=False,
|
||||
rounds=1,
|
||||
seed=None):
|
||||
'''Required for featurewise_center, featurewise_std_normalization and zca_whitening.
|
||||
'''Required for featurewise_center, featurewise_std_normalization
|
||||
and zca_whitening.
|
||||
|
||||
# Arguments
|
||||
X: Numpy array, the data to fit on.
|
||||
augment: whether to fit on randomly augmented samples
|
||||
rounds: if `augment`,
|
||||
how many augmentation passes to do over the data
|
||||
seed: random seed.
|
||||
'''
|
||||
X = np.copy(X)
|
||||
if augment:
|
||||
aX = np.zeros(tuple([rounds*X.shape[0]]+list(X.shape)[1:]))
|
||||
aX = np.zeros(tuple([rounds * X.shape[0]] + list(X.shape)[1:]))
|
||||
for r in range(rounds):
|
||||
for i in range(X.shape[0]):
|
||||
img = array_to_img(X[i])
|
||||
img = self.random_transform(img)
|
||||
aX[i+r*X.shape[0]] = img_to_array(img)
|
||||
aX[i + r * X.shape[0]] = img_to_array(img)
|
||||
X = aX
|
||||
|
||||
if self.featurewise_center:
|
||||
@@ -277,14 +294,13 @@ class ImageDataGenerator(object):
|
||||
X -= self.mean
|
||||
if self.featurewise_std_normalization:
|
||||
self.std = np.std(X, axis=0)
|
||||
X /= self.std
|
||||
X /= (self.std + 1e-7)
|
||||
|
||||
if self.zca_whitening:
|
||||
flatX = np.reshape(X, (X.shape[0], X.shape[1]*X.shape[2]*X.shape[3]))
|
||||
fudge = 10e-6
|
||||
flatX = np.reshape(X, (X.shape[0], X.shape[1] * X.shape[2] * X.shape[3]))
|
||||
sigma = np.dot(flatX.T, flatX) / flatX.shape[1]
|
||||
U, S, V = linalg.svd(sigma)
|
||||
self.principal_components = np.dot(np.dot(U, np.diag(1. / np.sqrt(S + fudge))), U.T)
|
||||
self.principal_components = np.dot(np.dot(U, np.diag(1. / np.sqrt(S + 10e-7))), U.T)
|
||||
|
||||
|
||||
class GraphImageDataGenerator(ImageDataGenerator):
|
||||
|
||||
@@ -4,19 +4,20 @@ import numpy as np
|
||||
import random
|
||||
from six.moves import range
|
||||
|
||||
def pad_sequences(sequences, maxlen=None, dtype='int32', padding='pre', truncating='pre', value=0.):
|
||||
"""
|
||||
Pad each sequence to the same length:
|
||||
the length of the longest sequence.
|
||||
|
||||
If maxlen is provided, any sequence longer
|
||||
than maxlen is truncated to maxlen. Truncation happens off either the beginning (default) or
|
||||
the end of the sequence.
|
||||
def pad_sequences(sequences, maxlen=None, dtype='int32',
|
||||
padding='pre', truncating='pre', value=0.):
|
||||
'''Pads each sequence to the same length:
|
||||
the length of the longest sequence.
|
||||
|
||||
Supports post-padding and pre-padding (default).
|
||||
If maxlen is provided, any sequence longer
|
||||
than maxlen is truncated to maxlen.
|
||||
Truncation happens off either the beginning (default) or
|
||||
the end of the sequence.
|
||||
|
||||
Parameters:
|
||||
-----------
|
||||
Supports post-padding and pre-padding (default).
|
||||
|
||||
# Arguments
|
||||
sequences: list of lists where each element is a sequence
|
||||
maxlen: int, maximum length
|
||||
dtype: type to cast the resulting sequence.
|
||||
@@ -25,53 +26,64 @@ def pad_sequences(sequences, maxlen=None, dtype='int32', padding='pre', truncati
|
||||
maxlen either in the beginning or in the end of the sequence
|
||||
value: float, value to pad the sequences to the desired value.
|
||||
|
||||
Returns:
|
||||
# Returns
|
||||
x: numpy array with dimensions (number_of_sequences, maxlen)
|
||||
|
||||
"""
|
||||
'''
|
||||
lengths = [len(s) for s in sequences]
|
||||
|
||||
nb_samples = len(sequences)
|
||||
if maxlen is None:
|
||||
maxlen = np.max(lengths)
|
||||
|
||||
x = (np.ones((nb_samples, maxlen)) * value).astype(dtype)
|
||||
# take the sample shape from the first non empty sequence
|
||||
# checking for consistency in the main loop below.
|
||||
sample_shape = tuple()
|
||||
for s in sequences:
|
||||
if len(s) > 0:
|
||||
sample_shape = np.asarray(s).shape[1:]
|
||||
break
|
||||
|
||||
x = (np.ones((nb_samples, maxlen) + sample_shape) * value).astype(dtype)
|
||||
for idx, s in enumerate(sequences):
|
||||
if len(s) == 0:
|
||||
continue # empty list was found
|
||||
continue # empty list was found
|
||||
if truncating == 'pre':
|
||||
trunc = s[-maxlen:]
|
||||
elif truncating == 'post':
|
||||
trunc = s[:maxlen]
|
||||
else:
|
||||
raise ValueError("Truncating type '%s' not understood" % padding)
|
||||
raise ValueError('Truncating type "%s" not understood' % truncating)
|
||||
|
||||
# check `trunc` has expected shape
|
||||
trunc = np.asarray(trunc, dtype=dtype)
|
||||
if trunc.shape[1:] != sample_shape:
|
||||
raise ValueError('Shape of sample %s of sequence at position %s is different from expected shape %s' %
|
||||
(trunc.shape[1:], idx, sample_shape))
|
||||
|
||||
if padding == 'post':
|
||||
x[idx, :len(trunc)] = trunc
|
||||
elif padding == 'pre':
|
||||
x[idx, -len(trunc):] = trunc
|
||||
else:
|
||||
raise ValueError("Padding type '%s' not understood" % padding)
|
||||
raise ValueError('Padding type "%s" not understood' % padding)
|
||||
return x
|
||||
|
||||
|
||||
def make_sampling_table(size, sampling_factor=1e-5):
|
||||
'''
|
||||
This generates an array where the ith element
|
||||
is the probability that a word of rank i would be sampled,
|
||||
according to the sampling distribution used in word2vec.
|
||||
'''This generates an array where the ith element
|
||||
is the probability that a word of rank i would be sampled,
|
||||
according to the sampling distribution used in word2vec.
|
||||
|
||||
The word2vec formula is:
|
||||
p(word) = min(1, sqrt(word.frequency/sampling_factor) / (word.frequency/sampling_factor))
|
||||
The word2vec formula is:
|
||||
p(word) = min(1, sqrt(word.frequency/sampling_factor) / (word.frequency/sampling_factor))
|
||||
|
||||
We assume that the word frequencies follow Zipf's law (s=1) to derive
|
||||
a numerical approximation of frequency(rank):
|
||||
frequency(rank) ~ 1/(rank * (log(rank) + gamma) + 1/2 - 1/(12*rank))
|
||||
We assume that the word frequencies follow Zipf's law (s=1) to derive
|
||||
a numerical approximation of frequency(rank):
|
||||
frequency(rank) ~ 1/(rank * (log(rank) + gamma) + 1/2 - 1/(12*rank))
|
||||
where gamma is the Euler-Mascheroni constant.
|
||||
|
||||
Parameters:
|
||||
-----------
|
||||
size: int, number of possible words to sample.
|
||||
# Arguments
|
||||
size: int, number of possible words to sample.
|
||||
'''
|
||||
gamma = 0.577
|
||||
rank = np.array(list(range(size)))
|
||||
@@ -85,28 +97,28 @@ def make_sampling_table(size, sampling_factor=1e-5):
|
||||
def skipgrams(sequence, vocabulary_size,
|
||||
window_size=4, negative_samples=1., shuffle=True,
|
||||
categorical=False, sampling_table=None):
|
||||
'''
|
||||
Take a sequence (list of indexes of words),
|
||||
returns couples of [word_index, other_word index] and labels (1s or 0s),
|
||||
where label = 1 if 'other_word' belongs to the context of 'word',
|
||||
and label=0 if 'other_word' is ramdomly sampled
|
||||
'''Take a sequence (list of indexes of words),
|
||||
returns couples of [word_index, other_word index] and labels (1s or 0s),
|
||||
where label = 1 if 'other_word' belongs to the context of 'word',
|
||||
and label=0 if 'other_word' is ramdomly sampled
|
||||
|
||||
Paramaters:
|
||||
-----------
|
||||
# Arguments
|
||||
vocabulary_size: int. maximum possible word index + 1
|
||||
window_size: int. actually half-window. The window of a word wi will be [i-window_size, i+window_size+1]
|
||||
negative_samples: float >= 0. 0 for no negative (=random) samples. 1 for same number as positive samples. etc.
|
||||
categorical: bool. if False, labels will be integers (eg. [0, 1, 1 .. ]),
|
||||
window_size: int. actually half-window.
|
||||
The window of a word wi will be [i-window_size, i+window_size+1]
|
||||
negative_samples: float >= 0. 0 for no negative (=random) samples.
|
||||
1 for same number as positive samples. etc.
|
||||
categorical: bool. if False, labels will be
|
||||
integers (eg. [0, 1, 1 .. ]),
|
||||
if True labels will be categorical eg. [[1,0],[0,1],[0,1] .. ]
|
||||
|
||||
Returns:
|
||||
--------
|
||||
# Returns
|
||||
couples, lables: where `couples` are int pairs and
|
||||
`labels` are either 0 or 1.
|
||||
|
||||
Notes:
|
||||
------
|
||||
By convention, index 0 in the vocabulary is a non-word and will be skipped.
|
||||
# Notes
|
||||
By convention, index 0 in the vocabulary is
|
||||
a non-word and will be skipped.
|
||||
'''
|
||||
couples = []
|
||||
labels = []
|
||||
|
||||
@@ -1,7 +1,6 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
'''
|
||||
These preprocessing utils would greatly benefit
|
||||
from a fast Cython rewrite.
|
||||
'''These preprocessing utilities would greatly benefit
|
||||
from a fast Cython rewrite.
|
||||
'''
|
||||
from __future__ import absolute_import
|
||||
|
||||
@@ -75,8 +74,7 @@ class Tokenizer(object):
|
||||
self.char_level = char_level
|
||||
|
||||
def fit_on_texts(self, texts):
|
||||
'''
|
||||
required before using texts_to_sequences or texts_to_matrix
|
||||
'''Required before using texts_to_sequences or texts_to_matrix
|
||||
|
||||
# Arguments
|
||||
texts: can be a list of strings,
|
||||
@@ -107,9 +105,8 @@ class Tokenizer(object):
|
||||
self.index_docs[self.word_index[w]] = c
|
||||
|
||||
def fit_on_sequences(self, sequences):
|
||||
'''
|
||||
required before using sequences_to_matrix
|
||||
(if fit_on_texts was never called)
|
||||
'''Required before using sequences_to_matrix
|
||||
(if fit_on_texts was never called)
|
||||
'''
|
||||
self.document_count = len(sequences)
|
||||
self.index_docs = {}
|
||||
@@ -122,12 +119,11 @@ class Tokenizer(object):
|
||||
self.index_docs[i] += 1
|
||||
|
||||
def texts_to_sequences(self, texts):
|
||||
'''
|
||||
Transform each text in texts in a sequence of integers.
|
||||
Only top "nb_words" most frequent words will be taken into account.
|
||||
Only words known by the tokenizer will be taken into account.
|
||||
'''Transforms each text in texts in a sequence of integers.
|
||||
Only top "nb_words" most frequent words will be taken into account.
|
||||
Only words known by the tokenizer will be taken into account.
|
||||
|
||||
Returns a list of sequences.
|
||||
Returns a list of sequences.
|
||||
'''
|
||||
res = []
|
||||
for vect in self.texts_to_sequences_generator(texts):
|
||||
@@ -135,12 +131,14 @@ class Tokenizer(object):
|
||||
return res
|
||||
|
||||
def texts_to_sequences_generator(self, texts):
|
||||
'''
|
||||
Transform each text in texts in a sequence of integers.
|
||||
Only top "nb_words" most frequent words will be taken into account.
|
||||
Only words known by the tokenizer will be taken into account.
|
||||
'''Transforms each text in texts in a sequence of integers.
|
||||
Only top "nb_words" most frequent words will be taken into account.
|
||||
Only words known by the tokenizer will be taken into account.
|
||||
|
||||
Yields individual sequences.
|
||||
Yields individual sequences.
|
||||
|
||||
# Arguments:
|
||||
texts: list of strings.
|
||||
'''
|
||||
nb_words = self.nb_words
|
||||
for text in texts:
|
||||
@@ -150,56 +148,67 @@ class Tokenizer(object):
|
||||
i = self.word_index.get(w)
|
||||
if i is not None:
|
||||
if nb_words and i >= nb_words:
|
||||
pass
|
||||
continue
|
||||
else:
|
||||
vect.append(i)
|
||||
yield vect
|
||||
|
||||
def texts_to_matrix(self, texts, mode="binary"):
|
||||
'''
|
||||
modes: binary, count, tfidf, freq
|
||||
def texts_to_matrix(self, texts, mode='binary'):
|
||||
'''Convert a list of texts to a Numpy matrix,
|
||||
according to some vectorization mode.
|
||||
|
||||
# Arguments:
|
||||
texts: list of strings.
|
||||
modes: one of "binary", "count", "tfidf", "freq"
|
||||
'''
|
||||
sequences = self.texts_to_sequences(texts)
|
||||
return self.sequences_to_matrix(sequences, mode=mode)
|
||||
|
||||
def sequences_to_matrix(self, sequences, mode="binary"):
|
||||
'''
|
||||
modes: binary, count, tfidf, freq
|
||||
def sequences_to_matrix(self, sequences, mode='binary'):
|
||||
'''Converts a list of sequences into a Numpy matrix,
|
||||
according to some vectorization mode.
|
||||
|
||||
# Arguments:
|
||||
sequences: list of sequences
|
||||
(a sequence is a list of integer word indices).
|
||||
modes: one of "binary", "count", "tfidf", "freq"
|
||||
'''
|
||||
if not self.nb_words:
|
||||
if self.word_index:
|
||||
nb_words = len(self.word_index) + 1
|
||||
else:
|
||||
raise Exception("Specify a dimension (nb_words argument), or fit on some text data first.")
|
||||
raise Exception('Specify a dimension (nb_words argument), '
|
||||
'or fit on some text data first.')
|
||||
else:
|
||||
nb_words = self.nb_words
|
||||
|
||||
if mode == "tfidf" and not self.document_count:
|
||||
raise Exception("Fit the Tokenizer on some data before using tfidf mode.")
|
||||
if mode == 'tfidf' and not self.document_count:
|
||||
raise Exception('Fit the Tokenizer on some data '
|
||||
'before using tfidf mode.')
|
||||
|
||||
X = np.zeros((len(sequences), nb_words))
|
||||
for i, seq in enumerate(sequences):
|
||||
if not seq:
|
||||
pass
|
||||
continue
|
||||
counts = {}
|
||||
for j in seq:
|
||||
if j >= nb_words:
|
||||
pass
|
||||
continue
|
||||
if j not in counts:
|
||||
counts[j] = 1.
|
||||
else:
|
||||
counts[j] += 1
|
||||
for j, c in list(counts.items()):
|
||||
if mode == "count":
|
||||
if mode == 'count':
|
||||
X[i][j] = c
|
||||
elif mode == "freq":
|
||||
elif mode == 'freq':
|
||||
X[i][j] = c / len(seq)
|
||||
elif mode == "binary":
|
||||
elif mode == 'binary':
|
||||
X[i][j] = 1
|
||||
elif mode == "tfidf":
|
||||
elif mode == 'tfidf':
|
||||
tf = np.log(c / len(seq))
|
||||
df = (1 + np.log(1 + self.index_docs.get(j, 0) / (1 + self.document_count)))
|
||||
X[i][j] = tf / df
|
||||
else:
|
||||
raise Exception("Unknown vectorization mode: " + str(mode))
|
||||
raise Exception('Unknown vectorization mode: ' + str(mode))
|
||||
return X
|
||||
|
||||
@@ -0,0 +1,95 @@
|
||||
from __future__ import absolute_import
|
||||
from __future__ import print_function
|
||||
|
||||
import tarfile
|
||||
import os
|
||||
import sys
|
||||
import shutil
|
||||
from six.moves.urllib.request import urlopen
|
||||
from six.moves.urllib.error import URLError, HTTPError
|
||||
|
||||
from ..utils.generic_utils import Progbar
|
||||
|
||||
|
||||
# Under Python 2, 'urlretrieve' relies on FancyURLopener from legacy
|
||||
# urllib module, known to have issues with proxy management
|
||||
if sys.version_info[0] == 2:
|
||||
def urlretrieve(url, filename, reporthook=None, data=None):
|
||||
def chunk_read(response, chunk_size=8192, reporthook=None):
|
||||
total_size = response.info().get('Content-Length').strip()
|
||||
total_size = int(total_size)
|
||||
count = 0
|
||||
while 1:
|
||||
chunk = response.read(chunk_size)
|
||||
if not chunk:
|
||||
break
|
||||
count += 1
|
||||
if reporthook:
|
||||
reporthook(count, chunk_size, total_size)
|
||||
yield chunk
|
||||
|
||||
response = urlopen(url, data)
|
||||
with open(filename, 'wb') as fd:
|
||||
for chunk in chunk_read(response, reporthook=reporthook):
|
||||
fd.write(chunk)
|
||||
else:
|
||||
from six.moves.urllib.request import urlretrieve
|
||||
|
||||
|
||||
def get_file(fname, origin, untar=False):
|
||||
datadir_base = os.path.expanduser(os.path.join('~', '.keras'))
|
||||
if not os.access(datadir_base, os.W_OK):
|
||||
datadir_base = os.path.join('/tmp', '.keras')
|
||||
datadir = os.path.join(datadir_base, 'datasets')
|
||||
if not os.path.exists(datadir):
|
||||
os.makedirs(datadir)
|
||||
|
||||
if untar:
|
||||
untar_fpath = os.path.join(datadir, fname)
|
||||
fpath = untar_fpath + '.tar.gz'
|
||||
else:
|
||||
fpath = os.path.join(datadir, fname)
|
||||
|
||||
if not os.path.exists(fpath):
|
||||
print('Downloading data from', origin)
|
||||
global progbar
|
||||
progbar = None
|
||||
|
||||
def dl_progress(count, block_size, total_size):
|
||||
global progbar
|
||||
if progbar is None:
|
||||
progbar = Progbar(total_size)
|
||||
else:
|
||||
progbar.update(count*block_size)
|
||||
|
||||
error_msg = 'URL fetch failure on {}: {} -- {}'
|
||||
try:
|
||||
try:
|
||||
urlretrieve(origin, fpath, dl_progress)
|
||||
except URLError as e:
|
||||
raise Exception(error_msg.format(origin, e.errno, e.reason))
|
||||
except HTTPError as e:
|
||||
raise Exception(error_msg.format(origin, e.code, e.msg))
|
||||
except (Exception, KeyboardInterrupt) as e:
|
||||
if os.path.exists(fpath):
|
||||
os.remove(fpath)
|
||||
raise e
|
||||
progbar = None
|
||||
|
||||
if untar:
|
||||
if not os.path.exists(untar_fpath):
|
||||
print('Untaring file...')
|
||||
tfile = tarfile.open(fpath, 'r:gz')
|
||||
try:
|
||||
tfile.extractall(path=datadir)
|
||||
except (Exception, KeyboardInterrupt) as e:
|
||||
if os.path.exists(untar_fpath):
|
||||
if os.path.isfile(untar_fpath):
|
||||
os.remove(untar_fpath)
|
||||
else:
|
||||
shutil.rmtree(untar_fpath)
|
||||
raise e
|
||||
tfile.close()
|
||||
return untar_fpath
|
||||
|
||||
return fpath
|
||||
@@ -63,15 +63,15 @@ class Progbar(object):
|
||||
numdigits = int(np.floor(np.log10(self.target))) + 1
|
||||
barstr = '%%%dd/%%%dd [' % (numdigits, numdigits)
|
||||
bar = barstr % (current, self.target)
|
||||
prog = float(current)/self.target
|
||||
prog_width = int(self.width*prog)
|
||||
prog = float(current) / self.target
|
||||
prog_width = int(self.width * prog)
|
||||
if prog_width > 0:
|
||||
bar += ('='*(prog_width-1))
|
||||
bar += ('=' * (prog_width-1))
|
||||
if current < self.target:
|
||||
bar += '>'
|
||||
else:
|
||||
bar += '='
|
||||
bar += ('.'*(self.width-prog_width))
|
||||
bar += ('.' * (self.width - prog_width))
|
||||
bar += ']'
|
||||
sys.stdout.write(bar)
|
||||
self.total_width = len(bar)
|
||||
@@ -80,7 +80,7 @@ class Progbar(object):
|
||||
time_per_unit = (now - self.start) / current
|
||||
else:
|
||||
time_per_unit = 0
|
||||
eta = time_per_unit*(self.target - current)
|
||||
eta = time_per_unit * (self.target - current)
|
||||
info = ''
|
||||
if current < self.target:
|
||||
info += ' - ETA: %ds' % eta
|
||||
@@ -99,7 +99,7 @@ class Progbar(object):
|
||||
|
||||
self.total_width += len(info)
|
||||
if prev_total_width > self.total_width:
|
||||
info += ((prev_total_width-self.total_width) * " ")
|
||||
info += ((prev_total_width - self.total_width) * " ")
|
||||
|
||||
sys.stdout.write(info)
|
||||
sys.stdout.flush()
|
||||
@@ -120,4 +120,4 @@ class Progbar(object):
|
||||
sys.stdout.write(info + "\n")
|
||||
|
||||
def add(self, n, values=[]):
|
||||
self.update(self.seen_so_far+n, values)
|
||||
self.update(self.seen_so_far + n, values)
|
||||
|
||||
@@ -10,6 +10,7 @@ from ..layers.embeddings import *
|
||||
from ..layers.noise import *
|
||||
from ..layers.normalization import *
|
||||
from ..layers.recurrent import *
|
||||
from ..layers.wrappers import *
|
||||
from ..layers import containers
|
||||
from .. import regularizers
|
||||
from .. import constraints
|
||||
@@ -56,6 +57,7 @@ def container_from_config(original_layer_dict, custom_objects={}):
|
||||
for node in nodes:
|
||||
layer = container_from_config(layer_dict['nodes'].get(node['name']))
|
||||
node['layer'] = layer
|
||||
node['create_output'] = False # outputs will be added below
|
||||
graph_layer.add_node(**node)
|
||||
|
||||
outputs = layer_dict.get('output_config')
|
||||
@@ -71,6 +73,13 @@ def container_from_config(original_layer_dict, custom_objects={}):
|
||||
kwargs[kwarg] = layer_dict[kwarg]
|
||||
return AutoEncoder(**kwargs)
|
||||
|
||||
elif name == 'TimeDistributed':
|
||||
child_layer = container_from_config(layer_dict.pop('layer'))
|
||||
# the "name" keyword argument of layers is saved as "custom_name"
|
||||
if 'custom_name' in layer_dict:
|
||||
layer_dict['name'] = layer_dict.pop('custom_name')
|
||||
return TimeDistributed(child_layer, **layer_dict)
|
||||
|
||||
else: # this is a non-topological layer (e.g. Dense, etc.)
|
||||
layer_dict.pop('name')
|
||||
|
||||
@@ -89,6 +98,7 @@ def container_from_config(original_layer_dict, custom_objects={}):
|
||||
# the "name" keyword argument of layers is saved as "custom_name"
|
||||
if 'custom_name' in layer_dict:
|
||||
layer_dict['name'] = layer_dict.pop('custom_name')
|
||||
|
||||
base_layer = get_layer(name, layer_dict)
|
||||
return base_layer
|
||||
|
||||
|
||||
@@ -149,6 +149,6 @@ def to_graph(model, **kwargs):
|
||||
return ModelToDot()(model, **kwargs)
|
||||
|
||||
|
||||
def plot(model, to_file='model.png'):
|
||||
graph = to_graph(model)
|
||||
def plot(model, to_file='model.png', **kwargs):
|
||||
graph = to_graph(model, **kwargs)
|
||||
graph.write_png(to_file)
|
||||
|
||||
+213
-211
@@ -1,266 +1,268 @@
|
||||
from __future__ import absolute_import
|
||||
import abc
|
||||
import copy
|
||||
import inspect
|
||||
import types
|
||||
import numpy as np
|
||||
|
||||
from ..utils.np_utils import to_categorical
|
||||
from ..models import Sequential
|
||||
|
||||
|
||||
class BaseWrapper(object):
|
||||
"""
|
||||
Base class for the Keras scikit-learn wrapper.
|
||||
'''Base class for the Keras scikit-learn wrapper.
|
||||
|
||||
Warning: This class should not be used directly. Use derived classes instead.
|
||||
Warning: This class should not be used directly.
|
||||
Use descendant classes instead.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
train_batch_size : int, optional
|
||||
Number of training samples evaluated at a time.
|
||||
test_batch_size : int, optional
|
||||
Number of test samples evaluated at a time.
|
||||
nb_epochs : int, optional
|
||||
Number of training epochs.
|
||||
shuffle : boolean, optional
|
||||
Whether to shuffle the samples at each epoch.
|
||||
show_accuracy : boolean, optional
|
||||
Whether to display class accuracy in the logs at each epoch.
|
||||
validation_split : float [0, 1], optional
|
||||
Fraction of the data to use as held-out validation data.
|
||||
validation_data : tuple (X, y), optional
|
||||
Data to be used as held-out validation data. Will override validation_split.
|
||||
callbacks : list, optional
|
||||
List of callbacks to apply during training.
|
||||
verbose : int, optional
|
||||
Verbosity level.
|
||||
"""
|
||||
__metaclass__ = abc.ABCMeta
|
||||
# Arguments
|
||||
build_fn: callable function or class instance
|
||||
sk_params: model parameters & fitting parameters
|
||||
|
||||
@abc.abstractmethod
|
||||
def __init__(self, model, optimizer, loss,
|
||||
train_batch_size=128, test_batch_size=128,
|
||||
nb_epoch=100, shuffle=True, show_accuracy=False,
|
||||
validation_split=0, validation_data=None, callbacks=None,
|
||||
verbose=0,):
|
||||
self.model = model
|
||||
self.optimizer = optimizer
|
||||
self.loss = loss
|
||||
self.compiled_model_ = None
|
||||
self.classes_ = []
|
||||
self.config_ = []
|
||||
self.weights_ = []
|
||||
The build_fn should construct, compile and return a Keras model, which
|
||||
will then be used to fit/predict. One of the following
|
||||
three values could be passed to build_fn:
|
||||
1. A function
|
||||
2. An instance of a class that implements the __call__ method
|
||||
3. None. This means you implement a class that inherits from either
|
||||
`KerasClassifier` or `KerasRegressor`. The __call__ method of the
|
||||
present class will then be treated as the default build_fn.
|
||||
|
||||
self.train_batch_size = train_batch_size
|
||||
self.test_batch_size = test_batch_size
|
||||
self.nb_epoch = nb_epoch
|
||||
self.shuffle = shuffle
|
||||
self.show_accuracy = show_accuracy
|
||||
self.validation_split = validation_split
|
||||
self.validation_data = validation_data
|
||||
self.callbacks = [] if callbacks is None else callbacks
|
||||
`sk_params` takes both model parameters and fitting parameters. Legal model
|
||||
parameters are the arguments of `build_fn`. Note that like all other
|
||||
estimators in scikit-learn, 'build_fn' should provide defalult values for
|
||||
its arguments, so that you could create the estimator without passing any
|
||||
values to `sk_params`.
|
||||
|
||||
self.verbose = verbose
|
||||
`sk_params` could also accept parameters for calling `fit`, `predict`,
|
||||
`predict_proba`, and `score` methods (e.g., `nb_epoch`, `batch_size`).
|
||||
fitting (predicting) parameters are selected in the following order:
|
||||
|
||||
1. Values passed to the dictionary arguments of
|
||||
`fit`, `predict`, `predict_proba`, and `score` methods
|
||||
2. Values passed to `sk_params`
|
||||
3. The default values of the `keras.models.Sequential`
|
||||
`fit`, `predict`, `predict_proba` and `score` methods
|
||||
|
||||
When using scikit-learn's `grid_search` API, legal tunable parameters are
|
||||
those you could pass to `sk_params`, including fitting parameters.
|
||||
In other words, you could use `grid_search` to search for the best
|
||||
`batch_size` or `nb_epoch` as well as the model parameters.
|
||||
'''
|
||||
|
||||
def __init__(self, build_fn=None, **sk_params):
|
||||
self.build_fn = build_fn
|
||||
self.sk_params = sk_params
|
||||
self.check_params(sk_params)
|
||||
|
||||
def check_params(self, params):
|
||||
'''Check for user typos in "params" keys to avoid
|
||||
unwanted usage of default values
|
||||
|
||||
# Arguments
|
||||
params: dictionary
|
||||
The parameters to be checked
|
||||
'''
|
||||
legal_params_fns = [Sequential.fit, Sequential.predict,
|
||||
Sequential.predict_classes, Sequential.evaluate]
|
||||
if self.build_fn is None:
|
||||
legal_params_fns.append(self.__call__)
|
||||
elif not isinstance(self.build_fn, types.FunctionType):
|
||||
legal_params_fns.append(self.build_fn.__call__)
|
||||
else:
|
||||
legal_params_fns.append(self.build_fn)
|
||||
|
||||
legal_params = []
|
||||
for fn in legal_params_fns:
|
||||
legal_params += inspect.getargspec(fn)[0]
|
||||
legal_params = set(legal_params)
|
||||
|
||||
for params_name in params:
|
||||
if params_name not in legal_params:
|
||||
assert False, '{} is not a legal parameter'.format(params_name)
|
||||
|
||||
def get_params(self, deep=True):
|
||||
"""
|
||||
Get parameters for this estimator.
|
||||
'''Get parameters for this estimator.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
deep: boolean, optional
|
||||
If True, will return the parameters for this estimator and
|
||||
contained subobjects that are estimators.
|
||||
# Arguments
|
||||
deep: boolean, optional
|
||||
If True, will return the parameters for this estimator and
|
||||
contained sub-objects that are estimators.
|
||||
|
||||
Returns
|
||||
-------
|
||||
params : dict
|
||||
Dictionary of parameter names mapped to their values.
|
||||
"""
|
||||
return {'model': self.model, 'optimizer': self.optimizer, 'loss': self.loss}
|
||||
# Returns
|
||||
params : dict
|
||||
Dictionary of parameter names mapped to their values.
|
||||
'''
|
||||
res = copy.deepcopy(self.sk_params)
|
||||
res.update({'build_fn': self.build_fn})
|
||||
return res
|
||||
|
||||
def set_params(self, **params):
|
||||
"""
|
||||
Set the parameters of this estimator.
|
||||
'''Set the parameters of this estimator.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
# Arguments
|
||||
params: dict
|
||||
Dictionary of parameter names mapped to their values.
|
||||
|
||||
Returns
|
||||
-------
|
||||
self
|
||||
"""
|
||||
for parameter, value in params.items():
|
||||
setattr(self, parameter, value)
|
||||
# Returns
|
||||
self
|
||||
'''
|
||||
self.check_params(params)
|
||||
self.sk_params.update(params)
|
||||
return self
|
||||
|
||||
def fit(self, X, y):
|
||||
"""
|
||||
Fit the model according to the given training data.
|
||||
def fit(self, X, y, **kwargs):
|
||||
'''Construct a new model with build_fn and fit the model according
|
||||
to the given training data.
|
||||
|
||||
Makes a copy of the un-compiled model definition to use for
|
||||
compilation and fitting, leaving the original definition
|
||||
intact.
|
||||
# Arguments
|
||||
X : array-like, shape `(n_samples, n_features)`
|
||||
Training samples where n_samples in the number of samples
|
||||
and n_features is the number of features.
|
||||
y : array-like, shape `(n_samples,)` or `(n_samples, n_outputs)`
|
||||
True labels for X.
|
||||
kwargs: dictionary arguments
|
||||
Legal arguments are the arguments of `Sequential.fit`
|
||||
|
||||
Parameters
|
||||
----------
|
||||
X : array-like, shape = (n_samples, n_features)
|
||||
Training samples where n_samples in the number of samples
|
||||
and n_features is the number of features.
|
||||
y : array-like, shape = (n_samples) or (n_samples, n_outputs)
|
||||
True labels for X.
|
||||
# Returns
|
||||
history : object
|
||||
details about the training history at each epoch.
|
||||
'''
|
||||
|
||||
Returns
|
||||
-------
|
||||
history : object
|
||||
Returns details about the training history at each epoch.
|
||||
"""
|
||||
if len(y.shape) == 1:
|
||||
self.classes_ = list(np.unique(y))
|
||||
if self.loss == 'categorical_crossentropy':
|
||||
y = to_categorical(y)
|
||||
if self.build_fn is None:
|
||||
self.model = self.__call__(**self.filter_sk_params(self.__call__))
|
||||
elif not isinstance(self.build_fn, types.FunctionType):
|
||||
self.model = self.build_fn(
|
||||
**self.filter_sk_params(self.build_fn.__call__))
|
||||
else:
|
||||
self.classes_ = np.arange(0, y.shape[1])
|
||||
self.model = self.build_fn(**self.filter_sk_params(self.build_fn))
|
||||
|
||||
self.compiled_model_ = copy.deepcopy(self.model)
|
||||
self.compiled_model_.compile(optimizer=self.optimizer, loss=self.loss)
|
||||
history = self.compiled_model_.fit(
|
||||
X, y, batch_size=self.train_batch_size, nb_epoch=self.nb_epoch, verbose=self.verbose,
|
||||
shuffle=self.shuffle, show_accuracy=self.show_accuracy,
|
||||
validation_split=self.validation_split, validation_data=self.validation_data,
|
||||
callbacks=self.callbacks)
|
||||
if self.model.loss.__name__ == 'categorical_crossentropy' and len(y.shape) != 2:
|
||||
y = to_categorical(y)
|
||||
|
||||
self.config_ = self.model.get_config()
|
||||
self.weights_ = self.model.get_weights()
|
||||
fit_args = copy.deepcopy(self.filter_sk_params(Sequential.fit))
|
||||
fit_args.update(kwargs)
|
||||
|
||||
history = self.model.fit(X, y, **fit_args)
|
||||
|
||||
return history
|
||||
|
||||
def filter_sk_params(self, fn, override={}):
|
||||
'''Filter sk_params and return those in fn's arguments
|
||||
|
||||
# Arguments
|
||||
fn : arbitrary function
|
||||
override: dictionary, values to overrid sk_params
|
||||
|
||||
# Returns
|
||||
res : dictionary dictionary containing variabls
|
||||
in both sk_params and fn's arguments.
|
||||
'''
|
||||
res = {}
|
||||
fn_args = inspect.getargspec(fn)[0]
|
||||
for name, value in self.sk_params.items():
|
||||
if name in fn_args:
|
||||
res.update({name: value})
|
||||
res.update(override)
|
||||
return res
|
||||
|
||||
|
||||
class KerasClassifier(BaseWrapper):
|
||||
"""
|
||||
Implementation of the scikit-learn classifier API for Keras.
|
||||
'''Implementation of the scikit-learn classifier API for Keras.
|
||||
'''
|
||||
|
||||
Parameters
|
||||
----------
|
||||
model : object
|
||||
An un-compiled Keras model object is required to use the scikit-learn wrapper.
|
||||
optimizer : string
|
||||
Optimization method used by the model during compilation/training.
|
||||
loss : string
|
||||
Loss function used by the model during compilation/training.
|
||||
"""
|
||||
def __init__(self, model, optimizer='adam', loss='categorical_crossentropy', **kwargs):
|
||||
super(KerasClassifier, self).__init__(model, optimizer, loss, **kwargs)
|
||||
def predict(self, X, **kwargs):
|
||||
'''Returns the class predictions for the given test data.
|
||||
|
||||
def predict(self, X):
|
||||
"""
|
||||
Returns the class predictions for the given test data.
|
||||
# Arguments
|
||||
X: array-like, shape `(n_samples, n_features)`
|
||||
Test samples where n_samples in the number of samples
|
||||
and n_features is the number of features.
|
||||
kwargs: dictionary arguments
|
||||
Legal arguments are the arguments of `Sequential.predict_classes`.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
X : array-like, shape = (n_samples, n_features)
|
||||
Test samples where n_samples in the number of samples
|
||||
and n_features is the number of features.
|
||||
# Returns
|
||||
preds: array-like, shape `(n_samples,)`
|
||||
Class predictions.
|
||||
'''
|
||||
kwargs = self.filter_sk_params(Sequential.predict_classes, kwargs)
|
||||
return self.model.predict_classes(X, **kwargs)
|
||||
|
||||
Returns
|
||||
-------
|
||||
preds : array-like, shape = (n_samples)
|
||||
Class predictions.
|
||||
"""
|
||||
return self.compiled_model_.predict_classes(
|
||||
X, batch_size=self.test_batch_size, verbose=self.verbose)
|
||||
def predict_proba(self, X, **kwargs):
|
||||
'''Returns class probability estimates for the given test data.
|
||||
|
||||
def predict_proba(self, X):
|
||||
"""
|
||||
Returns class probability estimates for the given test data.
|
||||
# Arguments
|
||||
X: array-like, shape `(n_samples, n_features)`
|
||||
Test samples where n_samples in the number of samples
|
||||
and n_features is the number of features.
|
||||
kwargs: dictionary arguments
|
||||
Legal arguments are the arguments of `Sequential.predict_classes`.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
X : array-like, shape = (n_samples, n_features)
|
||||
Test samples where n_samples in the number of samples
|
||||
and n_features is the number of features.
|
||||
# Returns
|
||||
proba: array-like, shape `(n_samples, n_outputs)`
|
||||
Class probability estimates.
|
||||
'''
|
||||
kwargs = self.filter_sk_params(Sequential.predict_proba, kwargs)
|
||||
return self.model.predict_proba(X, **kwargs)
|
||||
|
||||
Returns
|
||||
-------
|
||||
proba : array-like, shape = (n_samples, n_outputs)
|
||||
Class probability estimates.
|
||||
"""
|
||||
return self.compiled_model_.predict_proba(
|
||||
X, batch_size=self.test_batch_size, verbose=self.verbose)
|
||||
def score(self, X, y, **kwargs):
|
||||
'''Returns the mean accuracy on the given test data and labels.
|
||||
|
||||
def score(self, X, y):
|
||||
"""
|
||||
Returns the mean accuracy on the given test data and labels.
|
||||
# Arguments
|
||||
X: array-like, shape `(n_samples, n_features)`
|
||||
Test samples where n_samples in the number of samples
|
||||
and n_features is the number of features.
|
||||
y: array-like, shape `(n_samples,)` or `(n_samples, n_outputs)`
|
||||
True labels for X.
|
||||
kwargs: dictionary arguments
|
||||
Legal arguments are the arguments of `Sequential.evaluate`.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
X : array-like, shape = (n_samples, n_features)
|
||||
Test samples where n_samples in the number of samples
|
||||
and n_features is the number of features.
|
||||
y : array-like, shape = (n_samples) or (n_samples, n_outputs)
|
||||
True labels for X.
|
||||
|
||||
Returns
|
||||
-------
|
||||
score : float
|
||||
Mean accuracy of predictions on X wrt. y.
|
||||
"""
|
||||
loss, accuracy = self.compiled_model_.evaluate(
|
||||
X, y, batch_size=self.test_batch_size, show_accuracy=True, verbose=self.verbose)
|
||||
# Returns
|
||||
score: float
|
||||
Mean accuracy of predictions on X wrt. y.
|
||||
'''
|
||||
kwargs = self.filter_sk_params(Sequential.evaluate, kwargs)
|
||||
kwargs.update({'show_accuracy': True})
|
||||
loss, accuracy = self.model.evaluate(X, y, **kwargs)
|
||||
return accuracy
|
||||
|
||||
|
||||
class KerasRegressor(BaseWrapper):
|
||||
"""
|
||||
Implementation of the scikit-learn regressor API for Keras.
|
||||
'''Implementation of the scikit-learn regressor API for Keras.
|
||||
'''
|
||||
|
||||
Parameters
|
||||
----------
|
||||
model : object
|
||||
An un-compiled Keras model object is required to use the scikit-learn wrapper.
|
||||
optimizer : string
|
||||
Optimization method used by the model during compilation/training.
|
||||
loss : string
|
||||
Loss function used by the model during compilation/training.
|
||||
"""
|
||||
def __init__(self, model, optimizer='adam', loss='mean_squared_error', **kwargs):
|
||||
super(KerasRegressor, self).__init__(model, optimizer, loss, **kwargs)
|
||||
def predict(self, X, **kwargs):
|
||||
'''Returns predictions for the given test data.
|
||||
|
||||
def predict(self, X):
|
||||
"""
|
||||
Returns predictions for the given test data.
|
||||
# Arguments
|
||||
X: array-like, shape `(n_samples, n_features)`
|
||||
Test samples where n_samples in the number of samples
|
||||
and n_features is the number of features.
|
||||
kwargs: dictionary arguments
|
||||
Legal arguments are the arguments of `Sequential.predict`.
|
||||
# Returns
|
||||
preds: array-like, shape `(n_samples,)`
|
||||
Predictions.
|
||||
'''
|
||||
kwargs = self.filter_sk_params(Sequential.predict, kwargs)
|
||||
return self.model.predict(X, **kwargs)
|
||||
|
||||
Parameters
|
||||
----------
|
||||
X : array-like, shape = (n_samples, n_features)
|
||||
Test samples where n_samples in the number of samples
|
||||
and n_features is the number of features.
|
||||
def score(self, X, y, **kwargs):
|
||||
'''Returns the mean accuracy on the given test data and labels.
|
||||
|
||||
Returns
|
||||
-------
|
||||
preds : array-like, shape = (n_samples)
|
||||
Predictions.
|
||||
"""
|
||||
return self.compiled_model_.predict(
|
||||
X, batch_size=self.test_batch_size, verbose=self.verbose).ravel()
|
||||
# Arguments
|
||||
X: array-like, shape `(n_samples, n_features)`
|
||||
Test samples where n_samples in the number of samples
|
||||
and n_features is the number of features.
|
||||
y: array-like, shape `(n_samples,)`
|
||||
True labels for X.
|
||||
kwargs: dictionary arguments
|
||||
Legal arguments are the arguments of `Sequential.evaluate`.
|
||||
|
||||
def score(self, X, y):
|
||||
"""
|
||||
Returns the mean accuracy on the given test data and labels.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
X : array-like, shape = (n_samples, n_features)
|
||||
Test samples where n_samples in the number of samples
|
||||
and n_features is the number of features.
|
||||
y : array-like, shape = (n_samples)
|
||||
True labels for X.
|
||||
|
||||
Returns
|
||||
-------
|
||||
score : float
|
||||
Loss from predictions on X wrt. y.
|
||||
"""
|
||||
loss = self.compiled_model_.evaluate(
|
||||
X, y, batch_size=self.test_batch_size, show_accuracy=False, verbose=self.verbose)
|
||||
# Returns
|
||||
score: float
|
||||
Mean accuracy of predictions on X wrt. y.
|
||||
'''
|
||||
kwargs = self.filter_sk_params(Sequential.evaluate, kwargs)
|
||||
kwargs.update({'show_accuracy': False})
|
||||
loss = self.model.evaluate(X, y, **kwargs)
|
||||
return loss
|
||||
|
||||
+3
-3
@@ -3,12 +3,12 @@ from setuptools import find_packages
|
||||
|
||||
|
||||
setup(name='Keras',
|
||||
version='0.3.1',
|
||||
description='Theano-based Deep Learning library',
|
||||
version='0.3.3',
|
||||
description='Deep Learning for Python',
|
||||
author='Francois Chollet',
|
||||
author_email='francois.chollet@gmail.com',
|
||||
url='https://github.com/fchollet/keras',
|
||||
download_url='https://github.com/fchollet/keras/tarball/0.3.1',
|
||||
download_url='https://github.com/fchollet/keras/tarball/0.3.3',
|
||||
license='MIT',
|
||||
install_requires=['theano', 'pyyaml', 'six'],
|
||||
extras_require={
|
||||
|
||||
@@ -35,7 +35,7 @@ def test_image_classification():
|
||||
Activation('relu'),
|
||||
Dense(y_test.shape[-1], activation='softmax')
|
||||
])
|
||||
model.compile(loss='categorical_crossentropy', optimizer='sgd')
|
||||
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
|
||||
history = model.fit(X_train, y_train, nb_epoch=10, batch_size=16,
|
||||
validation_data=(X_test, y_test),
|
||||
show_accuracy=True, verbose=0)
|
||||
|
||||
@@ -40,6 +40,8 @@ class TestBackend(object):
|
||||
|
||||
def test_linear_operations(self):
|
||||
check_two_tensor_operation('dot', (4, 2), (2, 4))
|
||||
check_two_tensor_operation('batch_dot', (4, 2, 3), (4, 5, 3),
|
||||
axes=((2,), (2,)))
|
||||
check_single_tensor_operation('transpose', (4, 2))
|
||||
|
||||
def test_shape_operations(self):
|
||||
@@ -145,6 +147,7 @@ class TestBackend(object):
|
||||
check_single_tensor_operation('exp', (4, 2))
|
||||
check_single_tensor_operation('log', (4, 2))
|
||||
check_single_tensor_operation('round', (4, 2))
|
||||
check_single_tensor_operation('sign', (4, 2))
|
||||
check_single_tensor_operation('pow', (4, 2), a=3)
|
||||
check_single_tensor_operation('clip', (4, 2), min_value=0.4,
|
||||
max_value=0.6)
|
||||
@@ -273,7 +276,7 @@ class TestBackend(object):
|
||||
check_single_tensor_operation('tanh', (4, 2))
|
||||
|
||||
# dropout
|
||||
val = np.random.random((20, 20))
|
||||
val = np.random.random((100, 100))
|
||||
xth = KTH.variable(val)
|
||||
xtf = KTF.variable(val)
|
||||
zth = KTH.eval(KTH.dropout(xth, level=0.2))
|
||||
@@ -355,6 +358,20 @@ class TestBackend(object):
|
||||
assert(np.max(rand) <= max)
|
||||
assert(np.min(rand) >= min)
|
||||
|
||||
def test_random_binomial(self):
|
||||
p = 0.5
|
||||
rand = KTF.eval(KTF.random_binomial((1000, 1000), p))
|
||||
assert(rand.shape == (1000, 1000))
|
||||
assert(np.abs(np.mean(rand) - p) < 0.01)
|
||||
assert(np.max(rand) == 1)
|
||||
assert(np.min(rand) == 0)
|
||||
|
||||
rand = KTH.eval(KTH.random_binomial((1000, 1000), p))
|
||||
assert(rand.shape == (1000, 1000))
|
||||
assert(np.abs(np.mean(rand) - p) < 0.01)
|
||||
assert(np.max(rand) == 1)
|
||||
assert(np.min(rand) == 0)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
pytest.main([__file__])
|
||||
|
||||
@@ -29,7 +29,7 @@ def test_leaky_relu():
|
||||
layer.input = K.variable(-inp)
|
||||
for train in [True, False]:
|
||||
outp = K.eval(layer.get_output(train))
|
||||
assert_allclose(outp, -inp*alpha)
|
||||
assert_allclose(outp, -inp * alpha)
|
||||
|
||||
config = layer.get_config()
|
||||
assert config['alpha'] == alpha
|
||||
@@ -53,7 +53,7 @@ def test_prelu():
|
||||
|
||||
layer.input = K.variable(-inp)
|
||||
outp = K.eval(layer.get_output(train))
|
||||
assert_allclose(-alphas*inp, outp)
|
||||
assert_allclose(-alphas * inp, outp)
|
||||
|
||||
# test with default weights
|
||||
layer = PReLU(input_shape=inp.flatten().shape)
|
||||
@@ -65,7 +65,7 @@ def test_prelu():
|
||||
layer.input = K.variable(-inp)
|
||||
outp = K.eval(layer.get_output(train))
|
||||
|
||||
assert_allclose(0., alphas*outp)
|
||||
assert_allclose(0., alphas * outp)
|
||||
|
||||
layer.get_config()
|
||||
|
||||
@@ -84,7 +84,7 @@ def test_elu():
|
||||
layer.input = K.variable(-inp)
|
||||
for train in [True, False]:
|
||||
outp = K.eval(layer.get_output(train))
|
||||
assert_allclose(outp, alpha*(np.exp(-inp)-1.), rtol=1e-3)
|
||||
assert_allclose(outp, alpha * (np.exp(-inp) - 1.), rtol=1e-3)
|
||||
|
||||
config = layer.get_config()
|
||||
assert config['alpha'] == alpha
|
||||
@@ -107,7 +107,7 @@ def test_parametric_softplus():
|
||||
layer.build()
|
||||
for train in [True, False]:
|
||||
outp = K.eval(layer.get_output(train))
|
||||
assert_allclose(outp, alpha*np.log(1.+np.exp(beta*inp)),
|
||||
assert_allclose(outp, alpha * np.log(1. + np.exp(beta * inp)),
|
||||
atol=1e-3)
|
||||
|
||||
config = layer.get_config()
|
||||
@@ -126,12 +126,12 @@ def test_thresholded_linear():
|
||||
layer.input = K.variable(inp)
|
||||
for train in [True, False]:
|
||||
outp = K.eval(layer.get_output(train))
|
||||
assert_allclose(outp, inp*(np.abs(inp) >= theta))
|
||||
assert_allclose(outp, inp * (np.abs(inp) >= theta))
|
||||
|
||||
layer.input = K.variable(-inp)
|
||||
for train in [True, False]:
|
||||
outp = K.eval(layer.get_output(train))
|
||||
assert_allclose(outp, -inp*(np.abs(inp) >= theta))
|
||||
assert_allclose(outp, -inp * (np.abs(inp) >= theta))
|
||||
|
||||
config = layer.get_config()
|
||||
assert config['theta'] == theta
|
||||
@@ -148,16 +148,34 @@ def test_thresholded_relu():
|
||||
layer.input = K.variable(inp)
|
||||
for train in [True, False]:
|
||||
outp = K.eval(layer.get_output(train))
|
||||
assert_allclose(outp, inp*(inp > theta))
|
||||
assert_allclose(outp, inp * (inp > theta))
|
||||
|
||||
layer.input = K.variable(-inp)
|
||||
for train in [True, False]:
|
||||
outp = K.eval(layer.get_output(train))
|
||||
assert_allclose(outp, -inp*(-inp > theta))
|
||||
assert_allclose(outp, -inp * (-inp > theta))
|
||||
|
||||
config = layer.get_config()
|
||||
assert config['theta'] == theta
|
||||
|
||||
|
||||
def test_srelu():
|
||||
from keras.layers.advanced_activations import SReLU
|
||||
np.random.seed(1337)
|
||||
inp = np.array([-2, -1., -0.5, 0., 0.5, 1., 2.])
|
||||
out = np.array([-1.5, -1., -0.5, 0., 0.5, 1., 3.])
|
||||
input_size = len(inp)
|
||||
for train in [True, False]:
|
||||
layer = SReLU(input_shape=inp.flatten().shape)
|
||||
ones_proto = np.ones(input_size)
|
||||
layer.set_weights([ones_proto * -1., ones_proto * 0.5,
|
||||
ones_proto * 2., ones_proto * 2.])
|
||||
layer.input = K.variable(inp)
|
||||
outp = K.eval(layer.get_output(train))
|
||||
assert_allclose(out, outp)
|
||||
|
||||
layer.get_config()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
pytest.main([__file__])
|
||||
|
||||
@@ -6,7 +6,7 @@ from numpy.testing import assert_allclose
|
||||
|
||||
from keras import backend as K
|
||||
from keras.layers.core import Dense
|
||||
from keras.models import Sequential
|
||||
from keras.models import Sequential, Graph
|
||||
|
||||
|
||||
def test_layer_call():
|
||||
@@ -56,5 +56,157 @@ def test_sequential_call():
|
||||
assert_allclose(y1, y2)
|
||||
|
||||
|
||||
def test_graph_call():
|
||||
"""Test keras.models.Graph.__call__"""
|
||||
nb_samples, input_dim, output_dim = 3, 10, 5
|
||||
model = Graph()
|
||||
model.add_input('input', input_shape=(input_dim, ))
|
||||
model.add_node(Dense(output_dim=output_dim, input_dim=input_dim),
|
||||
input='input', name='output', create_output=True)
|
||||
|
||||
model.compile('sgd', {'output': 'mse'})
|
||||
|
||||
# test flat model
|
||||
X = K.placeholder(ndim=2)
|
||||
Y = model(X)
|
||||
f = K.function([X], [Y])
|
||||
|
||||
x = np.ones((nb_samples, input_dim)).astype(K.floatx())
|
||||
y1 = f([x])[0].astype(K.floatx())
|
||||
y2 = model.predict({'input': x})['output']
|
||||
# results of __call__ should match model.predict
|
||||
assert_allclose(y1, y2)
|
||||
|
||||
# test nested Graph models
|
||||
model2 = Graph()
|
||||
model2.add_input('input', input_shape=(input_dim, ))
|
||||
model2.add_node(model, input='input', name='output', create_output=True)
|
||||
# need to turn off cache because we're reusing model
|
||||
model2.cache_enabled = False
|
||||
model2.compile('sgd', {'output': 'mse'})
|
||||
|
||||
Y2 = model2(X)
|
||||
f = K.function([X], [Y2])
|
||||
|
||||
y1 = f([x])[0].astype(K.floatx())
|
||||
y2 = model2.predict({'input': x})['output']
|
||||
# results of __call__ should match model.predict
|
||||
assert_allclose(y1, y2)
|
||||
|
||||
|
||||
def test_graph_multiple_in_out_call():
|
||||
"""Test keras.models.Graph.__call__ with multiple inputs"""
|
||||
nb_samples, input_dim, output_dim = 3, 10, 5
|
||||
model = Graph()
|
||||
model.add_input('input1', input_shape=(input_dim, ))
|
||||
model.add_input('input2', input_shape=(input_dim, ))
|
||||
model.add_node(Dense(output_dim=output_dim, input_dim=input_dim),
|
||||
inputs=['input1', 'input2'], merge_mode='sum', name='output', create_output=True)
|
||||
|
||||
model.compile('sgd', {'output': 'mse'})
|
||||
|
||||
# test flat model
|
||||
X1 = K.placeholder(ndim=2)
|
||||
X2 = K.placeholder(ndim=2)
|
||||
Y = model({'input1': X1, 'input2': X2})['output']
|
||||
f = K.function([X1, X2], [Y])
|
||||
|
||||
x1 = np.ones((nb_samples, input_dim)).astype(K.floatx())
|
||||
x2 = np.ones((nb_samples, input_dim)).astype(K.floatx()) * -2
|
||||
y1 = f([x1, x2])[0].astype(K.floatx())
|
||||
y2 = model.predict({'input1': x1, 'input2': x2})['output']
|
||||
# results of __call__ should match model.predict
|
||||
assert_allclose(y1, y2)
|
||||
|
||||
# test with single input, multiple outputs
|
||||
model2 = Graph()
|
||||
model2.add_input('input', input_shape=(input_dim, ))
|
||||
model2.add_node(Dense(output_dim=output_dim, input_dim=input_dim),
|
||||
input='input', name='output1', create_output=True)
|
||||
model2.add_node(Dense(output_dim=output_dim, input_dim=input_dim),
|
||||
input='input', name='output2', create_output=True)
|
||||
|
||||
model2.compile('sgd', {'output1': 'mse', 'output2': 'mse'})
|
||||
|
||||
# test flat model
|
||||
X = K.placeholder(ndim=2)
|
||||
Y = model2(X)
|
||||
f = K.function([X], [Y['output1'], Y['output2']])
|
||||
|
||||
x = np.ones((nb_samples, input_dim)).astype(K.floatx())
|
||||
out = f([x])
|
||||
y1a = out[0].astype(K.floatx())
|
||||
y1b = out[1].astype(K.floatx())
|
||||
y2 = model2.predict({'input': x})
|
||||
# results of __call__ should match model.predict
|
||||
assert_allclose(y1a, y2['output1'])
|
||||
assert_allclose(y1b, y2['output2'])
|
||||
|
||||
# test with multiple inputs, multiple outputs
|
||||
model3 = Graph()
|
||||
model3.add_input('input1', input_shape=(input_dim, ))
|
||||
model3.add_input('input2', input_shape=(input_dim, ))
|
||||
model3.add_shared_node(Dense(output_dim=output_dim, input_dim=input_dim),
|
||||
inputs=['input1', 'input2'], name='output',
|
||||
outputs=['output1', 'output2'], create_output=True)
|
||||
model3.compile('sgd', {'output1': 'mse', 'output2': 'mse'})
|
||||
|
||||
# test flat model
|
||||
Y = model3({'input1': X1, 'input2': X2})
|
||||
f = K.function([X1, X2], [Y['output1'], Y['output2']])
|
||||
|
||||
x1 = np.ones((nb_samples, input_dim)).astype(K.floatx())
|
||||
x2 = np.ones((nb_samples, input_dim)).astype(K.floatx()) * -2
|
||||
out = f([x1, x2])
|
||||
y1a = out[0].astype(K.floatx())
|
||||
y1b = out[1].astype(K.floatx())
|
||||
y2 = model3.predict({'input1': x1, 'input2': x2})
|
||||
# results of __call__ should match model.predict
|
||||
assert_allclose(y1a, y2['output1'])
|
||||
assert_allclose(y1b, y2['output2'])
|
||||
|
||||
|
||||
def test_nested_call():
|
||||
"""Test nested Sequential and Graph models"""
|
||||
nb_samples, input_dim, output_dim = 3, 10, 5
|
||||
X = K.placeholder(ndim=2)
|
||||
x = np.ones((nb_samples, input_dim)).astype(K.floatx())
|
||||
|
||||
# test Graph model nested inside Sequential model
|
||||
model = Graph()
|
||||
model.add_input('input', input_shape=(input_dim, ))
|
||||
model.add_node(Dense(output_dim=output_dim, input_dim=input_dim),
|
||||
input='input', name='output', create_output=True)
|
||||
|
||||
model2 = Sequential()
|
||||
model2.add(model)
|
||||
model2.compile('sgd', 'mse')
|
||||
|
||||
Y2 = model2(X)
|
||||
f = K.function([X], [Y2])
|
||||
|
||||
y1 = f([x])[0].astype(K.floatx())
|
||||
y2 = model2.predict(x)
|
||||
# results of __call__ should match model.predict
|
||||
assert_allclose(y1, y2)
|
||||
|
||||
# test Sequential model inside Graph model
|
||||
model3 = Sequential()
|
||||
model3.add(Dense(output_dim=output_dim, input_dim=input_dim))
|
||||
|
||||
model4 = Graph()
|
||||
model4.add_input('input', input_shape=(input_dim, ))
|
||||
model4.add_node(model3, input='input', name='output', create_output=True)
|
||||
model4.compile('sgd', {'output': 'mse'})
|
||||
|
||||
Y2 = model4(X)
|
||||
f = K.function([X], [Y2])
|
||||
|
||||
y1 = f([x])[0].astype(K.floatx())
|
||||
y2 = model4.predict({'input': x})['output']
|
||||
# results of __call__ should match model.predict
|
||||
assert_allclose(y1, y2)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
pytest.main([__file__])
|
||||
|
||||
@@ -113,6 +113,38 @@ def test_convolution_2d():
|
||||
layer.get_config()
|
||||
|
||||
|
||||
def test_convolution_2d_dim_ordering():
|
||||
nb_filter = 4
|
||||
nb_row = 3
|
||||
nb_col = 2
|
||||
stack_size = 3
|
||||
|
||||
np.random.seed(1337)
|
||||
weights = [np.random.random((nb_filter, stack_size, nb_row, nb_col)),
|
||||
np.random.random(nb_filter)]
|
||||
input = np.random.random((1, stack_size, 10, 10))
|
||||
|
||||
layer = convolutional.Convolution2D(
|
||||
nb_filter, nb_row, nb_col,
|
||||
weights=weights,
|
||||
input_shape=input.shape[1:],
|
||||
dim_ordering='th')
|
||||
layer.input = K.variable(input)
|
||||
out_th = K.eval(layer.get_output(False))
|
||||
|
||||
input = np.transpose(input, (0, 2, 3, 1))
|
||||
weights[0] = np.transpose(weights[0], (2, 3, 1, 0))
|
||||
layer = convolutional.Convolution2D(
|
||||
nb_filter, nb_row, nb_col,
|
||||
weights=weights,
|
||||
input_shape=input.shape[1:],
|
||||
dim_ordering='tf')
|
||||
layer.input = K.variable(input)
|
||||
out_tf = K.eval(layer.get_output(False))
|
||||
|
||||
assert_allclose(out_tf, np.transpose(out_th, (0, 2, 3, 1)), atol=1e-05)
|
||||
|
||||
|
||||
def test_maxpooling_2d():
|
||||
nb_samples = 9
|
||||
stack_size = 7
|
||||
@@ -131,16 +163,128 @@ def test_maxpooling_2d():
|
||||
layer.get_config()
|
||||
|
||||
|
||||
def test_maxpooling_2d_dim_ordering():
|
||||
stack_size = 3
|
||||
|
||||
input = np.random.random((1, stack_size, 10, 10))
|
||||
|
||||
layer = convolutional.MaxPooling2D(
|
||||
(2, 2),
|
||||
input_shape=input.shape[1:],
|
||||
dim_ordering='th')
|
||||
layer.input = K.variable(input)
|
||||
out_th = K.eval(layer.get_output(False))
|
||||
|
||||
input = np.transpose(input, (0, 2, 3, 1))
|
||||
layer = convolutional.MaxPooling2D(
|
||||
(2, 2),
|
||||
input_shape=input.shape[1:],
|
||||
dim_ordering='tf')
|
||||
layer.input = K.variable(input)
|
||||
out_tf = K.eval(layer.get_output(False))
|
||||
|
||||
assert_allclose(out_tf, np.transpose(out_th, (0, 2, 3, 1)), atol=1e-05)
|
||||
|
||||
|
||||
def test_averagepooling_2d():
|
||||
nb_samples = 9
|
||||
stack_size = 7
|
||||
input_nb_row = 11
|
||||
input_nb_col = 12
|
||||
pool_size = (3, 3)
|
||||
|
||||
input = np.ones((nb_samples, stack_size, input_nb_row, input_nb_col))
|
||||
for strides in [(1, 1), (2, 2)]:
|
||||
layer = convolutional.AveragePooling2D(strides=strides,
|
||||
for border_mode in ['valid', 'same']:
|
||||
for pool_size in [(2, 2), (3, 3), (4, 4), (5, 5)]:
|
||||
for strides in [(1, 1), (2, 2)]:
|
||||
layer = convolutional.AveragePooling2D(strides=strides,
|
||||
border_mode=border_mode,
|
||||
pool_size=pool_size)
|
||||
layer.input = K.variable(input)
|
||||
for train in [True, False]:
|
||||
out = K.eval(layer.get_output(train))
|
||||
if border_mode == 'same' and strides == (1, 1):
|
||||
assert input.shape == out.shape
|
||||
layer.get_config()
|
||||
|
||||
|
||||
@pytest.mark.skipif(K._BACKEND != 'theano', reason="Requires Theano backend")
|
||||
def test_convolution_3d():
|
||||
nb_samples = 8
|
||||
nb_filter = 9
|
||||
stack_size = 7
|
||||
len_conv_dim1 = 2
|
||||
len_conv_dim2 = 10
|
||||
len_conv_dim3 = 6
|
||||
|
||||
input_len_dim1 = 10
|
||||
input_len_dim2 = 11
|
||||
input_len_dim3 = 12
|
||||
|
||||
weights_in = [np.ones((nb_filter, stack_size, len_conv_dim1, len_conv_dim2, len_conv_dim3)),
|
||||
np.ones(nb_filter)]
|
||||
|
||||
input = np.ones((nb_samples, stack_size, input_len_dim1,
|
||||
input_len_dim2, input_len_dim3))
|
||||
for weight in [None, weights_in]:
|
||||
for border_mode in ['same', 'valid']:
|
||||
for subsample in [(1, 1, 1), (2, 2, 2)]:
|
||||
if border_mode == 'same' and subsample != (1, 1, 1):
|
||||
continue
|
||||
for W_regularizer in [None, 'l2']:
|
||||
for b_regularizer in [None, 'l2']:
|
||||
for act_regularizer in [None, 'l2']:
|
||||
layer = convolutional.Convolution3D(
|
||||
nb_filter, len_conv_dim1, len_conv_dim2, len_conv_dim3,
|
||||
weights=weight,
|
||||
border_mode=border_mode,
|
||||
W_regularizer=W_regularizer,
|
||||
b_regularizer=b_regularizer,
|
||||
activity_regularizer=act_regularizer,
|
||||
subsample=subsample,
|
||||
input_shape=(stack_size, None, None, None))
|
||||
|
||||
layer.input = K.variable(input)
|
||||
for train in [True, False]:
|
||||
out = K.eval(layer.get_output(train))
|
||||
if border_mode == 'same' and subsample == (1, 1, 1):
|
||||
assert out.shape[2:] == input.shape[2:]
|
||||
layer.get_config()
|
||||
|
||||
|
||||
@pytest.mark.skipif(K._BACKEND != 'theano', reason="Requires Theano backend")
|
||||
def test_maxpooling_3d():
|
||||
nb_samples = 9
|
||||
stack_size = 7
|
||||
input_len_dim1 = 10
|
||||
input_len_dim2 = 11
|
||||
input_len_dim3 = 12
|
||||
pool_size = (3, 3, 3)
|
||||
|
||||
input = np.ones((nb_samples, stack_size, input_len_dim1,
|
||||
input_len_dim2, input_len_dim3))
|
||||
for strides in [(1, 1, 1), (2, 2, 2)]:
|
||||
layer = convolutional.MaxPooling3D(strides=strides,
|
||||
border_mode='valid',
|
||||
pool_size=pool_size)
|
||||
layer.input = K.variable(input)
|
||||
for train in [True, False]:
|
||||
K.eval(layer.get_output(train))
|
||||
layer.get_config()
|
||||
|
||||
|
||||
@pytest.mark.skipif(K._BACKEND != 'theano', reason="Requires Theano backend")
|
||||
def test_averagepooling_3d():
|
||||
nb_samples = 9
|
||||
stack_size = 7
|
||||
input_len_dim1 = 10
|
||||
input_len_dim2 = 11
|
||||
input_len_dim3 = 12
|
||||
pool_size = (3, 3, 3)
|
||||
|
||||
input = np.ones((nb_samples, stack_size, input_len_dim1,
|
||||
input_len_dim2, input_len_dim3))
|
||||
for strides in [(1, 1, 1), (2, 2, 2)]:
|
||||
layer = convolutional.AveragePooling3D(strides=strides,
|
||||
border_mode='valid',
|
||||
pool_size=pool_size)
|
||||
layer.input = K.variable(input)
|
||||
@@ -167,6 +311,28 @@ def test_zero_padding_2d():
|
||||
layer.get_config()
|
||||
|
||||
|
||||
@pytest.mark.skipif(K._BACKEND != 'theano', reason="Requires Theano backend")
|
||||
def test_zero_padding_3d():
|
||||
nb_samples = 9
|
||||
stack_size = 7
|
||||
input_len_dim1 = 10
|
||||
input_len_dim2 = 11
|
||||
input_len_dim3 = 12
|
||||
|
||||
input = np.ones((nb_samples, stack_size, input_len_dim1,
|
||||
input_len_dim2, input_len_dim3))
|
||||
layer = convolutional.ZeroPadding3D(padding=(2, 2, 2))
|
||||
layer.input = K.variable(input)
|
||||
for train in [True, False]:
|
||||
out = K.eval(layer.get_output(train))
|
||||
for offset in [0, 1, -1, -2]:
|
||||
assert_allclose(out[:, :, offset, :, :], 0.)
|
||||
assert_allclose(out[:, :, :, offset, :], 0.)
|
||||
assert_allclose(out[:, :, :, :, offset], 0.)
|
||||
assert_allclose(out[:, :, 2:-2, 2:-2, 2:-2], 1.)
|
||||
layer.get_config()
|
||||
|
||||
|
||||
def test_upsampling_1d():
|
||||
nb_samples = 9
|
||||
nb_steps = 7
|
||||
@@ -198,29 +364,76 @@ def test_upsampling_2d():
|
||||
|
||||
for length_row in [2, 3, 9]:
|
||||
for length_col in [2, 3, 9]:
|
||||
layer = convolutional.UpSampling2D(
|
||||
size=(length_row, length_col),
|
||||
layer = convolutional.UpSampling2D(
|
||||
size=(length_row, length_col),
|
||||
input_shape=input.shape[1:],
|
||||
dim_ordering=dim_ordering)
|
||||
layer.input = K.variable(input)
|
||||
for train in [True, False]:
|
||||
out = K.eval(layer.get_output(train))
|
||||
if dim_ordering == 'th':
|
||||
assert out.shape[2] == length_row * input_nb_row
|
||||
assert out.shape[3] == length_col * input_nb_col
|
||||
else: # tf
|
||||
assert out.shape[1] == length_row * input_nb_row
|
||||
assert out.shape[2] == length_col * input_nb_col
|
||||
|
||||
# compare with numpy
|
||||
if dim_ordering == 'th':
|
||||
expected_out = np.repeat(input, length_row, axis=2)
|
||||
expected_out = np.repeat(expected_out, length_col, axis=3)
|
||||
else: # tf
|
||||
expected_out = np.repeat(input, length_row, axis=1)
|
||||
expected_out = np.repeat(expected_out, length_col, axis=2)
|
||||
|
||||
assert_allclose(out, expected_out)
|
||||
|
||||
layer.get_config()
|
||||
|
||||
|
||||
@pytest.mark.skipif(K._BACKEND != 'theano', reason="Requires Theano backend")
|
||||
def test_upsampling_3d():
|
||||
nb_samples = 9
|
||||
stack_size = 7
|
||||
input_len_dim1 = 10
|
||||
input_len_dim2 = 11
|
||||
input_len_dim3 = 12
|
||||
|
||||
for dim_ordering in ['th', 'tf']:
|
||||
if dim_ordering == 'th':
|
||||
input = np.random.rand(nb_samples, stack_size, input_len_dim1, input_len_dim2,
|
||||
input_len_dim3)
|
||||
else: # tf
|
||||
input = np.random.rand(nb_samples, input_len_dim1, input_len_dim2, input_len_dim3,
|
||||
stack_size)
|
||||
for length_dim1 in [2, 3, 9]:
|
||||
for length_dim2 in [2, 3, 9]:
|
||||
for length_dim3 in [2, 3, 9]:
|
||||
layer = convolutional.UpSampling3D(
|
||||
size=(length_dim1, length_dim2, length_dim3),
|
||||
input_shape=input.shape[1:],
|
||||
dim_ordering=dim_ordering)
|
||||
layer.input = K.variable(input)
|
||||
for train in [True, False]:
|
||||
out = K.eval(layer.get_output(train))
|
||||
if dim_ordering == 'th':
|
||||
assert out.shape[2] == length_row * input_nb_row
|
||||
assert out.shape[3] == length_col * input_nb_col
|
||||
assert out.shape[2] == length_dim1 * input_len_dim1
|
||||
assert out.shape[3] == length_dim2 * input_len_dim2
|
||||
assert out.shape[4] == length_dim3 * input_len_dim3
|
||||
else: # tf
|
||||
assert out.shape[1] == length_row * input_nb_row
|
||||
assert out.shape[2] == length_col * input_nb_col
|
||||
assert out.shape[1] == length_dim1 * input_len_dim1
|
||||
assert out.shape[2] == length_dim2 * input_len_dim2
|
||||
assert out.shape[3] == length_dim3 * input_len_dim3
|
||||
|
||||
# compare with numpy
|
||||
if dim_ordering == 'th':
|
||||
expected_out = np.repeat(input, length_row, axis=2)
|
||||
expected_out = np.repeat(expected_out, length_col,
|
||||
axis=3)
|
||||
expected_out = np.repeat(input, length_dim1, axis=2)
|
||||
expected_out = np.repeat(expected_out, length_dim2, axis=3)
|
||||
expected_out = np.repeat(expected_out, length_dim3, axis=4)
|
||||
else: # tf
|
||||
expected_out = np.repeat(input, length_row, axis=1)
|
||||
expected_out = np.repeat(expected_out, length_col,
|
||||
axis=2)
|
||||
expected_out = np.repeat(input, length_dim1, axis=1)
|
||||
expected_out = np.repeat(expected_out, length_dim2, axis=2)
|
||||
expected_out = np.repeat(expected_out, length_dim3, axis=3)
|
||||
|
||||
assert_allclose(out, expected_out)
|
||||
|
||||
|
||||
@@ -175,7 +175,7 @@ def test_naming():
|
||||
def test_sequences():
|
||||
'''Test masking sequences with zeroes as padding'''
|
||||
# integer inputs, one per timestep, like embeddings
|
||||
layer = core.Masking()
|
||||
layer = core.Masking(input_shape=(4, 1))
|
||||
func = K.function([layer.get_input(True)], [layer.get_output_mask()])
|
||||
input_data = np.array([[[1], [2], [3], [0]],
|
||||
[[0], [4], [5], [0]]], dtype=np.int32)
|
||||
@@ -190,7 +190,7 @@ def test_sequences():
|
||||
|
||||
def test_non_zero():
|
||||
'''Test masking with non-zero mask value'''
|
||||
layer = core.Masking(5)
|
||||
layer = core.Masking(5, input_shape=(4, 2))
|
||||
func = K.function([layer.input], [layer.get_output_mask()])
|
||||
input_data = np.array([[[1, 1], [2, 1], [3, 1], [5, 5]],
|
||||
[[1, 5], [5, 0], [0, 0], [0, 0]]],
|
||||
@@ -202,7 +202,7 @@ def test_non_zero():
|
||||
|
||||
def test_non_zero_output():
|
||||
'''Test output of masking layer with non-zero mask value'''
|
||||
layer = core.Masking(5)
|
||||
layer = core.Masking(5, input_shape=(4, 2))
|
||||
func = K.function([layer.input], [layer.get_output()])
|
||||
|
||||
input_data = np.array([[[1, 1], [2, 1], [3, 1], [5, 5]],
|
||||
@@ -228,6 +228,7 @@ def _runner(layer):
|
||||
layer.trainable = True
|
||||
layer.trainable = False
|
||||
|
||||
|
||||
def test_siamese_all():
|
||||
right_input_layer = core.Dense(7, input_dim=3)
|
||||
left_input_layer = core.Dense(7, input_dim=3)
|
||||
@@ -238,6 +239,7 @@ def test_siamese_all():
|
||||
siamese_layer.output_shape
|
||||
siamese_layer.get_output()
|
||||
|
||||
|
||||
@pytest.mark.skipif(K._BACKEND == 'tensorflow',
|
||||
reason='currently not working with TensorFlow')
|
||||
def test_siamese_theano_only():
|
||||
|
||||
@@ -5,6 +5,7 @@ from numpy.testing import assert_allclose
|
||||
from keras.layers import recurrent, embeddings
|
||||
from keras.models import Sequential
|
||||
from keras.layers.core import Masking
|
||||
from keras import regularizers
|
||||
|
||||
from keras import backend as K
|
||||
from keras.models import Sequential, model_from_json
|
||||
@@ -34,6 +35,24 @@ def _runner(layer_class):
|
||||
|
||||
mask = layer.get_output_mask(train)
|
||||
|
||||
# check dropout
|
||||
for ret_seq in [True, False]:
|
||||
layer = layer_class(output_dim, return_sequences=ret_seq, weights=None,
|
||||
batch_input_shape=(nb_samples, timesteps, embedding_dim),
|
||||
dropout_W=0.5, dropout_U=0.5)
|
||||
layer.input = K.variable(np.ones((nb_samples, timesteps, embedding_dim)))
|
||||
layer.get_config()
|
||||
|
||||
for train in [True, False]:
|
||||
out = K.eval(layer.get_output(train))
|
||||
# Make sure the output has the desired shape
|
||||
if ret_seq:
|
||||
assert(out.shape == (nb_samples, timesteps, output_dim))
|
||||
else:
|
||||
assert(out.shape == (nb_samples, output_dim))
|
||||
|
||||
mask = layer.get_output_mask(train)
|
||||
|
||||
# check statefulness
|
||||
model = Sequential()
|
||||
model.add(embeddings.Embedding(embedding_num, embedding_dim,
|
||||
@@ -90,6 +109,15 @@ def _runner(layer_class):
|
||||
|
||||
assert_allclose(out7, out6, atol=1e-5)
|
||||
|
||||
# check regularizers
|
||||
layer = layer_class(output_dim, return_sequences=ret_seq, weights=None,
|
||||
batch_input_shape=(nb_samples, timesteps, embedding_dim),
|
||||
W_regularizer=regularizers.WeightRegularizer(l1=0.01),
|
||||
U_regularizer=regularizers.WeightRegularizer(l1=0.01),
|
||||
b_regularizer='l2')
|
||||
layer.input = K.variable(np.ones((nb_samples, timesteps, embedding_dim)))
|
||||
out = K.eval(layer.get_output(train=True))
|
||||
|
||||
|
||||
def test_SimpleRNN():
|
||||
_runner(recurrent.SimpleRNN)
|
||||
|
||||
@@ -0,0 +1,64 @@
|
||||
import pytest
|
||||
import numpy as np
|
||||
from numpy.testing import assert_allclose
|
||||
|
||||
from keras.layers import wrappers
|
||||
from keras.layers import core, convolutional
|
||||
from keras.models import Sequential, model_from_json
|
||||
|
||||
|
||||
def test_TimeDistributed():
|
||||
# first, test with Dense layer
|
||||
model = Sequential()
|
||||
model.add(wrappers.TimeDistributed(core.Dense(2), input_shape=(3, 4)))
|
||||
model.add(core.Activation('relu'))
|
||||
model.compile(optimizer='rmsprop', loss='mse')
|
||||
model.fit(np.random.random((10, 3, 4)), np.random.random((10, 3, 2)), nb_epoch=1, batch_size=10)
|
||||
|
||||
# test config
|
||||
model.get_config()
|
||||
|
||||
# compare to TimeDistributedDense
|
||||
test_input = np.random.random((1, 3, 4))
|
||||
test_output = model.predict(test_input)
|
||||
weights = model.layers[0].get_weights()
|
||||
|
||||
reference = Sequential()
|
||||
reference.add(core.TimeDistributedDense(2, input_shape=(3, 4), weights=weights))
|
||||
reference.add(core.Activation('relu'))
|
||||
reference.compile(optimizer='rmsprop', loss='mse')
|
||||
|
||||
reference_output = reference.predict(test_input)
|
||||
assert_allclose(test_output, reference_output, atol=1e-05)
|
||||
|
||||
# test when specifying a batch_input_shape
|
||||
reference = Sequential()
|
||||
reference.add(core.TimeDistributedDense(2, batch_input_shape=(1, 3, 4), weights=weights))
|
||||
reference.add(core.Activation('relu'))
|
||||
reference.compile(optimizer='rmsprop', loss='mse')
|
||||
|
||||
reference_output = reference.predict(test_input)
|
||||
assert_allclose(test_output, reference_output, atol=1e-05)
|
||||
|
||||
# test with Convolution2D
|
||||
model = Sequential()
|
||||
model.add(wrappers.TimeDistributed(convolutional.Convolution2D(5, 2, 2, border_mode='same'), input_shape=(2, 3, 4, 4)))
|
||||
model.add(core.Activation('relu'))
|
||||
model.compile(optimizer='rmsprop', loss='mse')
|
||||
model.train_on_batch(np.random.random((1, 2, 3, 4, 4)), np.random.random((1, 2, 5, 4, 4)))
|
||||
|
||||
model = model_from_json(model.to_json())
|
||||
model.summary()
|
||||
|
||||
# test stacked layers
|
||||
model = Sequential()
|
||||
model.add(wrappers.TimeDistributed(core.Dense(2), input_shape=(3, 4)))
|
||||
model.add(wrappers.TimeDistributed(core.Dense(3)))
|
||||
model.add(core.Activation('relu'))
|
||||
model.compile(optimizer='rmsprop', loss='mse')
|
||||
|
||||
model.fit(np.random.random((10, 3, 4)), np.random.random((10, 3, 3)), nb_epoch=1, batch_size=10)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
pytest.main([__file__])
|
||||
@@ -1,59 +1,59 @@
|
||||
# import pytest
|
||||
# from keras.preprocessing.image import *
|
||||
# from PIL import Image
|
||||
# import numpy as np
|
||||
# import os
|
||||
# import shutil
|
||||
import pytest
|
||||
from keras.preprocessing.image import *
|
||||
from PIL import Image
|
||||
import numpy as np
|
||||
import os
|
||||
import shutil
|
||||
|
||||
|
||||
# def setup_function(func):
|
||||
# os.mkdir('test_images')
|
||||
# os.mkdir('test_images/rgb')
|
||||
# os.mkdir('test_images/gsc')
|
||||
def setup_function(func):
|
||||
os.mkdir('test_images')
|
||||
os.mkdir('test_images/rgb')
|
||||
os.mkdir('test_images/gsc')
|
||||
|
||||
# img_w = img_h = 20
|
||||
# for n in range(8):
|
||||
# bias = np.random.rand(img_w, img_h, 1) * 64
|
||||
# variance = np.random.rand(img_w, img_h, 1) * (255-64)
|
||||
# imarray = np.random.rand(img_w, img_h, 3) * variance + bias
|
||||
# im = Image.fromarray(imarray.astype('uint8')).convert('RGBA')
|
||||
# im.save('test_images/rgb/rgb_test_image_'+str(n)+'.png')
|
||||
img_w = img_h = 20
|
||||
for n in range(8):
|
||||
bias = np.random.rand(img_w, img_h, 1) * 64
|
||||
variance = np.random.rand(img_w, img_h, 1) * (255-64)
|
||||
imarray = np.random.rand(img_w, img_h, 3) * variance + bias
|
||||
im = Image.fromarray(imarray.astype('uint8')).convert('RGBA')
|
||||
im.save('test_images/rgb/rgb_test_image_'+str(n)+'.png')
|
||||
|
||||
# imarray = np.random.rand(img_w, img_h, 1) * variance + bias
|
||||
# im = Image.fromarray(imarray.astype('uint8').squeeze()).convert('L')
|
||||
# im.save('test_images/gsc/gsc_test_image_'+str(n)+'.png')
|
||||
imarray = np.random.rand(img_w, img_h, 1) * variance + bias
|
||||
im = Image.fromarray(imarray.astype('uint8').squeeze()).convert('L')
|
||||
im.save('test_images/gsc/gsc_test_image_'+str(n)+'.png')
|
||||
|
||||
|
||||
# def teardown_function(func):
|
||||
# shutil.rmtree('test_images')
|
||||
def teardown_function(func):
|
||||
shutil.rmtree('test_images')
|
||||
|
||||
|
||||
# def test_image_data_generator():
|
||||
# for color_mode in ['gsc', 'rgb']:
|
||||
# file_list = list_pictures('test_images/' + color_mode)
|
||||
# img_list = []
|
||||
# for f in file_list:
|
||||
# img_list.append(img_to_array(load_img(f))[None, ...])
|
||||
def test_image_data_generator():
|
||||
for color_mode in ['gsc', 'rgb']:
|
||||
file_list = list_pictures('test_images/' + color_mode)
|
||||
img_list = []
|
||||
for f in file_list:
|
||||
img_list.append(img_to_array(load_img(f))[None, ...])
|
||||
|
||||
# images = np.vstack(img_list)
|
||||
# generator = ImageDataGenerator(
|
||||
# featurewise_center=True,
|
||||
# samplewise_center=True,
|
||||
# featurewise_std_normalization=True,
|
||||
# samplewise_std_normalization=True,
|
||||
# zca_whitening=True,
|
||||
# rotation_range=90.,
|
||||
# width_shift_range=10.,
|
||||
# height_shift_range=10.,
|
||||
# shear_range=0.5,
|
||||
# horizontal_flip=True,
|
||||
# vertical_flip=True)
|
||||
# generator.fit(images, augment=True)
|
||||
images = np.vstack(img_list)
|
||||
generator = ImageDataGenerator(
|
||||
featurewise_center=True,
|
||||
samplewise_center=True,
|
||||
featurewise_std_normalization=True,
|
||||
samplewise_std_normalization=True,
|
||||
zca_whitening=True,
|
||||
rotation_range=90.,
|
||||
width_shift_range=10.,
|
||||
height_shift_range=10.,
|
||||
shear_range=0.5,
|
||||
horizontal_flip=True,
|
||||
vertical_flip=True)
|
||||
generator.fit(images, augment=True)
|
||||
|
||||
# for x, y in generator.flow(images, np.arange(images.shape[0]),
|
||||
# shuffle=True, save_to_dir='test_images'):
|
||||
# assert x.shape[1:] == images.shape[1:]
|
||||
# break
|
||||
for x, y in generator.flow(images, np.arange(images.shape[0]),
|
||||
shuffle=True, save_to_dir='test_images'):
|
||||
assert x.shape[1:] == images.shape[1:]
|
||||
break
|
||||
|
||||
# if __name__ == '__main__':
|
||||
# pytest.main([__file__])
|
||||
if __name__ == '__main__':
|
||||
pytest.main([__file__])
|
||||
|
||||
@@ -28,6 +28,39 @@ def test_pad_sequences():
|
||||
assert_allclose(b, [[1, 1, 1], [1, 1, 2], [1, 2, 3]])
|
||||
|
||||
|
||||
def test_pad_sequences_vector():
|
||||
a = [[[1, 1]],
|
||||
[[2, 1], [2, 2]],
|
||||
[[3, 1], [3, 2], [3, 3]]]
|
||||
|
||||
# test padding
|
||||
b = pad_sequences(a, maxlen=3, padding='pre')
|
||||
assert_allclose(b, [[[0, 0], [0, 0], [1, 1]],
|
||||
[[0, 0], [2, 1], [2, 2]],
|
||||
[[3, 1], [3, 2], [3, 3]]])
|
||||
b = pad_sequences(a, maxlen=3, padding='post')
|
||||
assert_allclose(b, [[[1, 1], [0, 0], [0, 0]],
|
||||
[[2, 1], [2, 2], [0, 0]],
|
||||
[[3, 1], [3, 2], [3, 3]]])
|
||||
|
||||
# test truncating
|
||||
b = pad_sequences(a, maxlen=2, truncating='pre')
|
||||
assert_allclose(b, [[[0, 0], [1, 1]],
|
||||
[[2, 1], [2, 2]],
|
||||
[[3, 2], [3, 3]]])
|
||||
|
||||
b = pad_sequences(a, maxlen=2, truncating='post')
|
||||
assert_allclose(b, [[[0, 0], [1, 1]],
|
||||
[[2, 1], [2, 2]],
|
||||
[[3, 1], [3, 2]]])
|
||||
|
||||
# test value
|
||||
b = pad_sequences(a, maxlen=3, value=1)
|
||||
assert_allclose(b, [[[1, 1], [1, 1], [1, 1]],
|
||||
[[1, 1], [2, 1], [2, 2]],
|
||||
[[3, 1], [3, 2], [3, 3]]])
|
||||
|
||||
|
||||
def test_make_sampling_table():
|
||||
a = make_sampling_table(3)
|
||||
assert_allclose(a, np.asarray([0.00315225, 0.00315225, 0.00547597]),
|
||||
|
||||
@@ -127,7 +127,7 @@ def test_TensorBoard():
|
||||
import shutil
|
||||
import tensorflow as tf
|
||||
import keras.backend.tensorflow_backend as KTF
|
||||
old_session = KTF._get_session()
|
||||
old_session = KTF.get_session()
|
||||
filepath = './logs'
|
||||
(X_train, y_train), (X_test, y_test) = get_test_data(nb_train=train_samples,
|
||||
nb_test=test_samples,
|
||||
@@ -162,7 +162,7 @@ def test_TensorBoard():
|
||||
|
||||
with tf.Graph().as_default():
|
||||
session = tf.Session('')
|
||||
KTF._set_session(session)
|
||||
KTF.set_session(session)
|
||||
model = Sequential()
|
||||
model.add(Dense(nb_hidden, input_dim=input_dim, activation='relu'))
|
||||
model.add(Dense(nb_class, activation='softmax'))
|
||||
@@ -208,7 +208,7 @@ def test_TensorBoard():
|
||||
|
||||
with tf.Graph().as_default():
|
||||
session = tf.Session('')
|
||||
KTF._set_session(session)
|
||||
KTF.set_session(session)
|
||||
model = Graph()
|
||||
model.add_input(name='X_vars', input_shape=(input_dim, ))
|
||||
|
||||
@@ -246,7 +246,7 @@ def test_TensorBoard():
|
||||
assert os.path.exists(filepath)
|
||||
shutil.rmtree(filepath)
|
||||
|
||||
KTF._set_session(old_session)
|
||||
KTF.set_session(old_session)
|
||||
|
||||
if __name__ == '__main__':
|
||||
pytest.main([__file__])
|
||||
|
||||
@@ -0,0 +1,425 @@
|
||||
from __future__ import absolute_import
|
||||
from __future__ import print_function
|
||||
import pytest
|
||||
import os
|
||||
import numpy as np
|
||||
np.random.seed(1337)
|
||||
|
||||
from keras import backend as K
|
||||
from keras.models import Graph, Sequential, model_from_json, model_from_yaml
|
||||
from keras.layers.core import Dense, Activation, Merge, Lambda, LambdaMerge, Siamese, add_shared_layer
|
||||
from keras.layers import containers
|
||||
from keras.utils.test_utils import get_test_data
|
||||
|
||||
|
||||
batch_size = 32
|
||||
|
||||
(X_train_graph, y_train_graph), (X_test_graph, y_test_graph) = get_test_data(nb_train=1000,
|
||||
nb_test=200,
|
||||
input_shape=(32,),
|
||||
classification=False,
|
||||
output_shape=(4,))
|
||||
(X2_train_graph, y2_train_graph), (X2_test_graph, y2_test_graph) = get_test_data(nb_train=1000,
|
||||
nb_test=200,
|
||||
input_shape=(32,),
|
||||
classification=False,
|
||||
output_shape=(1,))
|
||||
|
||||
|
||||
def test_graph_fit_generator():
|
||||
def data_generator_graph(train):
|
||||
while 1:
|
||||
if train:
|
||||
yield {'input1': X_train_graph, 'output1': y_train_graph}
|
||||
else:
|
||||
yield {'input1': X_test_graph, 'output1': y_test_graph}
|
||||
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(4), name='dense3', input='dense1')
|
||||
|
||||
graph.add_output(name='output1',
|
||||
inputs=['dense2', 'dense3'],
|
||||
merge_mode='sum')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit_generator(data_generator_graph(True), 1000, nb_epoch=4)
|
||||
graph.fit_generator(data_generator_graph(True), 1000, nb_epoch=4,
|
||||
validation_data={'input1': X_test_graph, 'output1': y_test_graph})
|
||||
graph.fit_generator(data_generator_graph(True), 1000, nb_epoch=4,
|
||||
validation_data=data_generator_graph(False), nb_val_samples=batch_size * 3)
|
||||
graph.fit_generator(data_generator_graph(True), 1000, nb_epoch=4,
|
||||
validation_data=data_generator_graph(False), nb_val_samples=batch_size * 3)
|
||||
gen_loss = graph.evaluate_generator(data_generator_graph(True), 128, verbose=0)
|
||||
assert(gen_loss < 3.)
|
||||
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph}, verbose=0)
|
||||
assert(loss < 3.)
|
||||
|
||||
# test show_accuracy
|
||||
graph.fit_generator(data_generator_graph(True), 1000, nb_epoch=4, show_accuracy=True)
|
||||
graph.fit_generator(data_generator_graph(True), 1000, nb_epoch=4,
|
||||
validation_data={'input1': X_test_graph, 'output1': y_test_graph}, show_accuracy=True)
|
||||
graph.fit_generator(data_generator_graph(True), 1000, nb_epoch=4,
|
||||
validation_data=data_generator_graph(False), nb_val_samples=batch_size * 3, show_accuracy=True)
|
||||
graph.fit_generator(data_generator_graph(True), 1000, nb_epoch=4,
|
||||
validation_data=data_generator_graph(False), nb_val_samples=batch_size * 3, show_accuracy=True)
|
||||
gen_loss = graph.evaluate_generator(data_generator_graph(True), 128, verbose=0, show_accuracy=True)
|
||||
|
||||
|
||||
def test_1o_1i():
|
||||
# test a non-sequential graph with 1 input and 1 output
|
||||
np.random.seed(1337)
|
||||
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(4), name='dense3', input='dense1')
|
||||
|
||||
graph.add_output(name='output1',
|
||||
inputs=['dense2', 'dense3'],
|
||||
merge_mode='sum')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph}, verbose=0)
|
||||
assert(loss < 2.5)
|
||||
|
||||
# test show_accuracy:
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=1, show_accuracy=True)
|
||||
loss, acc = graph.test_on_batch({'input1': X_test_graph, 'output1': y_test_graph}, accuracy=True)
|
||||
loss, acc = graph.train_on_batch({'input1': X_test_graph, 'output1': y_test_graph}, accuracy=True)
|
||||
loss, acc = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph}, verbose=0, show_accuracy=True)
|
||||
|
||||
# test validation split
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph},
|
||||
validation_split=0.2, nb_epoch=1)
|
||||
# test validation data
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph},
|
||||
validation_data={'input1': X_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=1)
|
||||
|
||||
|
||||
def test_1o_1i_2():
|
||||
# test a more complex non-sequential graph with 1 input and 1 output
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2-0', input='input1')
|
||||
graph.add_node(Activation('relu'), name='dense2', input='dense2-0')
|
||||
|
||||
graph.add_node(Dense(16), name='dense3', input='dense2')
|
||||
graph.add_node(Dense(4), name='dense4', inputs=['dense1', 'dense3'],
|
||||
merge_mode='sum')
|
||||
|
||||
graph.add_output(name='output1', inputs=['dense2', 'dense4'],
|
||||
merge_mode='sum')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_train_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
assert(loss < 2.5)
|
||||
|
||||
graph.get_config(verbose=1)
|
||||
graph.summary()
|
||||
|
||||
|
||||
def test_1o_2i():
|
||||
# test a non-sequential graph with 2 inputs and 1 output
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_input(name='input2', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input2')
|
||||
graph.add_node(Dense(4), name='dense3', input='dense1')
|
||||
|
||||
graph.add_output(name='output1', inputs=['dense2', 'dense3'],
|
||||
merge_mode='sum')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'input2': X2_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph, 'input2': X2_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
assert(loss < 3.0)
|
||||
|
||||
graph.get_config(verbose=1)
|
||||
|
||||
|
||||
def test_siamese_3():
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_input(name='input2', input_shape=(32,))
|
||||
|
||||
graph.add_shared_node(Dense(16), name='shared', inputs=['input1', 'input2'], merge_mode='sum')
|
||||
graph.add_node(Dense(4), name='dense1', input='shared')
|
||||
graph.add_node(Dense(4), name='dense2', input='dense1')
|
||||
|
||||
graph.add_output(name='output1', input='dense2')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'input2': X2_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph, 'input2': X2_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
assert(loss < 3.0)
|
||||
|
||||
graph.get_config(verbose=1)
|
||||
|
||||
|
||||
def test_siamese_4():
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_input(name='input2', input_shape=(32,))
|
||||
|
||||
graph.add_shared_node(Dense(16), name='shared1', inputs=['input1', 'input2'])
|
||||
graph.add_shared_node(Dense(4), name='shared2', inputs=['shared1'])
|
||||
graph.add_shared_node(Dense(4), name='shared3', inputs=['shared2'], merge_mode='sum')
|
||||
graph.add_node(Dense(4), name='dense', input='shared3')
|
||||
|
||||
graph.add_output(name='output1', input='dense',
|
||||
merge_mode='sum')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'input2': X2_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph, 'input2': X2_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
assert(loss < 3.0)
|
||||
|
||||
graph.get_config(verbose=1)
|
||||
|
||||
|
||||
def test_siamese_5():
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_input(name='input2', input_shape=(32,))
|
||||
|
||||
graph.add_shared_node(Dense(16), name='shared1', inputs=['input1', 'input2'])
|
||||
graph.add_shared_node(Dense(4), name='shared2', inputs=['shared1'])
|
||||
graph.add_shared_node(Dense(4), name='shared3', inputs=['shared2'], outputs=['shared_output1','shared_output2'])
|
||||
graph.add_node(Dense(4), name='dense1', input='shared_output1')
|
||||
graph.add_node(Dense(4), name='dense2', input='shared_output2')
|
||||
|
||||
graph.add_output(name='output1', inputs=['dense1', 'dense2'],
|
||||
merge_mode='sum')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'input2': X2_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph, 'input2': X2_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
assert(loss < 3.0)
|
||||
|
||||
graph.get_config(verbose=1)
|
||||
|
||||
|
||||
def test_2o_1i_weights():
|
||||
# test a non-sequential graph with 1 input and 2 outputs
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(1), name='dense3', input='dense1')
|
||||
|
||||
graph.add_output(name='output1', input='dense2')
|
||||
graph.add_output(name='output2', input='dense3')
|
||||
graph.compile('rmsprop', {'output1': 'mse', 'output2': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph, 'output2': y2_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 2)
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'output1': y_test_graph, 'output2': y2_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'output1': y_test_graph, 'output2': y2_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph, 'output2': y2_test_graph})
|
||||
assert(loss < 4.)
|
||||
|
||||
# test weight saving
|
||||
fname = 'test_2o_1i_weights_temp.h5'
|
||||
graph.save_weights(fname, overwrite=True)
|
||||
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(1), name='dense3', input='dense1')
|
||||
graph.add_output(name='output1', input='dense2')
|
||||
graph.add_output(name='output2', input='dense3')
|
||||
graph.compile('rmsprop', {'output1': 'mse', 'output2': 'mse'})
|
||||
graph.load_weights('test_2o_1i_weights_temp.h5')
|
||||
os.remove(fname)
|
||||
|
||||
nloss = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph, 'output2': y2_test_graph})
|
||||
assert(loss == nloss)
|
||||
|
||||
# test loss weights
|
||||
graph.compile('rmsprop', {'output1': 'mse', 'output2': 'mse'},
|
||||
loss_weights={'output1': 1., 'output2': 2.})
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph, 'output2': y2_train_graph},
|
||||
nb_epoch=1)
|
||||
|
||||
|
||||
def test_2o_1i_sample_weights():
|
||||
# test a non-sequential graph with 1 input and 2 outputs with sample weights
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(1), name='dense3', input='dense1')
|
||||
|
||||
graph.add_output(name='output1', input='dense2')
|
||||
graph.add_output(name='output2', input='dense3')
|
||||
|
||||
weights1 = np.random.uniform(size=y_train_graph.shape[0])
|
||||
weights2 = np.random.uniform(size=y2_train_graph.shape[0])
|
||||
weights1_test = np.random.uniform(size=y_test_graph.shape[0])
|
||||
weights2_test = np.random.uniform(size=y2_test_graph.shape[0])
|
||||
|
||||
graph.compile('rmsprop', {'output1': 'mse', 'output2': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph, 'output2': y2_train_graph},
|
||||
nb_epoch=10,
|
||||
sample_weight={'output1': weights1, 'output2': weights2})
|
||||
out = graph.predict({'input1': X_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 2)
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'output1': y_test_graph, 'output2': y2_test_graph},
|
||||
sample_weight={'output1': weights1_test, 'output2': weights2_test})
|
||||
loss = graph.train_on_batch({'input1': X_train_graph, 'output1': y_train_graph, 'output2': y2_train_graph},
|
||||
sample_weight={'output1': weights1, 'output2': weights2})
|
||||
loss = graph.evaluate({'input1': X_train_graph, 'output1': y_train_graph, 'output2': y2_train_graph},
|
||||
sample_weight={'output1': weights1, 'output2': weights2})
|
||||
|
||||
|
||||
def test_recursive():
|
||||
# test layer-like API
|
||||
|
||||
graph = containers.Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(4), name='dense3', input='dense1')
|
||||
graph.add_output(name='output1', inputs=['dense2', 'dense3'],
|
||||
merge_mode='sum')
|
||||
|
||||
seq = Sequential()
|
||||
seq.add(Dense(32, input_shape=(32,)))
|
||||
seq.add(graph)
|
||||
seq.add(Dense(4))
|
||||
|
||||
seq.compile('rmsprop', 'mse')
|
||||
|
||||
seq.fit(X_train_graph, y_train_graph, batch_size=10, nb_epoch=10)
|
||||
loss = seq.evaluate(X_test_graph, y_test_graph)
|
||||
assert(loss < 2.5)
|
||||
|
||||
loss = seq.evaluate(X_test_graph, y_test_graph, show_accuracy=True)
|
||||
seq.predict(X_test_graph)
|
||||
seq.get_config(verbose=1)
|
||||
|
||||
|
||||
def test_create_output():
|
||||
# test create_output argument
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(4), name='dense3', input='dense1')
|
||||
graph.add_node(Dense(4), name='output1', inputs=['dense2', 'dense3'],
|
||||
merge_mode='sum', create_output=True)
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
history = graph.fit({'input1': X_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
assert(loss < 2.5)
|
||||
|
||||
# test serialization
|
||||
config = graph.to_json()
|
||||
del graph
|
||||
graph = model_from_json(config)
|
||||
|
||||
|
||||
def test_count_params():
|
||||
# test count params
|
||||
|
||||
nb_units = 100
|
||||
nb_classes = 2
|
||||
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_input(name='input2', input_shape=(32,))
|
||||
graph.add_node(Dense(nb_units),
|
||||
name='dense1', input='input1')
|
||||
graph.add_node(Dense(nb_classes),
|
||||
name='dense2', input='input2')
|
||||
graph.add_node(Dense(nb_classes),
|
||||
name='dense3', input='dense1')
|
||||
graph.add_output(name='output', inputs=['dense2', 'dense3'],
|
||||
merge_mode='sum')
|
||||
|
||||
n = 32 * nb_units + nb_units
|
||||
n += 32 * nb_classes + nb_classes
|
||||
n += nb_units * nb_classes + nb_classes
|
||||
|
||||
assert(n == graph.count_params())
|
||||
|
||||
graph.compile('rmsprop', {'output': 'binary_crossentropy'})
|
||||
|
||||
assert(n == graph.count_params())
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
pytest.main([__file__])
|
||||
@@ -1,3 +1,4 @@
|
||||
import pytest
|
||||
import numpy as np
|
||||
|
||||
from keras import objectives
|
||||
@@ -29,3 +30,7 @@ def test_objective_shapes_2d():
|
||||
for obj in allobj:
|
||||
objective_output = obj(y_a, y_b)
|
||||
assert K.eval(objective_output).shape == (6,)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
pytest.main([__file__])
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
from __future__ import absolute_import
|
||||
from __future__ import print_function
|
||||
import pytest
|
||||
import os
|
||||
import numpy as np
|
||||
np.random.seed(1337)
|
||||
|
||||
@@ -11,8 +12,6 @@ from keras.layers import containers
|
||||
from keras.utils import np_utils
|
||||
from keras.utils.test_utils import get_test_data
|
||||
|
||||
import os
|
||||
|
||||
|
||||
input_dim = 32
|
||||
nb_hidden = 16
|
||||
@@ -37,10 +36,6 @@ def _get_test_data():
|
||||
return (X_train, y_train), (X_test, y_test)
|
||||
|
||||
|
||||
####################
|
||||
# SEQUENTIAL TEST #
|
||||
####################
|
||||
|
||||
def test_sequential_fit_generator():
|
||||
(X_train, y_train), (X_test, y_test) = _get_test_data()
|
||||
|
||||
@@ -69,6 +64,10 @@ def test_sequential_fit_generator():
|
||||
model.fit_generator(data_generator(True), len(X_train), nb_epoch, show_accuracy=True)
|
||||
model.fit_generator(data_generator(True), len(X_train), nb_epoch, show_accuracy=False, validation_data=(X_test, y_test))
|
||||
model.fit_generator(data_generator(True), len(X_train), nb_epoch, show_accuracy=True, validation_data=(X_test, y_test))
|
||||
model.fit_generator(data_generator(True), len(X_train), nb_epoch, show_accuracy=False,
|
||||
validation_data=data_generator(False), nb_val_samples=batch_size * 3)
|
||||
model.fit_generator(data_generator(True), len(X_train), nb_epoch, show_accuracy=True,
|
||||
validation_data=data_generator(False), nb_val_samples=batch_size * 3)
|
||||
|
||||
loss = model.evaluate(X_train, y_train, verbose=0)
|
||||
assert(loss < 0.9)
|
||||
@@ -77,6 +76,21 @@ def test_sequential_fit_generator():
|
||||
def test_sequential():
|
||||
(X_train, y_train), (X_test, y_test) = _get_test_data()
|
||||
|
||||
# TODO: factor out
|
||||
def data_generator(train):
|
||||
if train:
|
||||
max_batch_index = len(X_train) // batch_size
|
||||
else:
|
||||
max_batch_index = len(X_test) // batch_size
|
||||
i = 0
|
||||
while 1:
|
||||
if train:
|
||||
yield (X_train[i * batch_size: (i + 1) * batch_size], y_train[i * batch_size: (i + 1) * batch_size])
|
||||
else:
|
||||
yield (X_test[i * batch_size: (i + 1) * batch_size], y_test[i * batch_size: (i + 1) * batch_size])
|
||||
i += 1
|
||||
i = i % max_batch_index
|
||||
|
||||
model = Sequential()
|
||||
model.add(Dense(nb_hidden, input_shape=(input_dim,)))
|
||||
model.add(Activation('relu'))
|
||||
@@ -94,6 +108,66 @@ def test_sequential():
|
||||
|
||||
model.train_on_batch(X_train[:32], y_train[:32])
|
||||
|
||||
gen_loss = model.evaluate_generator(data_generator(True), 256, verbose=0)
|
||||
assert(gen_loss < 0.8)
|
||||
|
||||
loss = model.evaluate(X_test, y_test, verbose=0)
|
||||
assert(loss < 0.8)
|
||||
|
||||
model.predict(X_test, verbose=0)
|
||||
model.predict_classes(X_test, verbose=0)
|
||||
model.predict_proba(X_test, verbose=0)
|
||||
model.get_config(verbose=0)
|
||||
|
||||
fname = 'test_sequential_temp.h5'
|
||||
model.save_weights(fname, overwrite=True)
|
||||
model = Sequential()
|
||||
model.add(Dense(nb_hidden, input_shape=(input_dim,)))
|
||||
model.add(Activation('relu'))
|
||||
model.add(Dense(nb_class))
|
||||
model.add(Activation('softmax'))
|
||||
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
|
||||
model.load_weights(fname)
|
||||
os.remove(fname)
|
||||
|
||||
nloss = model.evaluate(X_test, y_test, verbose=0)
|
||||
assert(loss == nloss)
|
||||
|
||||
# test json serialization
|
||||
json_data = model.to_json()
|
||||
model = model_from_json(json_data)
|
||||
|
||||
# test yaml serialization
|
||||
yaml_data = model.to_yaml()
|
||||
model = model_from_yaml(yaml_data)
|
||||
|
||||
|
||||
def test_nested_sequential():
|
||||
(X_train, y_train), (X_test, y_test) = _get_test_data()
|
||||
|
||||
inner = Sequential()
|
||||
inner.add(Dense(nb_hidden, input_shape=(input_dim,)))
|
||||
inner.add(Activation('relu'))
|
||||
inner.add(Dense(nb_class))
|
||||
|
||||
middle = Sequential()
|
||||
middle.add(inner)
|
||||
|
||||
model = Sequential()
|
||||
model.add(middle)
|
||||
model.add(Activation('softmax'))
|
||||
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
|
||||
model.summary()
|
||||
|
||||
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=nb_epoch, show_accuracy=True, verbose=1, validation_data=(X_test, y_test))
|
||||
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=nb_epoch, show_accuracy=False, verbose=2, validation_data=(X_test, y_test))
|
||||
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=nb_epoch, show_accuracy=True, verbose=2, validation_split=0.1)
|
||||
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=nb_epoch, show_accuracy=False, verbose=1, validation_split=0.1)
|
||||
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=nb_epoch, verbose=0)
|
||||
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=nb_epoch, verbose=1, shuffle=False)
|
||||
|
||||
model.train_on_batch(X_train[:32], y_train[:32])
|
||||
|
||||
loss = model.evaluate(X_test, y_test, verbose=0)
|
||||
assert(loss < 0.8)
|
||||
|
||||
@@ -102,12 +176,19 @@ def test_sequential():
|
||||
model.predict_proba(X_test, verbose=0)
|
||||
model.get_config(verbose=0)
|
||||
|
||||
fname = 'test_sequential_temp.h5'
|
||||
fname = 'test_nested_sequential_temp.h5'
|
||||
model.save_weights(fname, overwrite=True)
|
||||
|
||||
inner = Sequential()
|
||||
inner.add(Dense(nb_hidden, input_shape=(input_dim,)))
|
||||
inner.add(Activation('relu'))
|
||||
inner.add(Dense(nb_class))
|
||||
|
||||
middle = Sequential()
|
||||
middle.add(inner)
|
||||
|
||||
model = Sequential()
|
||||
model.add(Dense(nb_hidden, input_shape=(input_dim,)))
|
||||
model.add(Activation('relu'))
|
||||
model.add(Dense(nb_class))
|
||||
model.add(middle)
|
||||
model.add(Activation('softmax'))
|
||||
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
|
||||
model.load_weights(fname)
|
||||
@@ -430,7 +511,7 @@ def test_lambda():
|
||||
g = Graph()
|
||||
g.add_input(name='input_a', input_shape=(2,))
|
||||
g.add_input(name='input_b', input_shape=(2,))
|
||||
g.add_node(Lambda(difference),
|
||||
g.add_node(Lambda(difference, output_shape=(2,)),
|
||||
inputs=['input_a', 'input_b'],
|
||||
merge_mode='join',
|
||||
name='d')
|
||||
@@ -582,384 +663,5 @@ def test_siamese_2():
|
||||
assert(loss == nloss)
|
||||
|
||||
|
||||
###############
|
||||
# GRAPH TEST #
|
||||
###############
|
||||
|
||||
(X_train_graph, y_train_graph), (X_test_graph, y_test_graph) = get_test_data(nb_train=1000,
|
||||
nb_test=200,
|
||||
input_shape=(32,),
|
||||
classification=False,
|
||||
output_shape=(4,))
|
||||
(X2_train_graph, y2_train_graph), (X2_test_graph, y2_test_graph) = get_test_data(nb_train=1000,
|
||||
nb_test=200,
|
||||
input_shape=(32,),
|
||||
classification=False,
|
||||
output_shape=(1,))
|
||||
|
||||
|
||||
def test_graph_fit_generator():
|
||||
def data_generator_graph(train):
|
||||
while 1:
|
||||
if train:
|
||||
yield {'input1': X_train_graph, 'output1': y_train_graph}
|
||||
else:
|
||||
yield {'input1': X_test_graph, 'output1': y_test_graph}
|
||||
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(4), name='dense3', input='dense1')
|
||||
|
||||
graph.add_output(name='output1',
|
||||
inputs=['dense2', 'dense3'],
|
||||
merge_mode='sum')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit_generator(data_generator_graph(True), 1000, nb_epoch=4)
|
||||
graph.fit_generator(data_generator_graph(True), 1000, nb_epoch=4)
|
||||
graph.fit_generator(data_generator_graph(True), 1000, nb_epoch=4, validation_data={'input1': X_test_graph, 'output1': y_test_graph})
|
||||
graph.fit_generator(data_generator_graph(True), 1000, nb_epoch=4, validation_data={'input1': X_test_graph, 'output1': y_test_graph})
|
||||
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph}, verbose=0)
|
||||
assert(loss < 3.)
|
||||
|
||||
|
||||
def test_1o_1i():
|
||||
# test a non-sequential graph with 1 input and 1 output
|
||||
np.random.seed(1337)
|
||||
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(4), name='dense3', input='dense1')
|
||||
|
||||
graph.add_output(name='output1',
|
||||
inputs=['dense2', 'dense3'],
|
||||
merge_mode='sum')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph}, verbose=0)
|
||||
assert(loss < 2.5)
|
||||
|
||||
# test validation split
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph},
|
||||
validation_split=0.2, nb_epoch=1)
|
||||
# test validation data
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph},
|
||||
validation_data={'input1': X_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=1)
|
||||
|
||||
|
||||
def test_1o_1i_2():
|
||||
# test a more complex non-sequential graph with 1 input and 1 output
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2-0', input='input1')
|
||||
graph.add_node(Activation('relu'), name='dense2', input='dense2-0')
|
||||
|
||||
graph.add_node(Dense(16), name='dense3', input='dense2')
|
||||
graph.add_node(Dense(4), name='dense4', inputs=['dense1', 'dense3'],
|
||||
merge_mode='sum')
|
||||
|
||||
graph.add_output(name='output1', inputs=['dense2', 'dense4'],
|
||||
merge_mode='sum')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_train_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
assert(loss < 2.5)
|
||||
|
||||
graph.get_config(verbose=1)
|
||||
graph.summary()
|
||||
|
||||
|
||||
def test_1o_2i():
|
||||
# test a non-sequential graph with 2 inputs and 1 output
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_input(name='input2', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input2')
|
||||
graph.add_node(Dense(4), name='dense3', input='dense1')
|
||||
|
||||
graph.add_output(name='output1', inputs=['dense2', 'dense3'],
|
||||
merge_mode='sum')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'input2': X2_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph, 'input2': X2_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
assert(loss < 3.0)
|
||||
|
||||
graph.get_config(verbose=1)
|
||||
|
||||
|
||||
def test_siamese_3():
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_input(name='input2', input_shape=(32,))
|
||||
|
||||
graph.add_shared_node(Dense(16), name='shared', inputs=['input1', 'input2'], merge_mode='sum')
|
||||
graph.add_node(Dense(4), name='dense1', input='shared')
|
||||
graph.add_node(Dense(4), name='dense2', input='dense1')
|
||||
|
||||
graph.add_output(name='output1', input='dense2')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'input2': X2_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph, 'input2': X2_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
assert(loss < 3.0)
|
||||
|
||||
graph.get_config(verbose=1)
|
||||
|
||||
|
||||
def test_siamese_4():
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_input(name='input2', input_shape=(32,))
|
||||
|
||||
graph.add_shared_node(Dense(16), name='shared1', inputs=['input1', 'input2'])
|
||||
graph.add_shared_node(Dense(4), name='shared2', inputs=['shared1'])
|
||||
graph.add_shared_node(Dense(4), name='shared3', inputs=['shared2'], merge_mode='sum')
|
||||
graph.add_node(Dense(4), name='dense', input='shared3')
|
||||
|
||||
graph.add_output(name='output1', input='dense',
|
||||
merge_mode='sum')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'input2': X2_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph, 'input2': X2_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
assert(loss < 3.0)
|
||||
|
||||
graph.get_config(verbose=1)
|
||||
|
||||
|
||||
def test_siamese_5():
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_input(name='input2', input_shape=(32,))
|
||||
|
||||
graph.add_shared_node(Dense(16), name='shared1', inputs=['input1', 'input2'])
|
||||
graph.add_shared_node(Dense(4), name='shared2', inputs=['shared1'])
|
||||
graph.add_shared_node(Dense(4), name='shared3', inputs=['shared2'], outputs=['shared_output1','shared_output2'])
|
||||
graph.add_node(Dense(4), name='dense1', input='shared_output1')
|
||||
graph.add_node(Dense(4), name='dense2', input='shared_output2')
|
||||
|
||||
graph.add_output(name='output1', inputs=['dense1', 'dense2'],
|
||||
merge_mode='sum')
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'input2': X2_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph, 'input2': X2_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'input2': X2_test_graph, 'output1': y_test_graph})
|
||||
assert(loss < 3.0)
|
||||
|
||||
graph.get_config(verbose=1)
|
||||
|
||||
|
||||
def test_2o_1i_weights():
|
||||
# test a non-sequential graph with 1 input and 2 outputs
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(1), name='dense3', input='dense1')
|
||||
|
||||
graph.add_output(name='output1', input='dense2')
|
||||
graph.add_output(name='output2', input='dense3')
|
||||
graph.compile('rmsprop', {'output1': 'mse', 'output2': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph, 'output2': y2_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 2)
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'output1': y_test_graph, 'output2': y2_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'output1': y_test_graph, 'output2': y2_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph, 'output2': y2_test_graph})
|
||||
assert(loss < 4.)
|
||||
|
||||
# test weight saving
|
||||
fname = 'test_2o_1i_weights_temp.h5'
|
||||
graph.save_weights(fname, overwrite=True)
|
||||
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(1), name='dense3', input='dense1')
|
||||
graph.add_output(name='output1', input='dense2')
|
||||
graph.add_output(name='output2', input='dense3')
|
||||
graph.compile('rmsprop', {'output1': 'mse', 'output2': 'mse'})
|
||||
graph.load_weights('test_2o_1i_weights_temp.h5')
|
||||
os.remove(fname)
|
||||
|
||||
nloss = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph, 'output2': y2_test_graph})
|
||||
assert(loss == nloss)
|
||||
|
||||
|
||||
def test_2o_1i_sample_weights():
|
||||
# test a non-sequential graph with 1 input and 2 outputs with sample weights
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(1), name='dense3', input='dense1')
|
||||
|
||||
graph.add_output(name='output1', input='dense2')
|
||||
graph.add_output(name='output2', input='dense3')
|
||||
|
||||
weights1 = np.random.uniform(size=y_train_graph.shape[0])
|
||||
weights2 = np.random.uniform(size=y2_train_graph.shape[0])
|
||||
weights1_test = np.random.uniform(size=y_test_graph.shape[0])
|
||||
weights2_test = np.random.uniform(size=y2_test_graph.shape[0])
|
||||
|
||||
graph.compile('rmsprop', {'output1': 'mse', 'output2': 'mse'})
|
||||
|
||||
graph.fit({'input1': X_train_graph, 'output1': y_train_graph, 'output2': y2_train_graph},
|
||||
nb_epoch=10,
|
||||
sample_weight={'output1': weights1, 'output2': weights2})
|
||||
out = graph.predict({'input1': X_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 2)
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'output1': y_test_graph, 'output2': y2_test_graph},
|
||||
sample_weight={'output1': weights1_test, 'output2': weights2_test})
|
||||
loss = graph.train_on_batch({'input1': X_train_graph, 'output1': y_train_graph, 'output2': y2_train_graph},
|
||||
sample_weight={'output1': weights1, 'output2': weights2})
|
||||
loss = graph.evaluate({'input1': X_train_graph, 'output1': y_train_graph, 'output2': y2_train_graph},
|
||||
sample_weight={'output1': weights1, 'output2': weights2})
|
||||
|
||||
|
||||
def test_recursive():
|
||||
# test layer-like API
|
||||
|
||||
graph = containers.Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(4), name='dense3', input='dense1')
|
||||
graph.add_output(name='output1', inputs=['dense2', 'dense3'],
|
||||
merge_mode='sum')
|
||||
|
||||
seq = Sequential()
|
||||
seq.add(Dense(32, input_shape=(32,)))
|
||||
seq.add(graph)
|
||||
seq.add(Dense(4))
|
||||
|
||||
seq.compile('rmsprop', 'mse')
|
||||
|
||||
seq.fit(X_train_graph, y_train_graph, batch_size=10, nb_epoch=10)
|
||||
loss = seq.evaluate(X_test_graph, y_test_graph)
|
||||
assert(loss < 2.5)
|
||||
|
||||
loss = seq.evaluate(X_test_graph, y_test_graph, show_accuracy=True)
|
||||
seq.predict(X_test_graph)
|
||||
seq.get_config(verbose=1)
|
||||
|
||||
|
||||
def test_create_output():
|
||||
# test create_output argument
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
|
||||
graph.add_node(Dense(16), name='dense1', input='input1')
|
||||
graph.add_node(Dense(4), name='dense2', input='input1')
|
||||
graph.add_node(Dense(4), name='dense3', input='dense1')
|
||||
graph.add_node(Dense(4), name='output1', inputs=['dense2', 'dense3'],
|
||||
merge_mode='sum', create_output=True)
|
||||
graph.compile('rmsprop', {'output1': 'mse'})
|
||||
|
||||
history = graph.fit({'input1': X_train_graph, 'output1': y_train_graph},
|
||||
nb_epoch=10)
|
||||
out = graph.predict({'input1': X_test_graph})
|
||||
assert(type(out == dict))
|
||||
assert(len(out) == 1)
|
||||
|
||||
loss = graph.test_on_batch({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.train_on_batch({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
loss = graph.evaluate({'input1': X_test_graph, 'output1': y_test_graph})
|
||||
assert(loss < 2.5)
|
||||
|
||||
|
||||
def test_count_params():
|
||||
# test count params
|
||||
|
||||
nb_units = 100
|
||||
nb_classes = 2
|
||||
|
||||
graph = Graph()
|
||||
graph.add_input(name='input1', input_shape=(32,))
|
||||
graph.add_input(name='input2', input_shape=(32,))
|
||||
graph.add_node(Dense(nb_units),
|
||||
name='dense1', input='input1')
|
||||
graph.add_node(Dense(nb_classes),
|
||||
name='dense2', input='input2')
|
||||
graph.add_node(Dense(nb_classes),
|
||||
name='dense3', input='dense1')
|
||||
graph.add_output(name='output', inputs=['dense2', 'dense3'],
|
||||
merge_mode='sum')
|
||||
|
||||
n = 32 * nb_units + nb_units
|
||||
n += 32 * nb_classes + nb_classes
|
||||
n += nb_units * nb_classes + nb_classes
|
||||
|
||||
assert(n == graph.count_params())
|
||||
|
||||
graph.compile('rmsprop', {'output': 'binary_crossentropy'})
|
||||
|
||||
assert(n == graph.count_params())
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
# pytest.main([__file__])
|
||||
test_lambda()
|
||||
pytest.main([__file__])
|
||||
@@ -37,33 +37,85 @@ y_test = np_utils.to_categorical(y_test, nb_classes=nb_class)
|
||||
output_shape=(1,))
|
||||
|
||||
|
||||
@pytest.mark.skipif(K._BACKEND=='tensorflow', reason="currently not working with TensorFlow")
|
||||
def test_keras_classifier():
|
||||
def build_fn_clf(hidden_dims=50):
|
||||
model = Sequential()
|
||||
model.add(Dense(input_dim, input_shape=(input_dim,)))
|
||||
model.add(Activation('relu'))
|
||||
model.add(Dense(hidden_dims))
|
||||
model.add(Activation('relu'))
|
||||
model.add(Dense(nb_class))
|
||||
model.add(Activation('softmax'))
|
||||
|
||||
sklearn_clf = KerasClassifier(model, optimizer=optim, loss=loss,
|
||||
train_batch_size=batch_size,
|
||||
test_batch_size=batch_size,
|
||||
nb_epoch=nb_epoch)
|
||||
sklearn_clf.fit(X_train, y_train)
|
||||
sklearn_clf.score(X_test, y_test)
|
||||
model.compile(optimizer='sgd', loss='categorical_crossentropy',
|
||||
class_mode='binary')
|
||||
return model
|
||||
|
||||
|
||||
@pytest.mark.skipif(K._BACKEND=='tensorflow', reason="currently not working with TensorFlow")
|
||||
def test_keras_regressor():
|
||||
class Class_build_fn_clf(object):
|
||||
def __call__(self, hidden_dims):
|
||||
return build_fn_clf(hidden_dims)
|
||||
|
||||
|
||||
class Inherit_class_build_fn_clf(KerasClassifier):
|
||||
def __call__(self, hidden_dims):
|
||||
return build_fn_clf(hidden_dims)
|
||||
|
||||
|
||||
def build_fn_reg(hidden_dims=50):
|
||||
model = Sequential()
|
||||
model.add(Dense(input_dim, input_shape=(input_dim,)))
|
||||
model.add(Activation('relu'))
|
||||
model.add(Dense(hidden_dims))
|
||||
model.add(Activation('relu'))
|
||||
model.add(Dense(1))
|
||||
model.add(Activation('softmax'))
|
||||
model.add(Activation('linear'))
|
||||
model.compile(optimizer='sgd', loss='mean_absolute_error')
|
||||
return model
|
||||
|
||||
sklearn_regressor = KerasRegressor(model, optimizer=optim, loss=loss,
|
||||
train_batch_size=batch_size,
|
||||
test_batch_size=batch_size,
|
||||
nb_epoch=nb_epoch)
|
||||
sklearn_regressor.fit(X_train_reg, y_train_reg)
|
||||
sklearn_regressor.score(X_test_reg, y_test_reg)
|
||||
|
||||
class Class_build_fn_reg(object):
|
||||
def __call__(self, hidden_dims):
|
||||
return build_fn_reg(hidden_dims)
|
||||
|
||||
|
||||
class Inherit_class_build_fn_reg(KerasRegressor):
|
||||
def __call__(self, hidden_dims):
|
||||
return build_fn_reg(hidden_dims)
|
||||
|
||||
for fn in [build_fn_clf, Class_build_fn_clf(), Inherit_class_build_fn_clf]:
|
||||
if fn is Inherit_class_build_fn_clf:
|
||||
classifier = Inherit_class_build_fn_clf(
|
||||
build_fn=None, hidden_dims=50, batch_size=batch_size, nb_epoch=nb_epoch)
|
||||
else:
|
||||
classifier = KerasClassifier(
|
||||
build_fn=fn, hidden_dims=50, batch_size=batch_size, nb_epoch=nb_epoch)
|
||||
|
||||
classifier.fit(X_train, y_train, batch_size=batch_size, nb_epoch=nb_epoch)
|
||||
score = classifier.score(X_train, y_train, batch_size=batch_size)
|
||||
preds = classifier.predict(X_test, batch_size=batch_size)
|
||||
proba = classifier.predict_proba(X_test, batch_size=batch_size)
|
||||
|
||||
|
||||
for fn in [build_fn_reg, Class_build_fn_reg(), Inherit_class_build_fn_reg]:
|
||||
if fn is Inherit_class_build_fn_reg:
|
||||
regressor = Inherit_class_build_fn_reg(
|
||||
build_fn=None, hidden_dims=50, batch_size=batch_size, nb_epoch=nb_epoch)
|
||||
else:
|
||||
regressor = KerasRegressor(
|
||||
build_fn=fn, hidden_dims=50, batch_size=batch_size, nb_epoch=nb_epoch)
|
||||
|
||||
regressor.fit(X_train_reg, y_train_reg,
|
||||
batch_size=batch_size, nb_epoch=nb_epoch)
|
||||
score = regressor.score(X_train_reg, y_train_reg, batch_size=batch_size)
|
||||
preds = regressor.predict(X_test, batch_size=batch_size)
|
||||
|
||||
|
||||
# Usage of sklearn's grid_search
|
||||
# from sklearn import grid_search
|
||||
# parameters = dict(hidden_dims = [20, 30], batch_size=[64, 128], nb_epoch=[2], verbose=[0])
|
||||
# classifier = Inherit_class_build_fn_clf()
|
||||
# clf = grid_search.GridSearchCV(classifier, parameters)
|
||||
# clf.fit(X_train, y_train)
|
||||
# parameters = dict(hidden_dims = [20, 30], batch_size=[64, 128], nb_epoch=[2], verbose=[0])
|
||||
# regressor = Inherit_class_build_fn_reg()
|
||||
# reg = grid_search.GridSearchCV(regressor, parameters, scoring='mean_squared_error', n_jobs=1, cv=2, verbose=2)
|
||||
# reg.fit(X_train_reg, y_train_reg)
|
||||
|
||||
@@ -15,6 +15,7 @@ def check_layer_output_shape(layer, input_data):
|
||||
|
||||
function = K.function([layer.input], [layer.get_output()])
|
||||
output = function([input_data])[0]
|
||||
|
||||
assert output.shape[1:] == expected_output_shape
|
||||
|
||||
|
||||
@@ -36,6 +37,7 @@ def test_Reshape():
|
||||
layer = Reshape(dims=(2, -1))
|
||||
check_layer_output_shape(layer, input_data)
|
||||
|
||||
|
||||
def test_Permute():
|
||||
layer = Permute(dims=(1, 3, 2))
|
||||
input_data = np.random.random((2, 2, 4, 3))
|
||||
@@ -86,11 +88,11 @@ def test_Convolution1D():
|
||||
|
||||
def test_Convolution2D():
|
||||
for border_mode in ['same', 'valid']:
|
||||
for nb_row, nb_col in [(2, 2), (3, 3)]:
|
||||
for subsample in [(1, 1), (2, 2)]:
|
||||
if (subsample[0] > 1 or subsample[1] > 1) and border_mode == 'same':
|
||||
for nb_row, nb_col in [(3, 3), (4, 4), (3, 4)]:
|
||||
for subsample in [(1, 1), (2, 2), (3, 3)]:
|
||||
if (subsample[0] > nb_row or subsample[1] > nb_col) and border_mode == 'same':
|
||||
continue
|
||||
for input_data_shape in [(2, 1, 3, 3), (2, 1, 4, 4)]:
|
||||
for input_data_shape in [(2, 1, 5, 5), (2, 1, 6, 6)]:
|
||||
layer = Convolution2D(nb_filter=1, nb_row=nb_row,
|
||||
nb_col=nb_row,
|
||||
border_mode=border_mode,
|
||||
@@ -99,7 +101,7 @@ def test_Convolution2D():
|
||||
input_data = np.random.random(input_data_shape)
|
||||
check_layer_output_shape(layer, input_data)
|
||||
|
||||
for input_data_shape in [(2, 3, 3, 1)]:
|
||||
for input_data_shape in [(2, 5, 5, 1)]:
|
||||
layer = Convolution2D(nb_filter=1, nb_row=nb_row,
|
||||
nb_col=nb_row,
|
||||
border_mode=border_mode,
|
||||
|
||||
Referência em uma Nova Issue
Bloquear um usuário